

Du befinner dig säkert ofta i den här situationen: du har ett affärssystem, kanske ett CRM-system, några Excel-filer som skickas via e-post, och samtidigt säger någon till dig att du måste välja mellan datalake och datalager för att kunna ”göra seriös analys”. Då handlar samtalet plötsligt bara om teknik, men det verkliga problemet är ett annat. Behöver du verkligen en ny dataarkitektur, eller behöver du helt enkelt göra de data du redan har läsbara och användbara?
För ett små- och medelstort företag är denna skillnad viktigare än själva terminologin. Ett felaktigt val leder inte bara till tekniska komplikationer. Det leder till utdragna projekt, beroende av konsulter, försenade rapporter och investeringar som har svårt att omsättas i bättre beslut. Att välja att inte göra någonting innebär dock att företaget tvingas navigera på känsla.
Det handlar inte om att lära sig leverantörernas jargong. Det handlar om att förstå vilken lösning som passar din verksamhet, din budget och den kompetens du faktiskt har internt. Här hittar du en praktisk guide till debatten om datalager kontra datalager, sett ur perspektivet för den som måste få ihop kostnader, tillgänglighet och avkastning.
Trycket att ”göra något med data” är idag påtagligt. Mängden data ökar, källorna blir allt fler och cheferna efterfrågar snabbare prognoser, översiktspaneler och varningar. Samtidigt dyker det upp begrepp som verkar tvinga fram ett omedelbart arkitektoniskt beslut.
För många små och medelstora företag ligger dock just här problemet. Man får dem att tro att det första steget är att välja mellan två infrastrukturmodeller, när den verkliga knuten ofta är mycket mer konkret: spridda data, inkonsekventa format, manuella rapporter och ingen som har tid att få ordning på det hela.
Det finns andra frågor som är viktigare. Har du verkligen ett arkitekturproblem? Eller är det snarare ett problem med tillgången till data? Om du väljer fel lösning riskerar du att finansiera ett tekniskt projekt istället för att förbättra kontrollen över verksamheten. Om du inte väljer något alls fortsätter du att fatta beslut utifrån ofullständig information.
Den som driver ett små- eller medelstort företag behöver ingen akademisk föreläsning. Det som behövs är ett enkelt riktmärke för att förstå vad som behövs, vad som inte behövs och var de verkliga kostnaderna döljer sig.
Den mest användbara skillnaden förstås bäst med hjälp av två mycket praktiska bilder.
Ett datalager liknar ett välorganiserat bibliotek. Varje bok kommer in redan katalogiserad, klassificerad och placerad på rätt hylla. När du söker efter information hittar du den snabbt eftersom ordningen redan är fastställd. Ett datalager liknar däremot ett stort lager där lådor av alla slag anländer. Du lägger in ordnade filer, loggar, PDF-filer, bilder, exportfiler från affärssystemet och webbdata. Ordningen lägger du till senare, när du ska analysera dem.
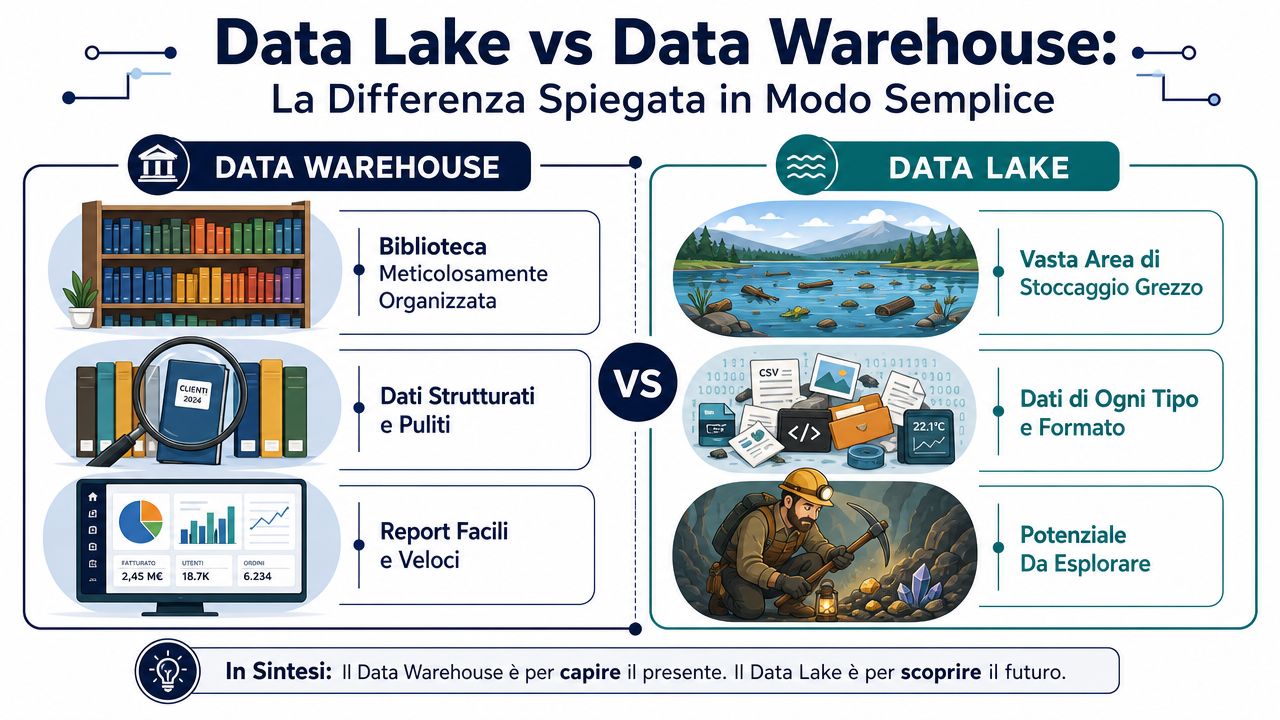
Här kommer den enda tekniska detaljen som verkligen är värd att nämna.
Denna distinktion speglar även deras historiska ursprung. Datavarehuset skapades för företagsanalys av redan rensade och strukturerade data, medan datalagret kom senare för att lagra rådata i olika format. Därför är datavarehuset bättre lämpat för rapportering och nyckeltal, medan datalagret är mer flexibelt för datautforskning och maskininlärning, vilket förklaras i denna analys av skillnaderna mellan datavarehus och datalager.
En datalagring fungerar bra för frågor som redan är kända. En datalake är användbar när du vet att data kan innehålla värde, men ännu inte vet i vilken form.
Om ditt mål är att få insyn i försäljning, vinstmarginaler, order, lager, förseningar, försäljningsresultat och månadsjämförelser, är lagret konceptuellt sett det som bäst motsvarar dina behov. Det ger dig en pålitlig grund för standardrapporter, konsekventa SQL-frågor och reproducerbara siffror.
Om du däremot arbetar med mycket olika typer av data, såsom applikationsloggar, PDF-filer, e-post, text, bilder eller maskinflöden, erbjuder datalagret större frihet. IT-team kan centralisera heterogena datakällor, medan de som arbetar med rapportering fortfarande föredrar strukturerade miljöer för snabba och konsekventa sökningar. I detta sammanhang ingår även det bredare temat datadrivna beslut för företag, som kräver tillgängliga data i ännu högre grad än sofistikerad teknik.
I debatten om data lake kontra datalager blandar många ihop flexibilitet med omedelbar nytta.
En datalagring kan rymma nästan vad som helst. Men att rymma betyder inte att informationen omedelbart blir analysbar. Ett datalager är mindre flexibelt när det gäller inmatning, men mer användbart när man vill ha snabba och standardiserade svar. För ett små- och medelstort företag väger denna skillnad tyngre än teorin. För problemet är inte att lagra mer. Det är att fatta bättre beslut.
Två företag kan utgå från samma data och ändå komma fram till mycket olika resultat. Skillnaden ligger ofta inte i mängden insamlad data, utan i hur de organiserar, bearbetar och gör den tillgänglig för beslutsfattarna.
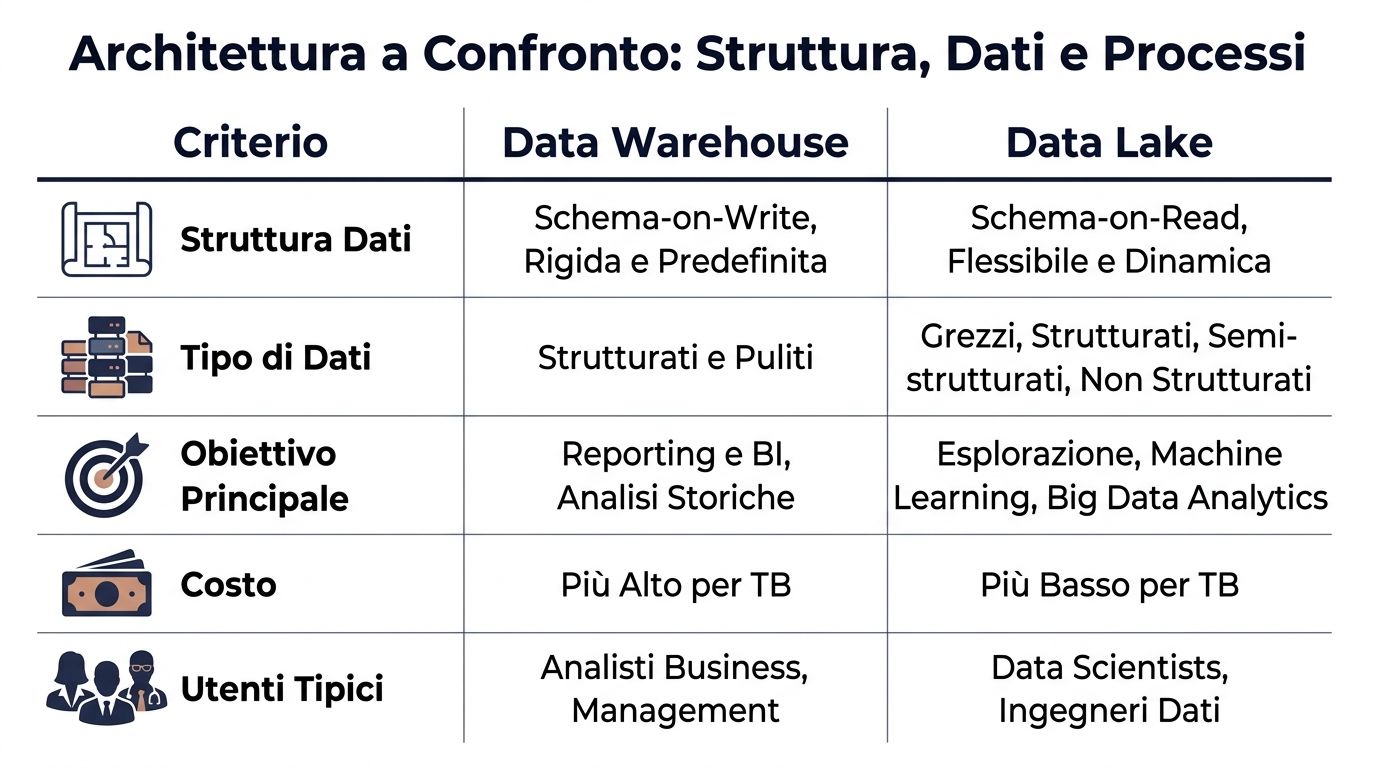
| Kriterium | Datavarehus | Datalager |
|---|---|---|
| Datastruktur | Schema-on-write, definierat före inläsningen | Schema-on-read, definieras vid analysen |
| Datatyp | Framför allt välorganiserade och snygga | Strukturerade, halvstrukturerade och ostrukturerade |
| Typisk process | ETL: bearbeta först, ladda sedan | ELT: ladda först och omvandla sedan |
| Typiska användare | Affärsanalytiker, ekonomi, ledning | Datatekniker, datavetare, tekniska team |
| Förväntade prestationer | Mer förutsägbara för BI och rapportering | Fler variabler, beroende på sökfrågor och förberedelser |
I ett datalager är den klassiska processen ETL: man extraherar data, bearbetar dem och laddar sedan in dem. Det kräver mer arbete i början, men minskar friktionen senare. Den som tittar på en översiktspanel möts av enhetliga fält, fasta definitioner och nyckeltal vars betydelse inte varierar mellan olika avdelningar.
I ett datalager sker flödet ofta enligt ELT-modellen: man extraherar, laddar upp och omvandlar först senare, om det behövs. Denna metod ger större teknisk frihet, men skjuter upp en del av arbetet. För ett litet eller medelstort företag innebär uppskjutandet ofta att arbetsuppgifter hopar sig, vilket sedan drabbar teamet vid den värsta möjliga tidpunkten – nämligen när ett snabbt svar behövs.
En praktisk regel: om flera personer ska läsa samma dokument och fatta operativa beslut, minskar den struktur som fastställts före inläsningen risken för fel, onödiga diskussioner och tidsspill.
Ur ett operativt perspektiv är ett datalager utformat för återkommande sökningar, frekventa rapporter och dagliga instrumentpaneler. Ett datalager hanterar stora datamängder och olika format väl, men svarstiderna och användarvänligheten beror i hög grad på hur data har katalogiserats, förberetts och styrts. En teknisk jämförelse publicerad av CloudOptimo sammanfattar detta väl: datalagret satsar på förutsägbarhet, medan datalagret satsar på flexibilitet.
För ett små- och medelstort företag är detta ingen teoretisk fråga. När försäljningschefen öppnar morgonrapporten vill han ha tillförlitliga siffror och snabba svar. Om det tekniska teamet däremot ska analysera filer, loggar eller olika typer av dokument kan de acceptera en viss fördröjning i utbyte mot en mer omfattande datainsamling.
Den praktiska skillnaden är inte bara av teknisk natur. Det handlar om vem som klarar av att använda uppgifterna utan att behöva be om hjälp varje gång.
Ett välstrukturerat datalager gör data mer tillgängliga för verksamheten. En datalake, i sig själv, gör dem oftast mer tillgängliga för det tekniska teamet. Därför upptäcker många små och medelstora företag först sent ett obekvämt faktum: det verkliga valet står inte mellan två olika tekniker, utan mellan ett system som gör data tillgängliga och ett som lagrar dem utan att omvandla dem till bättre beslut.
Den som utvärderar dessa alternativ inom ramen för ett IT-moderniseringsprojekt bör inte bara ta hänsyn till datalagret utan även till driftsmodellen. Molnlösningar för små och medelstora företag hjälper till att klargöra just detta: var infrastrukturen slutar och var kostnaderna, kompetenskraven och det dagliga ansvaret tar vid.
Ett datalager framställs ofta som det mest kostnadseffektiva alternativet eftersom det lagrar rådata och minskar arbetsinsatsen i början. Det stämmer bara delvis. Om det saknas katalog, åtkomstregler, enhetlig namngivning och minimala kvalitetskontroller förvandlas den initiala besparingen till tid som går åt till att söka efter filer, rekonstruera definitioner och kontrollera vilka data som är tillförlitliga.
Därför är den rätta jämförelsen i många små och medelstora företag inte en abstrakt jämförelse mellan ”data lake” och ”data warehouse”. Den relevanta frågan är en annan: är det verkligen nödvändigt att bygga upp en sådan komplett arkitektur, eller är det bättre att börja med en enklare lösning som ger snabba insikter utan att man direkt belastar sig med all komplexitet?
För ett små- och medelstort företag uppstår det dyraste misstaget ofta ur en felaktigt formulerad fråga: ”Är det billigare med en datalagring eller ett datalager?”. I företaget kommer den verkliga kostnaden först senare. Den uppstår när data inte är kompatibla, rapporterna slutar fungera vid varje byte av affärssystem och varje förfrågan går via konsulter eller utvecklare istället för det team som ska fatta beslutet.

Lagringen väger mindre än man skulle tro. Det är de aktiviteter som gör data tillförlitliga och användbara som väger tyngst: modellering, integrationer, behörigheter, kvalitet, övervakning, felkorrigering och användarsupport.
Ett datalager kräver en del arbete i början. Man måste definiera nyckeltal, bygga upp dataströmmar, samordna källorna och se till att allt hålls i ordning när ERP- eller CRM-systemen byts ut eller affärsreglerna ändras. I gengäld får ledningen tillgång till mer stabila siffror och rapporteringen blir oftast mer förutsägbar.
En datalagring lanseras ofta med ett mer lågt ställt löfte. Man laddar upp data av olika slag och skjuter upp en del av de strukturella besluten. Problemet är att uppskjutandet inte eliminerar arbetet. Det flyttar bara fram det till ett senare skede, där det tar sig uttryck i form av katalogisering, säkerhet, beräkningskostnader, dubbletter, inkonsekventa versioner och ständiga kontroller av vilka data som verkligen är tillförlitliga.
Risken för ett små- och medelstort företag är att man får betala två gånger. Först för att samla in uppgifterna. Sedan för att äntligen göra dem läsbara.
Den verkliga komplexiteten är inte teknisk. Den är operativ.
Om varje ny rapport kräver manuellt arbete, om ekonomichefen och säljaren använder olika definitioner av samma nyckeltal, om företagaren måste vänta i flera dagar på tillförlitliga siffror, så tär redan dataprojektet på marginalen. Även om infrastrukturen på papperet verkar modern.
Därför är det viktigt att även utvärdera driftsmodellen, inte bara arkitekturen. Molnlösningar för små och medelstora företag hjälper just till att förstå denna skillnad: vad du egentligen köper, hur mycket underhåll som sköts internt och i vilken utsträckning du är beroende av specialistkompetens varje månad.
På den italienska marknaden söker de som investerar i analysverktyg konkreta resultat. Minskad manuell arbetsinsats. Snabbare avslut. Bättre kontroll över försäljning, marginaler, lager och kassaflöde. Inte en sofistikerad plattform som endast är tillgänglig för ett fåtal.
Detta förändrar urvalskriterierna. Ett små- och medelstort företag bör inte fundera över vilken arkitektur som är mest tilltalande eller flexibel i teorin. Istället bör man fråga sig hur lång tid det tar att ta fram tillförlitliga instrumentpaneler, hur många personer som krävs för att underhålla dem och hur snabbt projektet ger avkastning.
Inom detaljhandeln blir de dolda kostnaderna snart uppenbara. Om försäljning, returer, kampanjer och lageruppgifter hämtas från olika system räcker det med en felaktig definition av ”marginal” eller ”nettoförsäljning” för att förtroendet för rapporterna ska försvinna. Då är problemet inte vilken databas man valt. Problemet är att ägaren återgår till att fatta beslut i Excel.
Inom finansvärlden blir kostnaden för fel ännu tydligare. Rapportering, bokslut, styrning och avvikelseanalys kräver konsekventa och spårbara data. Om varje granskning leder till diskussioner om siffrornas ursprung, förlorar projektet sin avkastning redan innan det är avslutat.
Därför behöver många små och medelstora företag i praktiken inte bygga upp en datalake eller ett komplett datalager från grunden. De behöver ett mer smidigt, hanterbart och beslutsinriktat system.
Om du inte lyckas upprätthålla datakvaliteten, åtkomstreglerna och de gemensamma definitionerna över tid, är problemet inte valet mellan datalake och datalager. Problemet är att man har införskaffat komplexitet innan man har ett användningsfall som motiverar det.
Den rätta frågan är inte vilken arkitektur som är ”bäst” i absolut mening. Frågan är vilket problem du måste lösa i morgon bitti.

Inom detaljhandeln fungerar lagret bra när man alltid måste besvara samma operativa frågor:
Detsamma gäller inom finansområdet. Om du behöver konsolidera strukturerade data, skapa regelbundna rapporter, analysera portföljer eller tolka ekonomiska trender utifrån fasta kriterier, är ett datalager fortfarande ett självklart val.
Lake är ett bra val när ditt företag samlar in mycket varierande data och du varken vill eller kan definiera allt i förväg.
Ett realistiskt exempel är ett energiföretag som sammanställer:
I ett sådant sammanhang tvingar ett traditionellt datalager dig att först utforma relationerna mellan datakällor som du kanske ännu inte känner till så väl. Med ett datalager kan du samla allt på ett ställe och skapa struktur först när det behövs för en specifik analys. Det är i just sådana situationer som datalagrets flexibilitet verkligen skapar mervärde.
Ett datalager är inte ett ”modernare” alternativ. Det är ett klokt val endast när datamångfalden motiverar den komplexitet som det medför.
De flesta små och medelstora företag befinner sig inte i den situationen. De har främst data från ERP-system, CRM-system, e-handel, bokföring samt CSV- och Excel-exporter. I dessa fall handlar problemet inte om att hantera videofiler, applikationsloggar eller fritext i stor skala. Problemet är istället att få fram rena, konsekventa siffror som är begripliga även för personer utan teknisk bakgrund.
Här måste man säga det rakt ut: ofta behövs varken ett datalager eller ett traditionellt datalager.
Det krävs snarare:
Lakehouse försöker förena de två världarna. Det lovar flexibiliteten hos en lake och vissa av fördelarna med ett warehouse i samma miljö. Det är en intressant inriktning, särskilt för företag med blandade arbetsbelastningar inom BI, AI och datavetenskap.
För ett små- och medelstort företag kvarstår dock samma fråga: har du verkligen ett problem som kräver allt detta? Om ditt behov är att bättre kunna analysera försäljning, marginaler, kassaflöde eller prognoser, kan en sofistikerad hybridlösning fortfarande vara för kostsam i förhållande till det förväntade värdet.
Data lakehouse har skapats för att övervinna den strikta uppdelningen mellan data lake och data warehouse. Idén är enkel: att behålla flexibiliteten hos ett stort och öppet lagringssystem, men samtidigt tillföra ordning, prestanda och analysfunktioner som ligger närmare dem hos ett data warehouse. Tekniker som Databricks och Delta Lake är bra exempel på denna utveckling.
I teorin är det mycket lockande. Man använder samma databas för BI, avancerad analys och maskininlärning, vilket gör att man slipper dubbelarbete med information mellan olika system. För stora organisationer eller erfarna datateam är det en logisk lösning på ett ekosystem som har blivit allt mer komplicerat med tiden.
I akademiska jämförelser utvärderas data lakehouse-arkitekturen utifrån mått som genomströmning, latens och metadataöverhead. Detta visar att jämförelsen med datalagret inte bara gäller funktionalitet utan även prestanda, i scenarier där små prestandaskillnader har stor betydelse, vilket framgår av denna akademiska presentation om jämförelser av lakehouse-arkitekturer.
I företagssammanhang innebär detta att Lakehouse löser problem för organisationer som redan har nått en viss nivå av skala, komplexitet och specialisering.
Om du inte egentligen behövde vare sig ett datalager eller ett datalager, behöver du knappast ett system som kombinerar båda.
För de flesta små och medelstora företag är den mest användbara frågan inte ”vilken arkitektur ska jag välja?”, utan ”hur får jag tillförlitliga analyser utan att förvandla dataprojektet till en evig byggarbetsplats?”.
Detta är den tredje aspekten som ofta saknas i jämförelser mellan datalager och datalager. Bygg inte upp en ny, proprietär infrastruktur. Lägg istället till ett analyslager ovanpå de system du redan använder, och flytta därmed den tekniska komplexiteten utanför företagets operativa ramar.

I praktiken är detta den bästa metoden:
Jag har sett flera små och medelstora företag lägga månader på att bygga upp ett traditionellt lager och sedan knappt använda det alls. Inte för att det var dåligt uppbyggt, utan för att ingen på företaget kunde söka i det på egen hand. Flaskhalsen var inte databasen, utan tillgängligheten.
Det här är en aspekt som ofta underskattas. En elegant arkitektur som alltid kräver en teknisk mellanhand minskar datauppgifternas praktiska värde. En enklare lösning, som ledningen kan förstå, leder ofta till bättre beslut på kortare tid.
Därför får många företag större nytta av en väl utformad Business Intelligence-lösning för små och medelstora företag än av ett överdimensionerat infrastrukturprogram. Det de eftersträvar är inte att äga ett datalager, utan att förstå verksamheten bättre och snabbare.
Rätt infrastruktur är den som ditt team kan använda, underhålla och omsätta i beslut. Inte den som ser imponerande ut på en teknisk bild.
Debatten om data lake kontra data warehouse är värdefull, men för ett små- och medelstort företag utgår den ofta från fel fråga. Innan du väljer en arkitektur måste du ta reda på om du verkligen har ett problem med datamängd och datavariation, eller om det handlar om ett mycket vanligare problem: utspridda data, manuella rapporter och dålig tillgänglighet.
Datawarehouse är fortfarande det bästa valet när man behöver tillförlitlig rapportering, konsekventa nyckeltal och förutsägbar prestanda. Datasjön är ett lämpligt val när mångfalden av källor motiverar större flexibilitet och komplexitet. Lakehouse är en intressant utveckling, men det är sällan det rätta första steget för ett företag som framför allt eftersträvar operativ kontroll och avkastning på investeringen.
Det smartaste valet är inte den mest avancerade tekniken. Det är den lösning som står i proportion till det faktiska problemet, den kompetens som finns tillgänglig och den hastighet med vilken du vill omvandla data till beslut.
Om du vill omvandla företagsdata till rapporter, prognoser och operativa insikter utan att behöva bygga upp en komplex infrastruktur, ska du ta en titt på ELECTE – en AI-driven dataanalysplattform för små och medelstora företag. Du kan utgå från de data du redan har, minska det manuella arbetet och göra analysverktyg tillgängliga för hela teamet med ett betydligt smidigare tillvägagångssätt.

.svg)
.svg)
.svg)






