

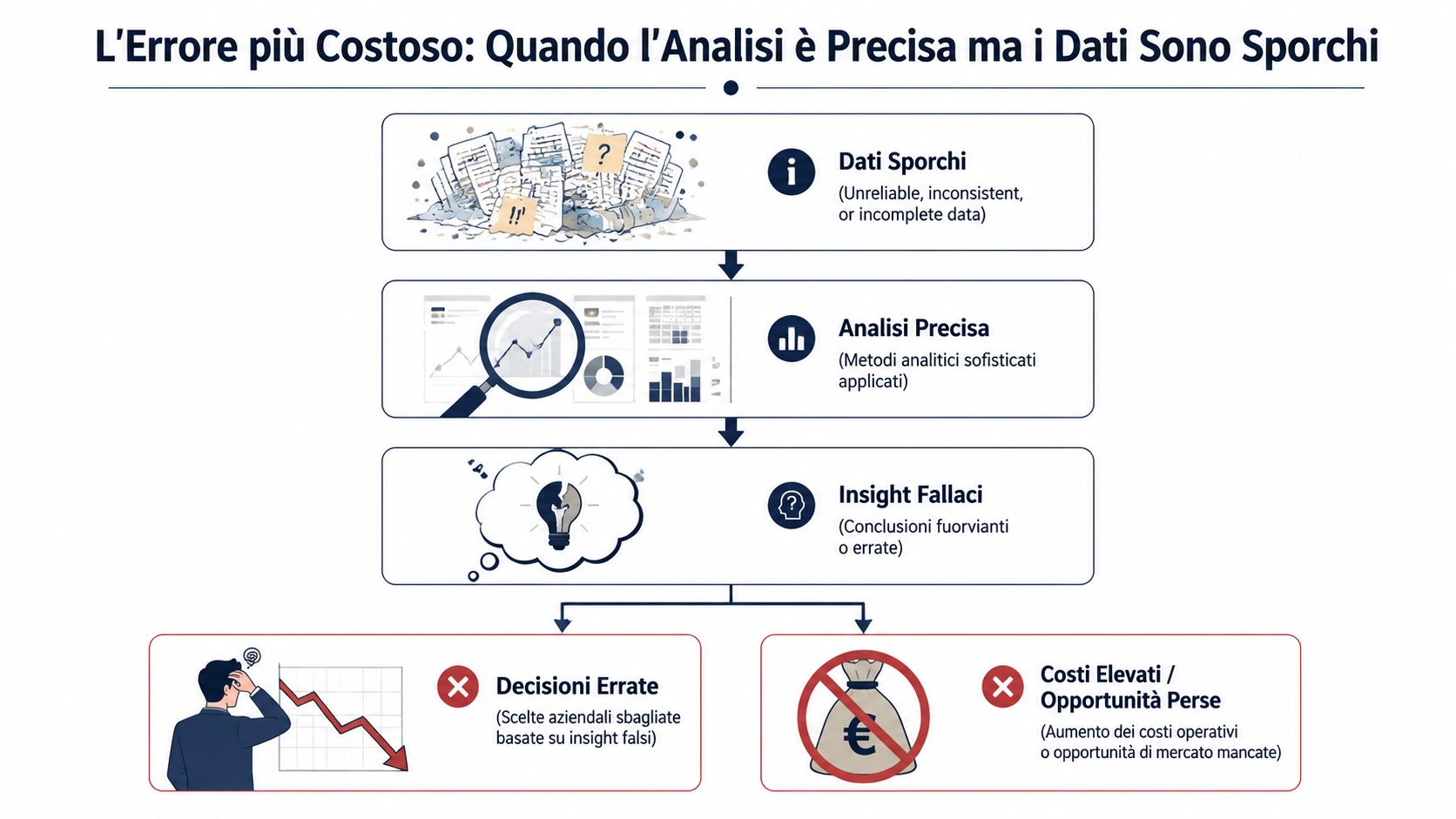
Titta på månadens försäljningsrapport. Intäkterna verkar ha ökat, marginalen verkar ha förbättrats, men ändå finns det en obehaglig känsla av att något inte stämmer. Det är inte paranoia. Det är operativ erfarenhet. Den som arbetar i ett italienskt små- och medelstort företag vet att uppgifterna, mellan affärssystemet, Excel-exporter och manuella ändringar, förändras flera gånger innan de hamnar på en översiktssida.
Saken är enkel: en felfri analys baserad på felaktiga data hjälper dig inte. Den vilseleder dig. Den ger dig ett precist, elegant och betryggande svar, men som vilar på bräckliga grunder. Och det är mycket farligare än en ofullständig rapport, eftersom den får dig att fatta beslut med självförtroende när det egentligen inte finns något självförtroende att hämta.
Tekniker för datavalidering tjänar just detta syfte: att lyfta fram dolda fel. De gör inte data ”perfekta”. De synliggör de problem som idag passerar obemärkt förbi. Oavsett om du arbetar med administration, styrning, försäljning eller drift är det detta arbete som skiljer ett användbart tal från ett rent dekorativt tal. Och inom små och medelstora företag är detta värdefullare än många ”avancerade” analysinitiativ, eftersom fördelarna märks omedelbart, ofta redan vid den första importen.
I små och medelstora företag skapas siffrorna sällan där de läses. De överförs från ett affärssystem till en exporterad fil, sedan till Excel och därefter till en ”bearbetad” version av någon som egentligen bara skulle korrigera två kolumner men som till slut skrev om halva arket. När den slutliga rapporten inte övertygar är problemet ofta inte diagrammet. Det är allt som har hänt innan.
Datavalidering är det minst lockande men viktigaste inslaget i hela analyscykeln. Ingen företagare vill diskutera formatkontroller eller saknade obligatoriska fält. Men nästan varje felaktigt beslut som fattas utifrån till synes felfria dashboards har sitt ursprung just där: i ett ändrat decimalseparatortecken, ett felaktigt tolkat datum, en dubblett i registret eller en summa som inte stämmer men som ingen har kontrollerat.
Den som arbetar bra med data utvecklar en bestämd vana: innan man undrar vad siffrorna säger, frågar man sig om siffrorna är tillförlitliga. De bästa metoderna för datavalidering är inte de mest sofistikerade. Det är de som tidigt upptäcker de vanligaste felen, utan att bromsa det dagliga arbetet.
Om du inte litar tillräckligt på uppgifterna för att fatta ett viktigt beslut, är problemet inte beslutet i sig. Det är valideringen.
Det typiska felet är inte en rapport som uppenbart är felaktig. Det är en välordnad rapport, som till synes är sammanhängande, men som bygger på data som redan har förlorat sin tillförlitlighet. När detta händer ligger skadan inte bara i det felaktiga talet. Den ligger i det faktum att ingen ifrågasätter det.
Området har utvecklats avsevärt. Datavalideringen har gått från att huvudsakligen vara en manuell kontroll till automatiserade och statistiska kontroller. Enligt bästa praxis finns det minst fem grundläggande kontroller: datatypskontroll, kodkontroll, intervallkontroll, formatkontroll och konsistenskontroll, vilket sammanfattas av Teradata i översikten över datavalidering. I Italien är denna utveckling ännu viktigare inom reglerade sammanhang, där även ett enda felaktigt fält kan påverka rapporter, prognosmodeller eller efterlevnad av lagkrav.
Det första misstaget är att nöja sig med det ytliga. Många företag gör bara den enklaste kontrollen, nämligen den syntaktiska.
Ett korrekt angivet skattenummer kan klara det första hindret men misslyckas med det andra. Ett fakturabelopp kan vara ett tal och ha rätt format, men om det inte stämmer överens med summan av raderna har du ett mycket allvarligare problem än bara formatet.
Praktisk regel: En kontroll som endast granskar en kolumn upptäcker triviala fel. En kontroll som sammanför flera fält upptäcker de fel som påverkar besluten.
En meningsfull validering sker inte först i slutet av arbetet. Den sker tidigare. Om du väntar på slutrapporten har felet redan bearbetats, sammanställts, kopierats till andra filer och diskuterats på möten. Vid det laget kostar det uppmärksamhet, tid och trovärdighet att rätta till det.
Detta gäller i ännu högre grad när du börjar använda mer avancerade metoder, såsom avvikelsedetektion eller hantering av statistiska extremvärden. Det är användbara verktyg, men de ersätter inte de grundläggande kontrollerna. Om en kolumn som importerats som text innehåller priser behöver du ingen komplex modell. Du behöver ett enkelt filter som stoppar felet redan vid inmatningen.
En bra analys utgår inte från snyggare instrumentpaneler. Den utgår från data som har genomgått en rad rimliga tester redan när de matas in i flödet.
I små och medelstora företags dagliga verksamhet kommer det mesta av värdet från enkla kontroller. Inte från de mest raffinerade akademiska teknikerna. Inte från sofistikerade processflöden som ingen kommer att underhålla. Utan från tydliga, repeterbara regler som ligger nära den punkt där informationen faktiskt kommer in i företaget.

I det italienska sammanhanget ligger detta tillvägagångssätt i linje med ISTAT:s strategi, som definierar datakvalitet utifrån aspekter som noggrannhet, konsistens och fullständighet och använder VIMO-kontrollen (Valid, Invalid, Missing, Outlier) för att mäta giltiga, saknade och avvikande värden. Tillvägagångssättet innebär validering vid inmatning, under bearbetningen och före den slutliga användningen av uppgifterna, vilket förklaras i ISTAT:s material om datakvalitet och validering.
Den typiska processen är alltid densamma. Uppgiften skapas i affärssystemet. Den exporteras. Den överförs till Excel. Någon korrigerar en rubrik, drar över en formel, kopierar en kolumn, ändrar datumformatet ”för att fixa det”. Från och med då börjar de dolda felen.
Här är de kontroller som bör genomföras omedelbart:
Om du arbetar med manuella exporter kan du börja med en mycket konkret tabell:
| Kontroll | Ett vanligt misstag i små och medelstora företag | En fråga du bör ställa dig själv |
|---|---|---|
| Typ | Pris för sängen som text | Kan denna kolumn beräknas? |
| Format | Blandade datum i olika format | Tolkar systemet den alltid på samma sätt? |
| Intervall | Belopp utanför skalan | Är detta värde rimligt för kunden eller produkten? |
| Unikhet | Kunden har angetts flera gånger | Räknar jag olika personer eller namn som stavas på olika sätt? |
| Fullständighet | Tomma nyckelfält | Kan jag använda den här posten i rapporter och beslut? |
| Konsekvens | Siffror som inte stämmer | Bekräftar kolumnerna varandra? |
För dem som arbetar inom branscher där dokument- och processkvalitet redan spelar en viktig roll i den operativa verksamheten är det värt att även jämföra mer strukturerade metoder för kvalificering och kontroll. En användbar läsning är ”Guiden till kvalificering inom reglerade sektorer”, eftersom den tydligt visar att valideringsarbetet inte bara handlar om ”uppstädning”, utan om processkontroll.
Dubbletter förtjänar ett särskilt omnämnande. De är ett återkommande problem i många små och medelstora företags kundregister och snedvrider nästan allt: aktiva kunder, köpfrekvens, marknadsnärvaro och relationshistorik. Om du vill utgå från ett konkret exempel hittar du en praktisk metod i ELECTE: en komplett guide till dubbletter i Excel.
Avancerade kontroller är bara till nytta när grunderna är på plats. Annars är det som att montera en radar på en bil utan bromsar.
Måndag morgon, säljmöte. Ägaren tittar på försäljningsrapporten, den administrativa chefen tittar på en annan fil och ekonomichefen har en tredje. Siffrorna borde stämma överens. Men det gör de inte.
Det är en vanlig situation i italienska små och medelstora företag. Ett gammalt affärssystem exporterar CSV-filer med fasta fält. CRM-systemet använder andra etiketter. E-handeln har sin egen logik. Sedan kommer Excel in i bilden, och där sätter någon ordning på rubrikerna, kopierar kolumner, rättar datum och försöker få allt att stämma inför mötet.
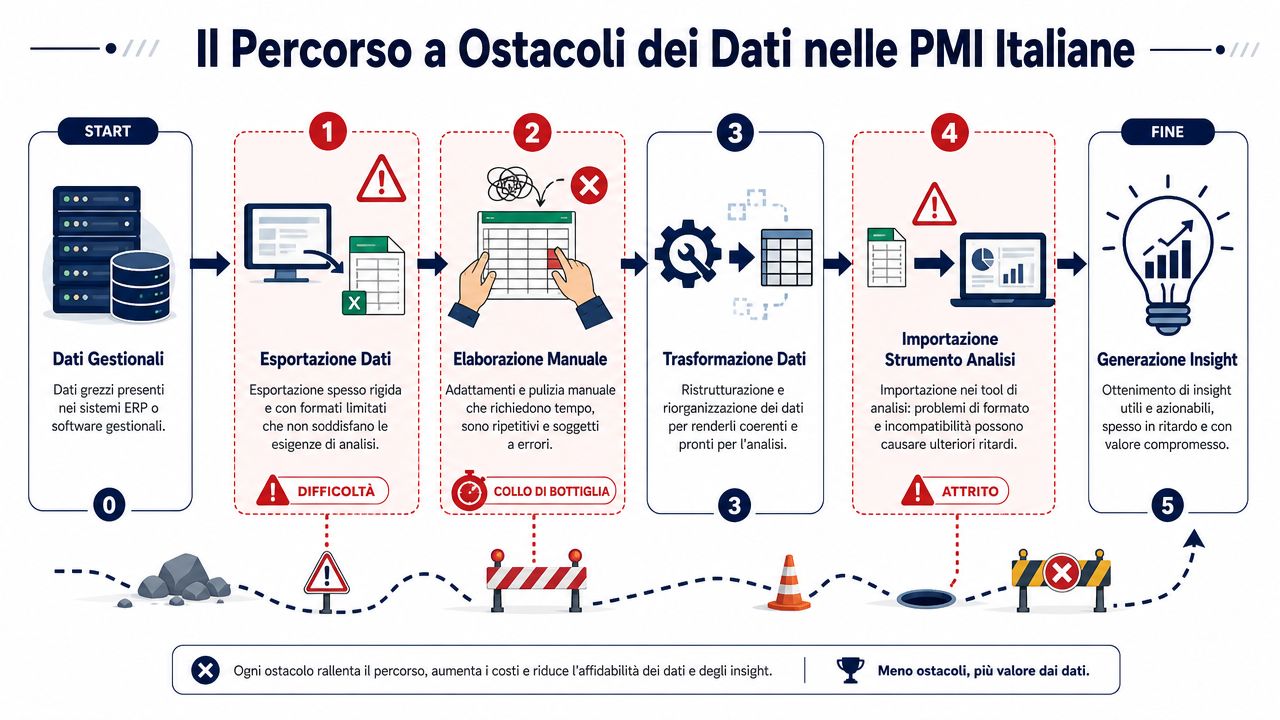
Problemet ligger inte i tekniken i sig. Problemet är summan av alla små manuella steg som krävs för att hantera data som kommer från system som skapats vid olika tidpunkter, ofta utan någon gemensam standard. Den som arbetar med att koppla samman olika datakällor märker det genast: varje källa har sina egna konventioner, återkommande fel och fält som fylls i ”hur det nu blir”.
Även de mest kostsamma felen stoppar inte processen. De läggs in i filen och finns kvar där.
Det händer varje dag i mycket konkreta sammanhang:
Här begår många företag samma misstag. De letar efter sofistikerade lösningar innan de har säkerställt de enkla men lönsamma kontrollåtgärderna: korrekta typer, konsekventa nycklar, bevarade koder och datum som kan läsas på samma sätt av alla system.
I små och medelstora företag är data sällan rena och stabila från början. De skickas vidare mellan administration, försäljning, logistik, externa konsulter och lokala filer med namn som ”report_finale_def_vero.xlsx”. Var och en korrigerar det som behövs för att kunna utföra sitt arbete. Nästan ingen dokumenterar ändringarna.
Därför blir akademiska kontroller eller alltför ambitiösa projekt för avvikelsedetektion ofta försenade. Först måste man ha ordning på grunderna. En automatisk kontroll som upptäcker ogiltiga CAP-koder, avkortade kundkoder, dubbla rader eller datum utanför tidsperioden förhindrar fler fel än många ”avancerade” initiativ som sätts igång för tidigt.
Jag säger det rakt ut eftersom det är det problem jag oftast stöter på: ett små- och medelstort företag tappar inte förtroendet för sina data på grund av brist på artificiell intelligens. Det tappar förtroendet därför att omsättningssiffrorna varierar mellan olika Excel-filer, och ingen vet vilken version som är den rätta.
Den fil som ”alltid har fungerat” är ofta den fil som ingen längre kontrollerar.
När data passerar genom flera händer och flera system behöver valideringen inte vara elegant. Den måste vara repeterbar, tråkig och ske så nära datainmatningen som möjligt. Det är där man får ut största delen av värdet, redan innan man ens börjar tala om prediktiva modeller eller snyggare instrumentpaneler.
Måndagsmorgnar börjar ofta så här. Administrationschefen öppnar två exportfiler för samma månad, en från affärssystemet och en från försäljningsfilen, och summan stämmer inte. Ingen har tid att göra om kontrollerna för hand. Vid det laget är problemet inte rapporten. Det är att förtroendet för siffrorna redan har gått förlorat.
ELECTE ingriper innan felaktiga data hamnar i analyserna. För ett italienskt små- och medelstort företag är det just detta som verkligen spelar roll. Det behövs ingen komplicerad maskin som lovar sofistikerade kontroller om den sedan släpper igenom banala importfel, felaktigt avlästa kolumner eller koder som byter format mellan olika system.
I praktiken granskar plattformen uppgifterna allteftersom de kommer in. Inte efter att rapporten har tagits fram. Inte efter mötet där någon undrar varför marginalen har förändrats mellan olika versioner av filen.
De automatiska kontrollerna täcker de problem som orsakar mer skada än väntat i små och medelstora företag: inkonsekventa datatyper, saknade fält, datum utanför tidsperioden, dubbletter, värden utanför intervallet och nycklar som inte kopplas till rätt tabeller. Det är kanske inte särskilt glamorösa kontroller, men det är just de som förhindrar flest operativa fel i miljöer präglade av Excel-exporter, föråldrade ERP-system och filer som skickas via e-post.
Sedan finns det den kontextuella nivån. Vid onboarding fastställs regler som är förenliga med den faktiska affärsprocessen, inte med en teoretisk modell. Ett distributionsföretag har andra behov än en byrå som hanterar turistbesök eller en tillverkare med differentierade prislistor och rabatter. Detsamma gäller för specifika dokumenthanteringsfall, såsom avläsning av strukturerade data från dokument och incheckningar – ett ämne som även är relevant för dem som arbetar med MRZ för boendeanläggningar.
Den praktiska fördelen är enkel: teamet behöver inte varje gång fundera ut vilka kontroller som ska göras. De finns redan på plats och tillämpas på ett konsekvent och repeterbart sätt.
Ett typiskt exempel. En uppdatering av affärssystemet ändrar formatet på vissa prisfält endast i en del av exportfilen. Vid en första anblick verkar filen vara korrekt. Vid en närmare granskning visar det sig dock att dessa värden påverkar omsättningen, lönsamheten och jämförelserna med tidigare månader. ELECTE upptäcker omedelbart avvikelsen, isolerar de berörda raderna och gör det möjligt att korrigera dem innan de hamnar i dashboards och ledningsrapporter.
En av de mest användbara aspekterna för dem som ska fatta beslut och inte sysslar med datavetenskap är hanteringen av undantag. De problematiska posterna försvinner inte. De förblir synliga, separerade och förklarade.
Den som använder uppgifterna förstår genast:
Denna öppenhet förhindrar en av de värsta vanorna jag ser hos små och medelstora företag: att rensa upp i datauppsättningen utan att lämna några spår och upptäcka flera veckor senare att siffrorna inte längre stämmer.
Just därför är funktionen att koppla samman olika datakällor så värdefull. Det räcker inte att koppla samman CRM, ERP, e-handel och manuella filer. Om data sammanförs utan tydliga kontroller förblir kaoset detsamma – bara på en mer ordnad skärm.
ELECTE lovar inte perfekta data. Det minskar de vanligaste felen, synliggör dem och förhindrar att de hamnar i rapporterna som om de vore korrekta. För ett små- och medelstort företag är det ofta just detta som utgör skillnaden mellan att diskutera siffror och att diskutera om siffrorna.
Validering ska inte betraktas som ett tekniskt projekt som är skilt från verksamheten. Den ska betraktas som en operativ disciplin. Den som upprättar en budget, godkänner en prislista, granskar marginalerna eller planerar inköp använder redan data som är väl eller dåligt validerade. Det finns inget tredje alternativ.
Det finns inte så många användbara regler, men de måste tillämpas konsekvent:
Gäller vid inmatningen, inte nedströms
Om kontrollen når slutet har felet redan påverkat formler, sammanställningar och rapporter.
Nöj dig inte med formatet
. En uppgift kan vara välformulerad men ändå felaktig. Du måste kontrollera rimligheten och samstämmigheten mellan fälten, inte bara att ett schema följs.
Automatisera repetitiva kontroller
Inget administrativt eller säljteam har tid att manuellt dubbelkontrollera varje export. Grundläggande kontroller måste bli systematiska.
Undvik alltför strikta regler
Det finns en verklig avvägning mellan noggrannhet och produktivitet. Alltför strikta regler kan minska användningen av analysverktyg bland icke-tekniska team, vilket Acceldata belyser i sin reflektion över avvägningen vid datavalidering. Den rätta balansen är den som minimerar felen utan att bromsa verksamheten.
Betrakta undantag som signaler, inte som störningar
Ett avvikande resultat säger nästan alltid något om den process som har gett upphov till det. Att ignorera det innebär att man avstår från att förbättra processen i ett tidigare skede.
Ett bra exempel kommer från områden där formatet inte är en detalj utan en förutsättning för att systemet ska fungera. Inom hotell- och logiindustrin, till exempel, visar frågan om automatisk avläsning av dokument tydligt hur viktigt det är att uppgifterna inte bara finns tillgängliga, utan också överensstämmer med en tolkbar standard. Den som vill ha ett konkret exempel kan läsa den här fördjupningsartikeln om MRZ för hotell- och logiindustrin.
Den rätta inställningen är följande: lita på uppgifterna först efter att du har testat dem. Om du idag förlitar dig på filer som ingen kontrollerar på ett strukturerat sätt, så bedriver du inte någon analys. Du hoppas bara.
De flesta problemen i rapporterna uppstår inte i den sista grafen. De uppstår långt tidigare, när ofullständiga, inkonsekventa eller ur sitt sammanhang tagna data matas in i systemen utan någon ordentlig kontroll. Därför är datavalideringstekniker viktigare än man kan tro. Det är där man slutar att låta sig styras av data och börjar styra dem själv.
För ett små- och medelstort företag ligger vinsten inte i att sträva efter perfektion. Den ligger i att bygga upp ett tillräckligt förtroende för att kunna fatta välgrundade beslut. Kontroller av typ, format, intervall, unikhet, fullständighet och korskontroller löser en stor del av de verkliga problemen. Automatiseringen gör dessa kontroller hållbara.
Om du inte har en strukturerad valideringsprocess litar du inte på uppgifterna. Du litar på turen.
Om du vill omvandla oöverskådliga exportfiler, sårbara Excel-filer och heterogena datakällor till tillförlitliga analyser kan du ta reda på hur ELECTE – en AI-driven dataanalysplattform för små och medelstora företag – automatiserar kontroller, identifierar avvikelser och ger insikter utan att öka komplexiteten för ditt team.

.svg)
.svg)
.svg)






