

Du får en XML-fil via PEC. Du öppnar den i webbläsaren, ser en vägg av taggar och tror att problemet är att ”läsa den”. I själva verket är det bara det första hindret. Det verkliga problemet på företaget är ett annat: att förstå om dessa uppgifter är korrekta, konsekventa och redo att användas i dina rapporter.
För många italienska små och medelstora företag är detta inte längre en rent teknisk fråga. Sedan den elektroniska faktureringen blev obligatorisk har XML blivit en del av det dagliga arbetet inom administration, styrning och analys. Det räcker inte att bara visa dokumentet. Man måste kunna skilja mellan en läsbar fil och en tillförlitlig fil. Man måste förstå när en snabb kontroll räcker och när det krävs parsning, validering och normalisering innan data laddas in i Excel, BI-systemet eller en analysplattform.
Om du letar efter en praktisk guide till hur man läser XML-filer är det här rätt väg att gå: börja med de enkla metoderna, ta reda på var det går snett och bygg sedan upp ett flöde som omvandlar rå XML till data som är användbara för verksamheten. Det är så man minskar antalet fel och förkortar tiden mellan ”jag har filen” och ”jag har en användbar insikt”.
En XML-fil organiserar data i en hierarkisk struktur. Det finns ett huvudelement, det finns inbäddade avsnitt och varje block beskriver en uppgift med en specifik betydelse. För den som hanterar administrativa processer är det just denna detalj som avgör skillnaden mellan läsbar data och data som verkligen går att använda.
Det handlar inte om att ”öppna” filen. Det handlar om att ta reda på om den filen kan integreras utan fel i kontroll-, redovisnings- och analysflödena.
Låt oss ta en elektronisk faktura som exempel. I samma fil finns leverantörs- och kunduppgifter, beskattningsbara belopp, moms, artikelrader, betalningsvillkor, orderreferenser och ofta även undantag som gör det svårare att tolka fakturan. I XML-formatet är dessa uppgifter inte placerade under varandra som i ett vanligt dokument. De är placerade på specifika platser, och just den placeringen förklarar vad de representerar.
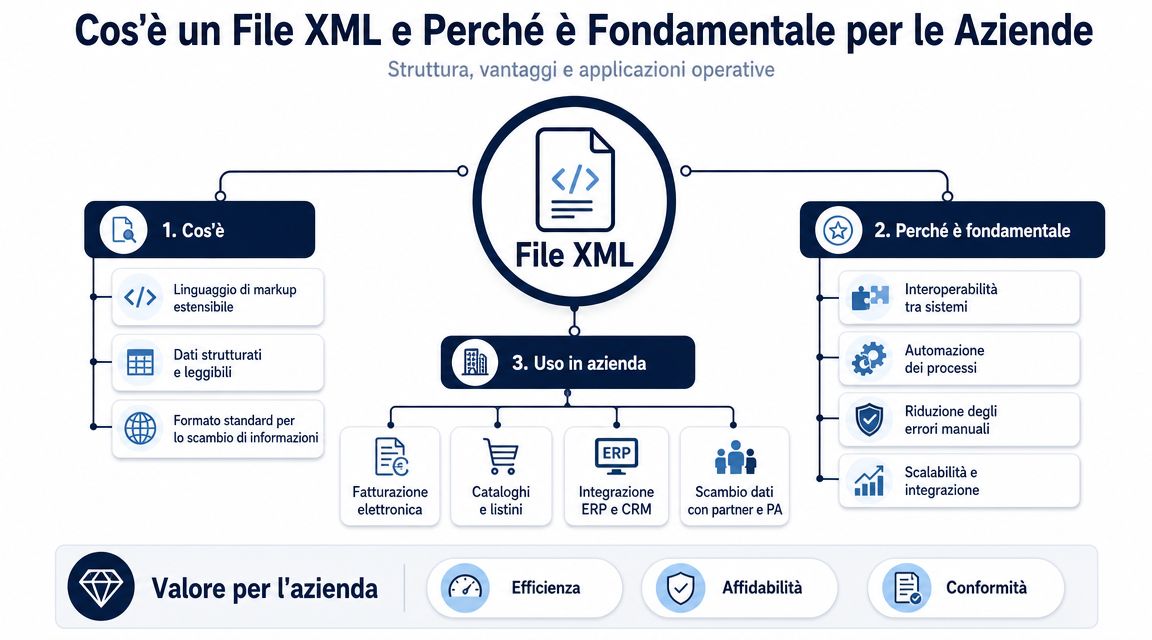
För en chef är den viktiga skillnaden inte mellan taggar och attribut i teoretisk mening. Den ligger mellan isolerade uppgifter och tillförlitliga uppgifter. Att läsa ”1000,00” utan sammanhang är till liten nytta. Att läsa det på rätt ställe i filen gör det möjligt att förstå om det är dokumentets totalsumma, beskattningsunderlaget, skatten eller värdet för en enskild rad.
Här uppstår den första operativa fördelen. XML bevarar datans sammanhang.
En praktisk regel: att läsa en XML-fil ordentligt innebär att man kontrollerar värdets betydelse, inte bara själva värdet.
I Italien har denna fråga blivit aktuell i och med utbredningen av elektronisk fakturering. I FatturaPA-formatet har XML blivit standarden för skattedokumentation. Följaktligen är tolkningen av dessa data inte längre enbart en fråga för IT-avdelningen. Den berör administration, ekonomistyrning, inköp och alla som behöver använda dessa data för att fatta beslut.
I praktiken ser jag alltid samma problem. Filen finns, data finns, men det tar alldeles för lång tid att omvandla den till användbar information. En person öppnar XML-filen, granskar den manuellt, kopierar värden till Excel, korrigerar fält som inte är enhetliga, byter namn på leverantörer som stavats på olika sätt och försöker rekonstruera utgiftskategorier som filen inte presenterar i en form som är redo för analys. Kostnaden är inte bara operativ. Det är förlorad tid fram till insikten.
Med FatturaPA blir risken ännu tydligare. Två formellt korrekta filer kan orsaka samma analysproblem om man använder mycket otydliga radbeskrivningar, om orderreferenserna är ofullständiga eller om leverantörsregistret innehåller olika varianter. I det läget handlar problemet inte om att läsa XML. Problemet är att förhindra att giltiga skattedata blir otillförlitliga förvaltningsdata.
Ett vanligt misstag är att behandla XML som en bilaga som ska visas. Inom företaget fungerar det bättre att betrakta det som en strukturerad datakälla som måste kontrolleras innan den används som underlag för rapporter, instrumentpaneler och utgiftsmodeller. Om detta steg hanteras på fel sätt hamnar ekonomiteamet i en situation där man diskuterar siffror som till synes är exakta, men som bygger på inkonsekventa klassificeringar.
De rätta frågorna i början är följande:
Det är mycket konkreta kontroller. De syftar till att undvika dubbla leverantörer i rapporterna, felaktigt tolkad moms, ofullständigt ifyllda kostnadsställen och långsamma avstämningar i slutet av månaden.
Det är här skillnaden mellan teknisk tolkning och affärsvärde blir tydlig. En parser läser filen. En väl utformad process ger rena, jämförbara och analysklara data. Plattformar som ELECTE har skapats just för att överbrygga denna klyfta och minska det manuella arbete som skiljer den mottagna XML-filen från de insikter som behövs för att fatta bättre beslut.
För snabba kontroller av en enskild fil behövs varken parsare eller bibliotek. Det gäller att förstå om du gör en visuell kontroll av några få fält eller om du redan hanterar data som kommer att hamna i bokföringen, rapporteringen eller ledningskontrollen. Skillnaden är viktig, särskilt när det gäller FatturePA. En kontroll som görs hastigt idag kan imorgon bli en felaktig rad i leverantörsdataseten.

Webbläsare, textredigerare och specialiserade visningsprogram löser ett specifikt problem: att snabbt läsa innehållet utan att behöva konfigurera en teknisk arbetsflöde. För en enskild fil räcker det ofta. Du kan öppna en XML-fil i Chrome, Edge eller Firefox för att se strukturen, eller använda Anteckningar, WordPad eller TextEdit om du vill granska taggarna direkt. När det gäller elektroniska fakturor gör en specialiserad visningsprogramvara rubriker, dokumentrader, beskattningsunderlag och moms lättare att läsa.
Det handlar om följande:
| Verktyg | Användbart för | Huvudsaklig begränsning |
|---|---|---|
| Webbläsare | Snabb visuell kontroll av konstruktionen | Kontrollerar inte överensstämmelsen mellan fält och avsnitt |
| Textredigerare | Direkt kontroll av taggarna | Det blir besvärligt med långa eller hierarkiskt uppbyggda filer |
| Excel | Förhandsgranskning i tabellform | Hanterar hierarkier och upprepningar dåligt |
| Särskild visningsenhet | En tydligare läsning av fakturor och skattedokument | Förbereder inte data för analys eller automatisering |
Om du behöver kontrollera dokumentdatum, momsregistreringsnummer, fakturabelopp eller om det finns bilagor, är dessa verktyg lämpliga.
Om målet däremot är att jämföra leverantörer, klassificera utgifter eller fylla på en översiktssida, så bromsar enbart visningen upp arbetet och lämnar för stort utrymme för manuella fel. Det är den klassiska klyftan mellan att titta på en fil och att i tid få fram tillförlitliga uppgifter.
Att öppna en XML-fil innebär inte att du validerar de data som du kommer att använda i rapporterna.
En annan praktisk aspekt gäller volymen. Tio rader går att kontrollera även manuellt. Hundratals FatturePA-fakturor går inte. I det fallet lönar det sig redan att fundera på ett repeterbart arbetsflöde eller på verktyg som läser av innehållet på ett strukturerat sätt, till exempel via API för att hämta och hantera skattedokument på ett integrerat sätt.
I Italien är det återkommande problemet inte att öppna en .xml, men att förstå vad man ska göra när en .xml.p7m via PEC. Man måste skilja mellan enkla XML-filer och digitalt signerade filer. I det senare fallet krävs verktyg som kan läsa signaturen, extrahera innehållet och visa den korrekta XML-koden, vilket förklaras i Denna guide om XML och XML P7M i PEC.
Här kostar misstag tid:
För en administrativ medarbetare är den mest användbara sekvensen enkel:
Dessa metoder fungerar bra vid den första kontrollnivån. De löser dock inte det verkliga problemet inom företaget: att omvandla skatte-XML-filer, som ofta är oregelbundna eller bristfälligt standardiserade, till rena och jämförbara data utan att förlänga tiden mellan mottagandet av dokumentet och den användbara informationen.
När filerna börjar hopa sig blir det manuella arbetet inte längre hållbart. Vid den punkten är det inte någon elegant lösning att läsa XML-filer med hjälp av kod. Det är det första steget för att undvika repetitiva uppgifter, kopieringsfel och inkonsekventa datamängder.

En gedigen metod för att tolka XML följer alltid samma logik: parsning, normalisering, målinriktad extrahering. I Java- och Android-handledningarna går den korrekta arbetsflödet via parse(), genom normalisering av trädet med doc.getDocumentElement().normalize() och sedan genom återställandet av fälten med getElementsByTagName, en metod som är mer stabil än att bara visa texten i en textredigerare, vilket framgår av denna tekniska handledning om hur man läser XML-data.
Denna sekvens är viktigare än vilket språk du väljer. Om du hoppar över normaliseringen, om du söker efter noder på ett alltför naivt sätt eller om du antar att en tagg alltid förekommer endast en gång, kommer ditt skript att fungera på vissa filer men misslyckas just med de som är viktiga.
För projekt som senare ska samverka med externa system kan det vara användbart att skapa ett reproducerbart och dokumenterat extraktionsflöde. Om du arbetar med applikationsintegrationer är dokumentationen om ELECTEs API:er med verifierad Postman-profil en bra utgångspunkt, framför allt för att förstå hur man kopplar en redan rensad dataset till efterföljande processer.
Nedan följer några enkla exempel. Syftet är inte att täcka alla möjliga fall, utan att visa dig den grundläggande logiken: öppna filen, hitta en nod, skriva ut ett värde.
import xml.etree.ElementTree as ETtree = ET.parse("fattura.xml")root = tree.getroot()numero = root.find(".//Numero")if numero is not None:print(numero.text)Python är ofta det snabbaste valet för prototyper, omvandlingar och lätta bearbetningsflöden. Det är utmärkt när man behöver läsa in många XML-filer, extrahera några få fält och spara dem i CSV- eller JSON-format.
const xmlString = `<fattura><Numero>123</Numero></fattura>`;const parser = new DOMParser();const xmlDoc = parser.parseFromString(xmlString, "application/xml");const numero = xmlDoc.getElementsByTagName("Numero")[0];console.log(numero.textContent);Denna metod är användbar för snabba tester direkt på sidan eller små interna verktyg. Den fungerar bra för enkla gränssnitt, men mindre bra för strukturerade arbetsflöden inom backoffice.
const fs = require("fs");const xml2js = require("xml2js");const xml = fs.readFileSync("fattura.xml", "utf8");xml2js.parseString(xml, (err, result) => {if (err) throw err;console.log(result.fattura.Numero[0]);});Om du arbetar på serversidan och vill bygga automatiseringar är Node.js fortfarande ett praktiskt val. Fördelen är att det går att enkelt integrera XML-läsning med filsystem, bearbetningsköer och interna tjänster.
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();DocumentBuilder builder = factory.newDocumentBuilder();Document doc = builder.parse("fattura.xml");doc.getDocumentElement().normalize();NodeList lista = doc.getElementsByTagName("Numero");if (lista.getLength() > 0) {System.out.println(lista.item(0).getTextContent());}Java används ofta inom företagsmiljöer, affärssystem och middleware. Här handlar det inte bara om att läsa in data, utan om att göra det på ett förutsägbart och underhållsvänligt sätt.
library(XML)doc <- xmlParse("fattura.xml")numero <- xpathSApply(doc, "//Numero", xmlValue)print(numero)R är ett bra val när parsningen ingår i ett analytiskt arbete. Om nästa steg är en statistisk analys eller databehandling kan du hålla allt i samma miljö.
Om ditt team öppnar samma filer varje vecka och utför samma kontroller om och om igen, befinner du dig redan inom automatiseringens område.
Den verkliga vinsten ligger inte i att ”läsa XML med kod”. Den ligger i att befria människor från ett mekaniskt arbete och skapa ett flöde som genererar konsekventa datamängder.
De allvarliga problemen börjar när det inte längre handlar om en enda fil. En enskild FatturaPA går nästan alltid att hantera. Svårigheterna uppstår när man måste sammanställa flera månaders dokument, olika leverantörer, fält som fyllts i på olika sätt och inbäddade bilagor.
I italienska små och medelstora företag är det vanligaste fallet inte enstaka ”megafiler”, utan batcher. En årlig export av inköpsfakturor kan resultera i en struktur med över 380 000 noder fördelade på 4 200 fakturor, inklusive rubriker, detaljrader, betalningsuppgifter och bas64-kodade bilagor. I sådana situationer är problemet inte att öppna dokumentet, utan att omvandla heterogena XML-filer till en sammanhängande datamängd.
Här kommer ett tekniskt val in i bilden som påverkar verksamheten. I .NET-miljön anger Microsoft att XmlDocument laddar dokumentet i minnet och är användbart för läsning och redigering, medan det för stora filer eller läsbara operationer är bättre att välja mer effektiva metoder som strömmande parsare eller XPathDocument, för att undvika överdriven RAM-förbrukning, vilket anges i Microsofts dokumentation om XML-läsning med XmlDocument och XPathDocument.
I praktiken:
Avvägningen är enkel. Modellen i minnet gör att du kan utveckla snabbare. Strömningsmodellen fungerar bättre i produktion när det blir många eller stora filer.
Många team nöjer sig med XSD-validering. Det är användbart, men det räcker inte. En fil kan följa schemat och ändå generera felaktiga data i efterföljande steg.
Typiska exempel från det operativa arbetet:
| Kontrolltyp | Vad kontrolleras | Varför behövs det? |
|---|---|---|
| Strukturell | Taggar, format, hierarki | Undvik parsningsfel |
| Semantisk | Logisk konsistens i uppgifterna | Undvik felaktiga analyser |
| I drift | Fält som är användbara för rapportering | Undvik oanvändbara datamängder |
Det mest förrädiska fallet är följande: Dokumentets totalsumma är formellt giltig men stämmer inte överens med summan av raderna, kanske på grund av avrundningsregler i leverantörens affärssystem. Eller så kan det handla om momsnummer som formellt är godkända men som inte stämmer överens med transaktionens karaktär.
En formellt korrekt fil kan ändå förvränga dina rapporter.
Det finns dessutom en annan välkänd fallgrop i FatturaPA. Taggen ”DatiBeniServizi” innehåller fria beskrivningar. Samma kostnad kan anges på många olika sätt, med tydliga, förkortade eller kryptiska texter. Om man inte inför ett normaliseringssteg blir varje analys per utgiftskategori osäker.
Därför är inläsningen av filen bara nivå ett i seriösa dataströmmar. Nivå två består alltid av en uppsättning regler för konsistens och renhet. Det är där datakvaliteten säkerställs, inte i parsern.
En korrekt inläst XML-fil är ännu inte en användbar datamängd. Det är ett strukturerat dokument. För att kunna göra analyser, jämförelser, grupperingar och instrumentpaneler måste man nästan alltid konvertera den till ett format som är enklare att bearbeta.
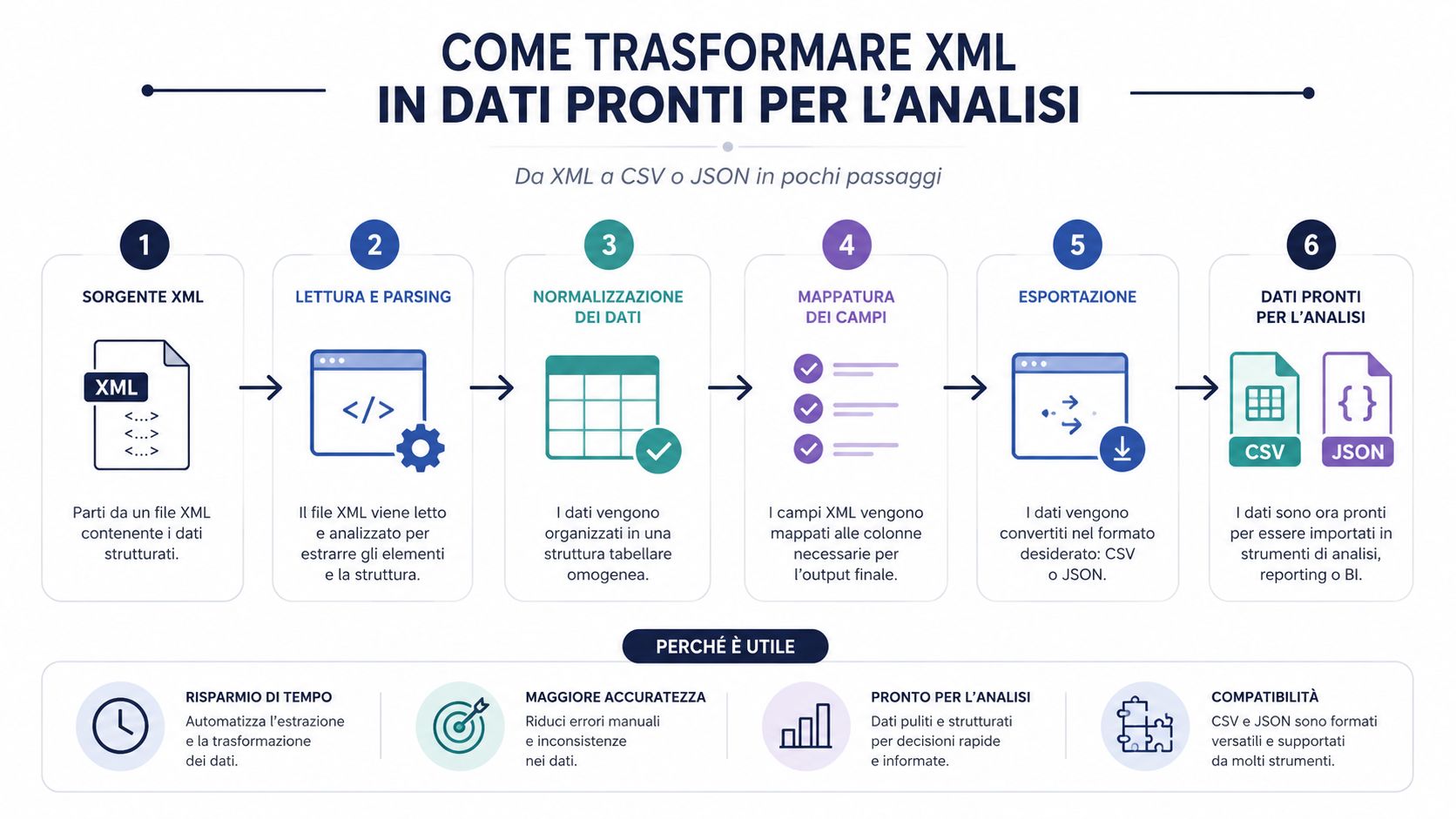
Det här är en aspekt som många processer underskattar. Flaskhalsen ligger sällan i själva parsningen. Ett bra bibliotek läser in XML på nolltid. Tiden går åt till att tolka strukturen, extrahera relevanta fält, rensa data, normalisera den och ladda upp den till ett analysverktyg.
Därför är konverteringen till CSV eller JSON inte bara en bekvämlighet. Det är ett centralt steg i arbetsprocessen. Om du hoppar över det här steget och arbetar direkt med råfilen slutar det nästan alltid med manuella kontroller, improviserade kolumner och logik som är svår att återskapa.
En användbar guide för den som ofta arbetar med både XML och kalkylblad är den här beskrivningen av hur man på ett mer strukturerat sätt överför data från XML till Excel.
Vilket format som är rätt beror på hur du kommer att använda uppgifterna senare.
CSV fungerar bra när man vill ha en rad per dokument eller en rad per fakturapost och sedan använda Excel, Power Query eller BI.
Exempel i Python:
import xml.etree.ElementTree as ETimport csvtree = ET.parse("fattura.xml")root = tree.getroot()with open("fatture.csv", "w", newline="", encoding="utf-8") as f:writer = csv.writer(f)writer.writerow(["numero", "data"])numero = root.findtext(".//Numero")data = root.findtext(".//Data")writer.writerow([numero, data])Fördelen är enkelheten. Nackdelen är att man måste välja noggrant hur man ska förenkla hierarkin. Om en faktura har flera detaljrader krävs ett tydligt val av detaljnivå och länkningsnyckel.
JSON är bäst lämpat när du vill behålla en del av den hierarkiska strukturen.
Exempel på JavaScript:
const record = {numero: "123",data: "2024-01-15",righe: [{ descrizione: "Servizio", importo: "100.00" }]};console.log(JSON.stringify(record, null, 2));Använd det när nästa steg är ett API, en datalake eller en applikation som fungerar bra med kapslade objekt.
Här är en praktisk regel som kan vara till hjälp:
XML-filen är behållaren. CSV och JSON är de format som gör innehållet verkligen användbart.
Om du vill förkorta tiden till insikt är det här du bör satsa på metodik. Inte på att hitta ett mer användarvänligt visualiseringsverktyg, utan på att definiera en stabil och repeterbar omvandling.
När filen väl har lästs in, validerats och bearbetats förändras arbetet. Du kämpar inte längre med taggarna. Nu kan du äntligen fokusera på kostnader, avvikelser, leverantörer, utgiftskategorier och operativa trender.
I verkligheten ligger värdet inte i själva parsningstiden. Det ligger i den tid det tar att omvandla råfilen till information som du kan fatta beslut utifrån. I ett manuellt arbetsflöde måste en person öppna dokumentet, förstå strukturen, extrahera fälten, rensa värdena, normalisera texterna och sedan skapa rapporter. Det är en sårbar process.
Ett klassiskt exempel inom FatturaPA är fritexten i DatiBeniServizi. Samma tjänst kan beskrivas på många olika sätt av olika leverantörer. Om man importerar dessa data utan en konsekvent mappning leder analysen per kostnadskategori till meningslösa sammanställningar.
Därför behövs ett förberedande lager innan analysplattformen tas i bruk, nämligen:
När detta steg genomförs på rätt sätt fungerar alla analysplattformar bättre. Om du vill fördjupa dig i de beslutsmässiga och visuella aspekterna av detta steg är resursen om hur man skapar berättelser med data till stor hjälp, eftersom den visar hur en ren datamängd kan omvandlas till en berättelse som är användbar för beslutsfattare.
Vid det här laget är XML-filen inte längre ett tekniskt problem, utan blir istället råmaterial för insikter. En väl förberedd dataset kan ligga till grund för kostnadsanalyser, trendövervakning, identifiering av avvikelser och tolkning av undantag.
För att välja en plattform som passar för denna sista etapp kan det vara till hjälp att jämföra vad en modern programvara för affärsanalys erbjuder jämfört med rent manuella arbetsflöden baserade på kalkylblad och pivottabeller.
Här är inte ”kan man öppna XML?” det rätta kriteriet. Det är ett minimum. Den relevanta frågan är en annan:
| Fråga | Varför det är viktigt |
|---|---|
| Uppgifterna är redan rensade när de kommer in | Undvik att dra exakta slutsatser utifrån felaktiga uppgifter |
| Kategorierna är konsekventa | Jämför du verkligen leverantörer och tidsperioder? |
| Avvikelserna upptäcks omedelbart | Minska tidsspillet vid manuella kontroller |
| Rapporten är lätt att förstå för personer inom affärs- och finansvärlden | Påskynda beslutsfattandet |
Skillnaden mellan en omogen och en mogen process ligger inte i förmågan att läsa XML-filer. Den ligger i förmågan att omvandla dem till en tillförlitlig databas, som inte tvingar teamet att göra om samma arbete varje gång.
Om du behöver läsa XML-filer på ett sätt som är till nytta för verksamheten, tänk på den här checklistan. Den är mer konkret än någon teknisk definition och hjälper dig att välja rätt metod utan att slösa tid.
Använd inte alltid samma tillvägagångssätt. Webbläsare, redigeringsprogram och visningsverktyg fungerar bra för snabba kontroller. Parsare och skript behövs när filen ska användas i upprepade processer. Om du blandar ihop visning och databehandling riskerar du att bygga rapporter på en bräcklig grund.
Filerna .xml.p7m kräver ett särskilt steg i hanteringen av signaturen. Om innehållet kommer från en PEC-adress är denna kontroll inte överflödig. Den ingår i den korrekta tolkningen av dokumentet.
Att följa ett schema garanterar inte en felfri datamängd. Logiska inkonsekvenser, såsom summor som inte stämmer överens eller tvetydiga skattekategorier, är det som oftast förstör analysen. Den semantiska kontrollen är det som skiljer en ”godtagbar” fil från tillförlitliga data.
CSV och JSON är inte bara en ytlig förändring. Det är det steg där XML blir användbart för analysverktyg, kalkylblad, bearbetningsflöden och rapporter. Ju tidigare du definierar denna omvandling, desto snabbare kan du minska manuellt arbete och improvisation.
Ditt mål är inte att läsa XML-filer. Det är att få fram användbara insikter utan att belasta systemet med felaktiga data. Om flödet inte ger en sammanhängande datamängd ligger problemet inte i den slutliga instrumentpanelen. Det ligger mycket längre upp i kedjan.
I praktiken kan du använda den här minichecklistan inför varje nytt projekt:
Om du vill omvandla redan förberedda data till tydliga och praktiskt användbara insikter hjälper ELECTE små och medelstora företag att gå från en ren datamängd till smart rapportering, med en metod som även är tillgänglig för icke-tekniska team. Det är det snabbaste sättet att överbrygga klyftan mellan operativa data och beslutsfattande.

.svg)
.svg)
.svg)
.webp)





