

Dina data berättar redan en historia. Problemet är att de ofta talar för tyst.
Varje dag samlar ett små- och medelstort företag in kundfeedback, order, supportärenden, transaktioner, affärsmejl och CRM-anteckningar. Allt detta material innehåller värdefulla signaler. Vissa tyder på att en kund är på väg att lämna företaget. Andra varnar för en operativ risk. Ytterligare andra visar vilka produkter som är på väg att öka eller minska i försäljning. Utan en tydlig metod förblir dessa signaler dock bara brus.
Bland de algoritmer som hjälper till att skapa ordning i detta kaos intar de naiva bayesianska klassificerarna en särställning. De är logiskt sett lätta att förstå, snabba att träna och ofta mer effektiva än vad namnet ”naiv” ger intryck av. De är inte det rätta valet i alla situationer, men i många verkliga affärsproblem erbjuder de en sällsynt balans mellan hastighet, tolkbarhet och användbara resultat.
Om du arbetar inom näringslivet behöver du inte bli forskare för att förstå dem. Du behöver veta vad de gör, varför de fungerar bra även när de förenklar verkligheten avsevärt, och i vilka fall de kan hjälpa dig att fatta bättre beslut. Det är just här det är värt att stanna upp och fundera.
Många företag letar efter sofistikerade modeller när problemet i första hand kräver en pålitlig och lättanvänd modell. Det är av samma skäl som det inom finans, detaljhandel eller kundtjänst ofta är den tydligaste processen som vinner, inte den som är mest elegant ur teoretisk synvinkel.
Naiva bayesianska klassificerare utgår från en mycket konkret idé. Om man har vissa ledtrådar om ett nytt fall kan man med stor sannolikhet uppskatta vilken kategori det tillhör. Om ett e-postmeddelande innehåller vissa ord kan det vara skräppost. Om en transaktion uppvisar vissa mönster kan den behöva granskas. Om en recension använder vissa uttryck kan det tyda på nöjdhet eller missnöje.
Ordet ”bayesiansk” för tankarna till komplexa formler. I själva verket är metodens kärna intuitiv. Man utgår från det man redan vet, lägger till nya bevis och uppdaterar sin bedömning. Det är ett strukturerat sätt att resonera i osäkra situationer, precis vad chefer gör varje dag, fast systematiskt genom en algoritm.
Det som är förvånande är att denna metod fortfarande fungerar bra även i moderna miljöer, med stora datamängder och snabba beslut. Inte för att den ger en perfekt beskrivning av verkligheten, utan för att den skiljer ut den användbara informationen från bruset till en mycket låg beräkningskostnad.
När det gäller affärsfrågor är den rätta frågan inte ”vilken modell är den mest sofistikerade?”. Den är ”vilken modell ger mig tillförlitliga beslut inom en tidsram som passar det praktiska arbetet?”.
Därför är naiva bayesianska klassificerare fortfarande viktiga. De hjälper dig att klassificera, filtrera, segmentera och prioritera. Och de gör det möjligt för dig att integrera sannolikhetsanalys i beslutsprocessen utan att varje projekt förvandlas till en teknisk utmaning.
Grundprincipen är Bayes sats. Enkelt uttryckt innebär det följande: man utgår från en initial sannolikhet och uppdaterar den sedan när ny information kommer in.
I datatermer skrivs formeln så här: P(y|x) ∝ P(y) ⋅ ∏ P(x_i|y). Det innebär att sannolikheten för en klass, givet en uppsättning signaler, beror på två faktorer. Den första är klassens initiala sannolikhet. Den andra är i vilken utsträckning varje signal stämmer överens med den klassen.
Översatt till ett affärsexempel. Du måste avgöra om ett e-postmeddelande är skräppost eller inte. Du har en allmän sannolikhet för att ett inkommande e-postmeddelande är skräppost. Sedan tittar du på vissa ord som ”erbjudande”, ”gratis” och ”klicka här”. Var och ett av dessa ord påverkar det slutgiltiga omdömet.
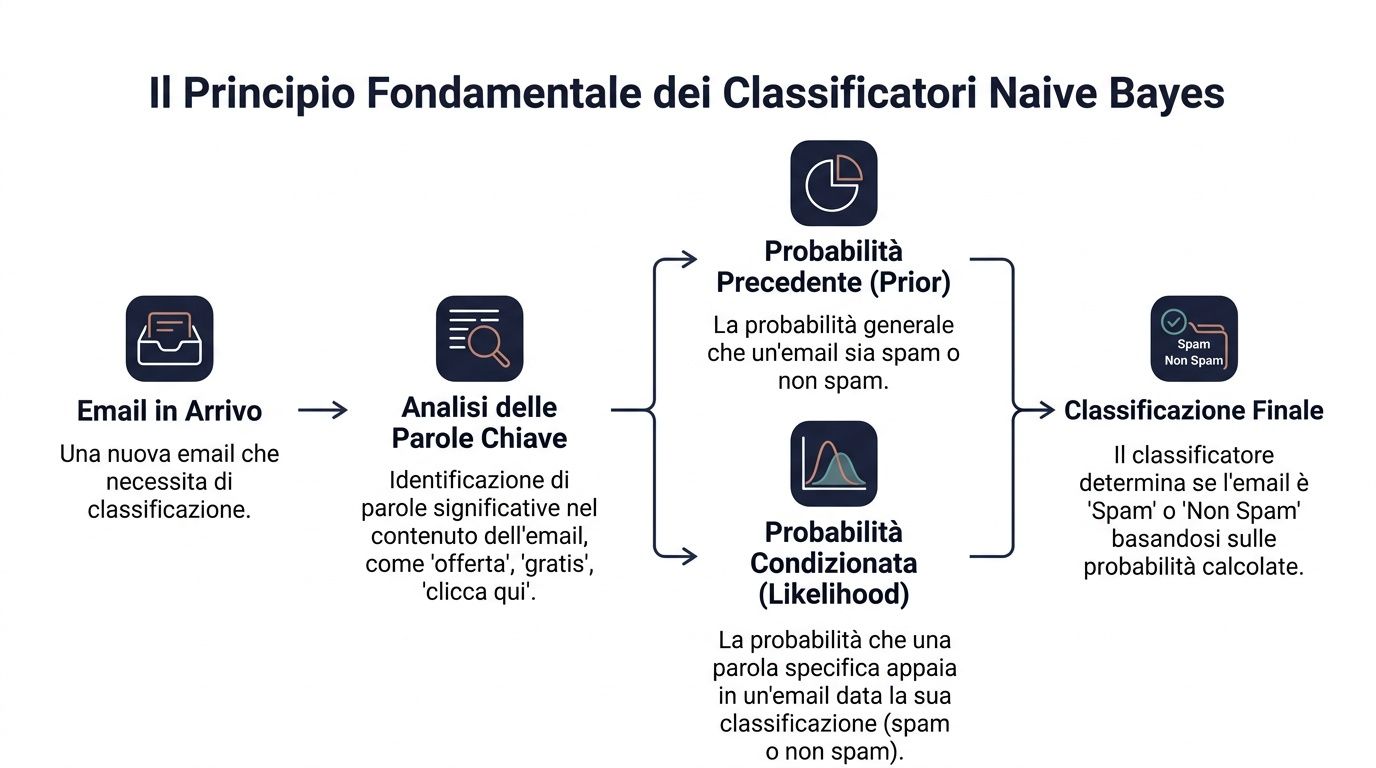
En chef gör något liknande varje dag. Hen fattar aldrig beslut i ett vakuum. Hen utgår från en grundläggande kontext och lägger till ledtrådar. En kund som alltid har handlat regelbundet har en viss utgångsprofil. Om hen sedan slutar öppna e-postmeddelanden, minskar ordervärdet och öppnar ett kritiskt ärende, förändras din bedömning.
Termen ”naiv” syftar på ett specifikt antagande. Modellen behandlar egenskaperna som om de vore oberoende av varandra, eftersom klassen är känd.
I praktiken bör du, när du klassificerar ett e-postmeddelande, betrakta varje ord som en separat ledtråd. Försök inte att modellera alla komplexa samband mellan termerna. Detta är en kraftig förenkling. I verkligheten förekommer många ord tillsammans och många affärsmässiga beteenden hänger ihop.
Ändå är det just detta val som gör modellen så lätt. Den behöver inte lära sig ett invecklat nätverk av beroenden. Den behöver bara beräkna enklare sannolikheter och kombinera dem på ett effektivt sätt.
En praktisk regel: Naive Bayes försöker inte återge hela världen. Den försöker fatta användbara beslut utifrån få antaganden och med hög hastighet.
Det är här missförståndet ofta uppstår. Många läser ”naiv antagande” och drar slutsatsen ”svag modell”. Så är det inte. En modell kan förenkla mycket och ändå vara konkurrenskraftig om förenklingen fångar det som är viktigt för beslutsfattandet.
År 2004 visade en teoretisk analys att det finns välgrundade skäl till varför Naive Bayes-klassificerare är effektiva trots antagandet om oberoende, och förklarade även varför de kan nå det asymptotiska felet snabbare än logistisk regression. Inom samma tillämpningsområde uppnår de vid spamfiltrering en träffsäkerhet på över 99 % och kan hantera miljontals dokument, vilket beskrivs i artikeln om Naive Bayes-klassificerare.
Denna punkt är viktig för en företagsmålgrupp. Värdet av en algoritm ligger inte bara i slutresultatet. Det ligger också i dess förmåga att snabbt lära sig, anpassa sig till stora datamängder och förbli tolkbar.
När man har text, kategorier, etiketter eller signaler som är utspridda fungerar naiva bayesianska klassificerare bra eftersom:
Det finns dock två saker man bör tänka på.
Av denna anledning bör Naive Bayes betraktas som ett mycket effektivt verktyg för snabba klassificeringsuppgifter, inte som en universell trollstav. I många praktiska sammanhang är det dock ett av de smartaste sätten att börja på.
Ett vanligt misstag är att tala om Naive Bayes som om det vore en enda identisk modell som passar i alla situationer. I själva verket finns det olika varianter, utformade för olika typer av data.
Det rätta valet beror på vilken form dina data har. Om du väljer fel variant kan modellen visserligen fortfarande generera en prognos, men den resonerar inte på det sätt som passar bäst för ditt problem.
Gaussian Naive Bayes är den mest lämpliga varianten när egenskaperna är kontinuerliga. Tänk till exempel på genomsnittligt transaktionsbelopp, kundens ålder, genomsnittlig tid mellan två köp, enhetsmarginal eller kvittots värde.
Här utgår modellen från att värdena inom varje klass följer en normalfördelning. Du behöver inte se detta som en akademisk begränsning. Det räcker att du håller fast vid den praktiska tanken: för varje klass beräknar modellen ett typiskt medelvärde och en spridning.
Denna metod är användbar när du vill klassificera fall som:
I ett scikit-learn-benchmark med en dataset som liknar italienska e-handelsdata uppnådde en Naive Bayes-modell en träffsäkerhet på 95 % med 1 000 exempel, med en träningstid som var 15% kortare än den logistiska regressionen . Jämförelsen är 0,01 s mot 0,1 s på en standard-CPU, tack vare träning i sluten form, vilket visas i Jake VanderPlas kapitel om In Depth Naive Bayes Classification.
För ett företag handlar det inte om decimalen. Poängen är att denna variant kan ge bra resultat utan långa inlärningstider och utan en tung infrastruktur.
Om du arbetar med texter, ärenden, recensioner eller kommentarer är Multinomial Naive Bayes ofta det självklara valet. Här består egenskaperna av räknevärden eller frekvenser. I praktiken tittar modellen på hur många gånger ord eller termer förekommer.
Det är det klassiska scenariot där:
Anledningen till att det fungerar bra är mycket konkret. I företagstexter kan ordförrådet vara omfattande, men varje dokument innehåller bara en liten del av de möjliga orden. Data är spridda. Multinomial Naive Bayes hanterar just denna typ av struktur väl.
I en studie av 100 000 italienska tweets som klassificerats efter sentiment uppnådde Multinomial Naive Bayes ett F1-värde på 0,88 och var tio gånger snabbare än SVM, vilket beskrivs i GeeksforGeeks guide om Naive Bayes-klassificerare.
För att lättare komma ihåg det kan du tänka så här: om dina data liknar ett dokument fullt av räknade ord är multinomialmodellen nästan alltid det första alternativet du bör testa.
Om ditt företag behöver bearbeta stora textmängder är frågan inte bara ”hur exakt är modellen?”. Den är också ”hur många förfrågningar kan den hantera utan att det går ut över teamets arbetsflöde?”.
Bernoulli Naive Bayes arbetar med binära egenskaper. Det spelar ingen roll hur många gånger ett tecken förekommer. Det enda som räknas är om det finns eller inte.
Denna variant är användbar när förekomsten av ett attribut är viktigare än dess frekvens. Några exempel från näringslivet:
Det är en mycket användbar logik när man vill omvandla komplexa fenomen till enkla ja/nej-indikatorer som är lätta att följa. Vid sentimentanalys kan det till exempel vara viktigare att ett negativt ord förekommer än hur många gånger det upprepas.
Bernoulli-fördelningen är inte ”mindre avancerad” än multinomialfördelningen. Den är helt enkelt bättre lämpad när data beskriver närvaro eller frånvaro. Skillnaden är liten i teorin, men stor i praktiken.
| Variant | Idealisk datatyp | Exempel på ett användningsfall inom företaget |
|---|---|---|
| Gaussisk Naive Bayes | Kontinuerliga data | Klassificera transaktioner efter risk med hjälp av belopp, frekvens och medelvärden |
| Multinomial Naive Bayes | Texter, beräkningar, frekvenser | Analysera kundrecensioner och supportärenden efter tonfall eller kategori |
| Bernoulli och Naive Bayes | Binära data, närvaro/frånvaro | Utvärdera ja/nej-signaler inom regelefterlevnad, support eller produktanvändning |
För att göra ett bra val, följ denna enkla regel:
Många team fastnar i sitt arbete eftersom de letar efter den absolut ”bästa” modellen. Det rätta valet är nästan alltid den modell som bäst passar datatypen.
Den goda nyheten är att det inte krävs något gigantiskt projekt för att tillämpa Naive Bayes i praktiken. Redan en överskådlig prototyp ger en förståelse för hur modellen resonerar och vilka data den behöver.

En klassificeringsmodell skapas nästan alltid i fyra steg.
Datförberedelse
Du måste samla in historiska exempel som redan är märkta. Om du klassificerar recensioner behöver du texter som redan är märkta som positiva eller negativa. Om du analyserar operativa risker behöver du tidigare fall med känt utfall.
Träning av modellen
Modellen analyserar data och beräknar relevanta sannolikheter. I naiva bayesianska klassificerare går detta steg snabbt eftersom träningen inte kräver särskilt resurskrävande optimeringar.
Prognos för nya fall
Lägg in nya poster så tilldelar modellen en klass. Till exempel ”spam”, ”inte spam”, ”riskkund”, ”stabil kund”.
-utvärdering: Jämför prognoserna med verkligheten på en separat testuppsättning. Här tittar du inte bara på om modellen fungerar. Du tittar på hur den gör fel.
Om du vill fördjupa dig i den övergripande bilden av prediktiva metoder kan den här översikten över maskininlärningsalgoritmer hjälpa dig att placera Naive Bayes i ett bredare sammanhang av metoder.
För att konkretisera processen följer här ett enkelt exempel med scikit-learn. Du behöver inte läsa det som utvecklare. Det räcker med att förstå flödet.
# Vi importerar de viktigaste verktygenfrom sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_splitfrom sklearn.naive_bayes import GaussianNBfrom sklearn.metrics import accuracy_score# Vi laddar en exempeldatasetX, y = load_iris(return_X_y=True)# Vi delar upp data i en del för träning och en del för testX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# Vi skapar modellenmodel = GaussianNB()# Vi tränar modellen på historiska data model.fit(X_train, y_train)# Vi gör förutsägelser på data vi aldrig sett tidigare y_pred = model.predict(X_test)# Vi mäter noggrannheten print(accuracy_score(y_test, y_pred))Denna lilla text säger mycket mer än man först tror.
GaussianNB() välj alternativet för kontinuerliga data.fit() Det är då modellen lär sig.predict() tillämpa det han har lärt sig.accuracy_score() Kontrollera hur många klassificeringar som är korrekta totalt sett.När det gäller textdata är arbetsflödet ungefär detsamma, men innan du använder modellen måste du omvandla texten till siffror. I praktiken innebär det att du omvandlar orden till egenskaper som kan användas av en klassificerare.
Efter en första titt på koden kan det vara bra att se en visuell förklaring av hur det fungerar.
Den första modellen syftar inte till att bevisa perfektion. Den syftar till att besvara tre praktiska frågor.
Här ser man styrkan med Naive Bayes. Man kan snabbt ta fram en stabil baslinje. Utifrån den kan man avgöra om det är värt att göra projektet mer komplicerat eller om en enkel lösning redan skapar värde.
En klassificeringsmodell bedöms inte enbart utifrån att den ”verkar fungera”. Den bedöms utifrån hur den gör fel och hur stor inverkan dessa fel har på verksamheten.

Noggrannheten är det mest intuitiva måttet. Det visar hur många av prognoserna som stämmer i förhållande till det totala antalet. Det är användbart, men kan vara missvisande om det används på egen hand.
Om endast ett fåtal av hundra transaktioner verkligen är misstänkta, kan en modell som klassificerar nästan allt som normalt verka ha god träffsäkerhet men ändå vara bristfällig just där den verkligen behövs.
För att förstå det kan du tänka dig ett fisknät.
I affärsvärlden är denna distinktion mycket viktig.
En bra modell är inte den som generellt sett gör få fel. Det är den som gör fel på det sätt som kostar minst för din process.
För att bättre förstå hur en algoritm lär sig av historiska data och varför kvaliteten på träningen påverkar det slutliga resultatet kan du läsa den här artikeln om vad algoritmträning innebär.
Naive Bayes är enkelt, men det förlåter inte vissa praktiska misstag.
Första misstaget: att bortse från problemet med nollfrekvens.
Om ett ord eller ett värde aldrig förekommer i träningsdata för en viss klass kan sannolikheten sjunka till noll och påverka beräkningen negativt. Därför används ofta Laplace-utjämning, som lägger till en liten korrigering i räkningarna.
Andra misstaget: att använda starkt korrelerade variabler.
Om två kolumner innehåller nästan samma information riskerar modellen att överskatta signalen. Den ”förstår” inte att de två indikatorerna nästan är identiska.
Tredje misstaget: att lita för mycket på de råa sannolikheterna.
Naive Bayes ger ofta bra resultat, men dess sannolikheter kan vara alltför entydiga. För företag innebär detta att rankningen kan vara användbar, medan det exakta sannolikhetsvärdet bör tolkas med försiktighet.
För att minska dessa risker bör man:
Det verkliga värdet hos naiva bayesianska klassificerare blir tydligt när man slutar betrakta dem som en matematisk övning och istället börjar använda dem som ett verktyg för att sätta prioriteringar. I företagsvärlden innebär en bra klassificering nästan alltid bättre beslut.

Tänk dig ett ekonomiteam som analyserar transaktionsflöden, transaktionsbeskrivningar och historiska signaler. Varje rad är inte bara en post. Det är ett potentiellt beslut: att låta passera, granska närmare, stoppa eller vidarebefordra till en analytiker.
Med Naive Bayes kan du kombinera olika indikatorer i en enda klassificering. Vissa är numeriska, andra binära och andra textbaserade. Modellen hjälper dig att förstå vilka fall som mest liknar mönster som redan har observerats som normala eller avvikande.
Den praktiska fördelen är tvåfaldig:
Det ersätter inte mänskligt omdöme i reglerade sammanhang. Det strukturerar det. Och i operativa processer med stora volymer gör detta en verklig skillnad.
Inom marknadsföring innebär segmentering ofta att varje kund placeras i en specifik grupp. Lojala kunder. Priskänsliga kunder. Kunder med risk för avhopp. Kunder som reagerar på erbjudanden. Inaktiva kunder.
Här är Naive Bayes användbart eftersom det snabbt kan kombinera olika typer av signaler:
Ett CRM-team behöver inte någon perfekt teori om mänskligt beteende. Det behöver en segmentering som är tillräckligt bra för att kunna vidta meningsfulla åtgärder. Till exempel att ändra budskapet, kontaktfrekvensen eller typen av erbjudande.
När en modell hjälper till att välja nästa meddelande till rätt kund skapar den redan ett operativt värde.
Inom detaljhandeln och e-handeln underlättar klassificering arbetsuppgifter som till synes skiljer sig åt men som bygger på samma logik: att skapa ordning i kaoset.
Du kan sortera produkterna efter deras försäljningsprofil. Du kan läsa recensioner och supportärenden för att få en bild av vilka kategorier som orsakar problem. Du kan upptäcka efterfrågemönster som hjälper teamet att planera kampanjer och lager på ett mer genomtänkt sätt.
I den här typen av miljöer är data ofta omfattande, heterogena och inte alltid felfria. Därför är en snabb, skalbar och lättöverskådlig modell mycket värdefull. Inte för att den är särskilt glamorös, utan för att den smälter in i arbetsflödet utan att bromsa det.
Om du vill se hur analysmetoder inom affärsverksamhet omsätts i praktiken i konkreta projekt kan du ta en titt på dessa fallstudier.
Det är bra att förstå Naive Bayes. Att implementera det på rätt sätt i ett företagssammanhang är en helt annan sak.
Problemet handlar nästan aldrig enbart om algoritmen. Det verkliga arbetet kretsar kring modellen. Man måste koppla samman olika datakällor, hantera saknade fält, förbereda texter, uppdatera etiketter, kontrollera kvaliteten på utdata och tolka resultaten på ett sätt som är begripligt för beslutsfattarna.
För ett små- och medelstort företag är detta steg ofta den kritiska punkten. Inte för att intresset för AI saknas, utan för att teamets tid är begränsad och de operativa prioriteringarna inte kan vänta.
Här är det lämpligt att använda en plattform som hanterar den tekniska komplexiteten. En AI-driven lösning gör det möjligt att omvandla rådata till begripliga insikter utan att verksamheten behöver skriva kod, välja bibliotek eller underhålla manuella processflöden.
En plattform som ELECTE, en AI-driven dataanalysplattform för små och medelstora företag, gör metoder som naiva bayesianska klassificerare tillgängliga utan att det krävs specialistkunskaper inom maskininlärning. Fördelen är inte bara hastigheten. Det handlar om att minska friktionen mellan data och beslut.
När automatiseringen fungerar väl tänker teamet inte längre i termer av formler. Istället ställer de sig användbara frågor:
Det är också därför som allt fler företag söker efter verktyg som hjälper dem att bedöma tillförlitligheten hos AI-genererat innehåll och de textuella signaler som cirkulerar i de interna processerna. I detta sammanhang kan det vara värdefullt att ta del av en guide om en italiensk AI-detektor, särskilt om ditt team arbetar med dokument, innehåll och språkliga granskningar.
I praktiken är skillnaden enkel. Istället för att hantera fragmenterade tekniska steg lägger du fokus på företagets resultat. Och det är just här som AI verkligen blir användbar, inte bara intressant.
Naiva bayesianska klassificerare visar på en viktig lärdom. Inom analys kan väl tillämpad enkelhet slå dåligt hanterad komplexitet.
Med en intuitiv sannolikhetsbas, god skalbarhet och mycket konkreta användningsfall förblir denna metod ett pålitligt verktyg för företag som vill klassificera information, tolka dolda signaler och agera med större säkerhet. Man behöver inte vara expert på maskininlärning för att förstå dess värde. Det handlar om att koppla samman matematiken med det operativa beslutsfattandet.
När detta samband blir tydligt upphör AI att vara en teknisk fråga och blir istället en organisatorisk fördel. Det är då prognoserna börjar ge resultat.
Om du vill omvandla spridda data till tydliga insikter, prova ELECTE. Plattformen hjälper små och medelstora företag att koppla samman datakällor, automatisera analysen och få rapporter och prognoser som är användbara för snabbare och mer välgrundade beslut.

.svg)
.svg)
.svg)






