

這就是為什麼Mistral Science比許多其他更受矚目的 AI 發布更為重要。 無論您身處研究、產業或數據策略領域,真正的突破並非又一個能流利談論科學的虛擬助理。而是歐洲正嘗試打造一套專為科學研究而設的人工智慧系統,能夠在物理、材料、生物學及金融系統等不容許任何近似誤差的領域中,建模、模擬並加速發現進程。 對歐洲而言,這遠不止關乎單一企業。它觸及了歐洲多年來一直存在的結構性弱點:在關鍵數位基礎設施方面,過度依賴非歐洲的模型供應商。
Mistral 對開放權重模型的關注,以及其透過 Emmi AI 進軍專業科學人工智慧領域,預示著一條不同的發展路徑。在這條路徑上,歐洲組織能夠在對數據、方法及下游依賴關係擁有更大掌控權的前提下,對模型進行審查、調整與部署。
以下是報章頭條背後的核心問題:為何這項變革可能成為歐洲科技主權的轉捩點?對目前正選擇人工智慧技術堆疊的研究人員、中小企業及科技領袖而言,這在實際層面上又意味著什麼?
Mistral 的吸引力不僅在於它是歐洲的產物。它的吸引力在於,它正嘗試實現一項歐洲迄今為止鮮少能在全球層面達成的目標:將人工智慧從通用的軟體能力,轉變為研究與產業的戰略基礎設施。
差異至關重要。一款消費級模型能提升個人生產力、書寫能力及獲取知識的管道;而用於科學研究的人工智慧平台,則能縮短發現週期、支援模擬運算、加速假設篩選,並改變實驗室、運算與產業決策之間的關係。
即使在義大利,這個議題也絕非抽象。 義大利國家統計局(Istat)已正式將人工智慧應用於統計流程的創新,相關工作涵蓋摘要資料、分類器、聊天機器人,以及用於自動化編碼、改善行政資料庫,並分析地域與地理空間影像的LAbInn計畫,這顯示其已從實驗性應用邁向更為結構化的制度化採用(Istat 對人工智慧的方針)。
主題:通用大型語言模型(LLM)Mistral Science 與科學模型主要目標:語言處理、內容生成、對話輔助模擬、建模、加速發現學習基礎:大型語料庫中的統計模式專業數據、領域限制、 物理定律典型輸出合理且表述精確的回應在技術或科學工作流程中具實用價值的預測戰略價值跨領域生產力可辯護的產業與科學優勢歐洲層面影響若採封閉式架構則依賴全球供應商若採開放式權重且具適應性則能提升控制力
應將「Mistral Science」視為一項歐洲戰略資產,而非單一功能。
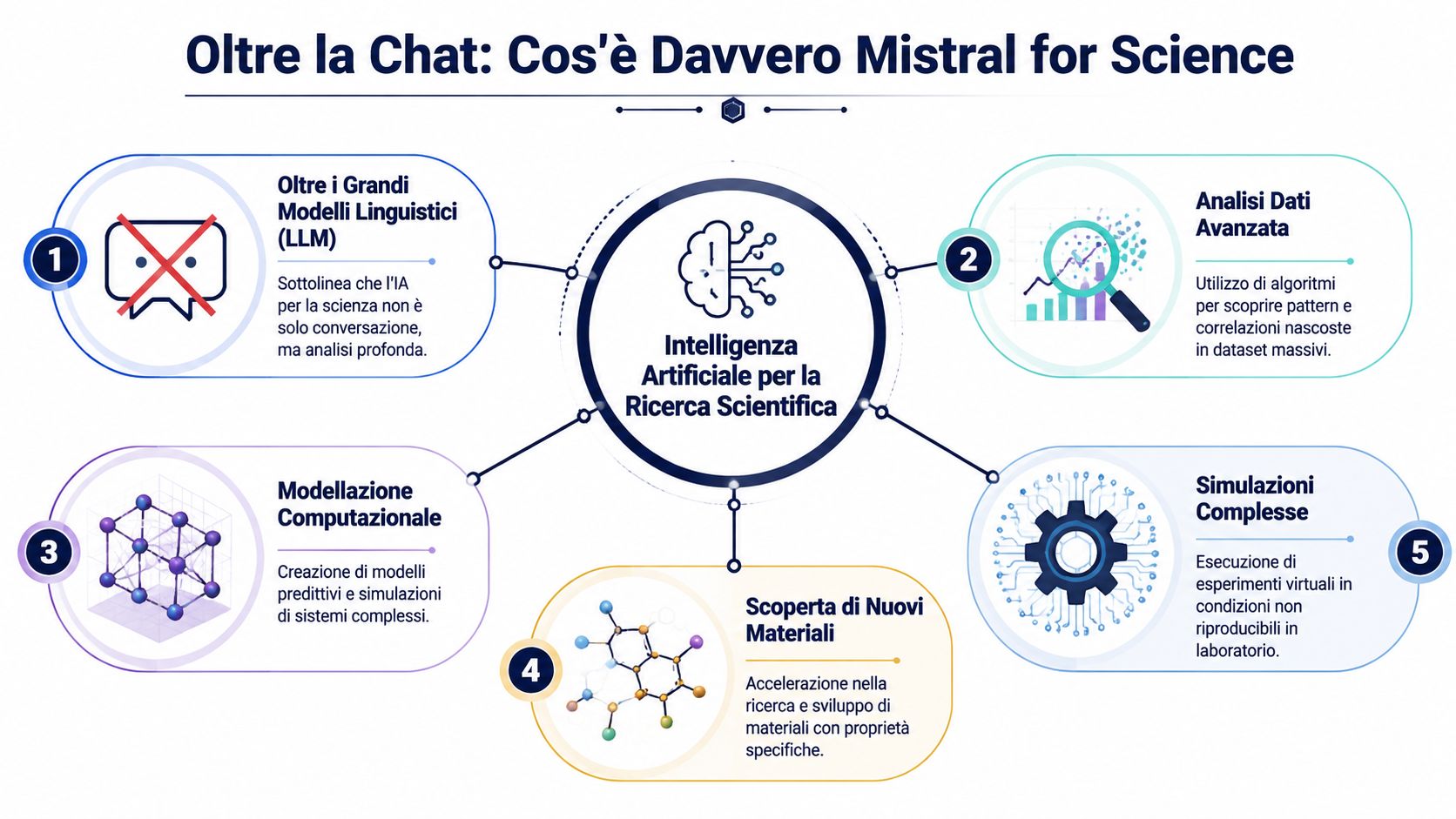
首先必須釐清的是:不應將「Mistral for Science」解讀為聊天機器人的學術版本。這種解讀過於狹隘,會導致錯誤的評估。
當一個通才型模型「談論科學」時,通常會將從文本、文章、文件和程式碼中習得的技術術語重新組合起來。這對於總結、解釋或提出假設或許有所助益,但並不能等同於對物理系統、工程動力學或高保真模擬的準確呈現。
在科學研究中,問題不僅在於說出合乎邏輯的話。問題在於必須遵守實際的限制。
一般性模型可以向你解釋空氣動力學。工程模型則應協助你模擬流體在特定條件下的行為。大型語言模型(LLM)可以摘要材料科學的論文。而專用模型則應有助於縮小需要測試的可能性範圍。
這正是Emmi AI收購案如此重要的原因。其戰略意圖十分明確:Mistral 並不打算僅止於語言應用層面。它正進軍一個模型能內建問題結構的領域。
所謂的「大型工程模型」指明了一個明確的方向。這些不僅是基於技術文件訓練而成的模型,更是專為在現實受方程式、限制條件與模擬所支配的環境中運作而設計的系統。
對歐洲讀者而言,這改變了「科學人工智慧」的本質意義。重點不在於為研究人員打造更優秀的助手,而在於建構一個能加速針對實際問題進行研究的運算引擎。
三項實際影響:
此外,還有一個常被忽略的層面。 在義大利,國家統計局(Istat)對人工智慧的制度性採用,為這項飛躍創造了更有利的文化與運作環境。若國家統計機構運用人工智慧進行數據彙總、編碼自動化及地理空間數據分析,這便傳達出一個訊息:科學級人工智慧不再僅限於精英實驗室,而是已融入公共知識產出的正式流程之中。
通用型大型語言模型(LLM)擅長解釋世界。而一個有用的科學模型則必須能協助你進行計算。
這正是許多人未能領會的關鍵。Mistral Science 的重要性不在於它「涉足科學領域」,而在於它試圖將 Mistral 推向一個更具說服力的範疇——在那裡,價值源自模型、應用領域與工業流程之間的整合。
Mistral 最被低估的特點,並非該公司行動的迅速程度,而是其選擇專注於開放級別(open-weight)船型的決策。對於研究界以及許多歐洲企業而言,這項決策比任何示範活動都更具戰略意義。
僅透過 API 提供的封閉式模型能為您帶來便利;開放式模型則能賦予您更大的控制權。而在歐洲,控制權並非一種哲學上的偏好,而是當您處理敏感資料、智慧財產權、受監管的流程或關鍵產業鏈時,必須具備的營運條件。
當模型的權重可供存取時,組織便能執行某些在純黑盒服務下難以實現或根本無法實現的任務。
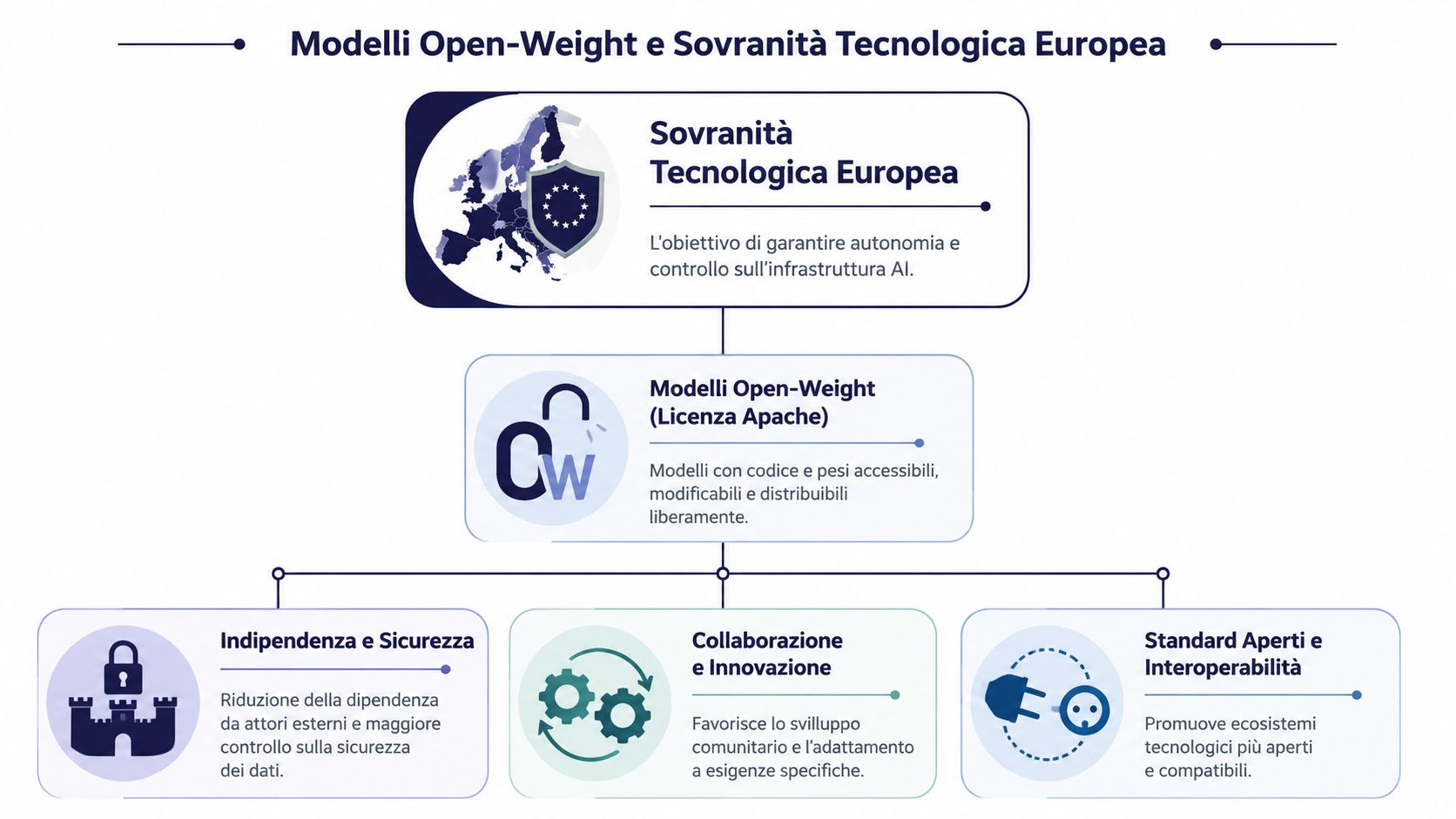
正因如此,技術主權不應僅被視為政策文件中的空泛詞彙。對企業而言,這意味著必須釐清誰掌控該模型、數據流經何處、解決方案的可客製化程度,以及未來若要轉換方向將付出多少代價。
若您負責管理研究數據、智慧財產權或高度合規的流程,您真正該問的並非「哪種模型最知名?」,而是「我該選擇哪種模型,才能在不將戰略依賴性交給單一外部供應商的情況下,有效掌控其運作?」
這一點在法規與組織層面同樣適用。任何正在處理企業人工智慧相關義務的人都明白,這不僅僅是模型的表現問題。決策的可追溯性、對限制的理解,以及記錄使用情況的能力,同樣至關重要。
此外,還有一個較少被討論的經濟因素。在學術界和中小企業中,開放式權重的價值不僅在於成本,更在於其能培養在地專業能力。一個開放的模型能促進學習、適應與內部工具開發;反之,封閉的 API 則往往將認知與營運權力集中於服務提供者手中。
所謂的科技主權,始於你能選擇如何使用某個模型,而不僅僅是能夠購買使用權。
從這個角度來看,Mistral 的舉措意義明確。如果歐洲希望在人工智慧領域建立可信的地位,僅僅擁有轉售他人技術能力的初創企業是不夠的。我們需要能夠建立模型、生態系統以及與歐洲工業現實相容的採用標準的參與者。
為了了解這條發展路徑將引向何方,不妨參考市場上已有的實務案例。微軟表示,微軟量子(Microsoft Quantum)與太平洋西北國家實驗室(PNNL)透過 Azure Quantum Elements,已對超過 3,200 萬種材料進行數位篩選,並成功發現一種鋰用量減少 70% 的新型電池材料,且僅花費數週便完成了篩選與測試工作(運用人工智慧與高效能運算進行科學探索)。
這個例子雖與 Mistral 無直接關聯,但它展現了該領域正朝著的價值目標:整合人工智慧、高效能運算與快速驗證,以大幅縮小研究範圍。

這堂課的重點並非「人工智慧能創造奇蹟」。這堂課的重點更為務實:透過大規模篩選、自動優先排序與針對性測試的恰當結合,能夠縮短研究時間並降低認知成本。
當一個團隊不再盲目探索,而是開始更有效地篩選假設時,前期決策的品質便會隨之改變。從這個角度來看,人工智慧在科學研究領域的真正價值在於其篩選能力,而非浮誇的噱頭。
實際上,像「Mistral Science」這樣的計畫,在那些僅靠語言無法滿足需求的領域中,確實具有實質意義。
此外還有一個較不直觀的觀點。 《Il Bo Live》彙整的研究指出,在公共研究中使用人工智慧工具的研究者,發表的文章數量約為未使用者的三倍,獲得的引用次數近五倍,且晉升領導職位的速度也更快。但同一項研究也發現,主題的集體探索減少了4.63%,且引用同一項工作的文章之間的引用次數下降了22%(《Nature》期刊上該研究的義大利語分析)。
這項數據引出了一个令人不適卻有用的結論:人工智慧雖能提升科學生產力,卻同時會壓縮探索的多樣性。因此,負責建構研究平台與流程的人,不僅須著重效率,更須兼顧假設的多樣性。
當關於Mistral的討論滑向兩個極端時,便變得毫無意義。一方面,是對任何歐洲參與者都表現出的盲目熱忱;另一方面,則是下意識地認為,凡是未能主導所有通用基準測試的參與者,皆不具重要性。
現實情況更為耐人尋味。在最困難的跨領域推理題上,整個領域的表現仍遠未達到真正令人放心的程度。
一份義大利的基準測試指南指出,NinjaTech 的 Deep Research 模型在「Humanity's Last Exam」測試中達到了17.47% 的準確率,該測試被視為多領域推理領域中最困難的測試之一。該指南同時指出,用於研究的基準測試還應考量延遲、推理品質以及透過 API 使用時的網路效能(適用於研究情境的 AI 基準測試)。

這組數據必須仔細解讀。它並未證明任何單一模型表現欠佳,而是表明即使是先進的模型,在處理需要穩健泛化能力的課題時,仍會遭遇困難。因此,若僅憑此就斷言Mistral在處理最複雜的任務時,在整體意義上可與美國最頂尖的前沿模型相提並論,未免過於天真。
但正確的比較基準並非「誰在任何情況下都勝出」,而是「對於特定任務而言,哪種架構和策略更為合適」。
Mistral 在某些通用領域的表現或許稍遜一籌,但在真正關鍵的領域卻更具吸引力:
若僅將市場視為一場追求絕對基準的競賽,Mistral 恐怕會顯得處於落後地位。但若將其視為為特定應用場景建構歐洲基礎設施,觀點便會截然不同。在此框架下,目標並非在競爭最激烈的領域擊敗所有對手,而是佔據一個高價值的細分市場——在那裡,開放性、效率與專業化的結合,比單純的規模更為重要。
為了理解這一點,有必要先掌握大型語言模型(Large Language Models)的市場概況,但不要僅止於一般性模型的排名。
Mistral 的戰略優勢並非源於試圖滿足所有人的所有需求,而是源於它能在「主導地位比規模更重要」的領域發揮極大作用。
此外,還有一個市場往往忽略的警示。義大利針對生成式人工智慧在科學研究中應用所進行的分析指出,當這些系統被濫用時,會出現來源可驗證性問題、潛在的版權風險,以及科學品質的下降。這是一個簡單的提醒:模型的表面自主性越高,人類在方法論上的自律就必須越強。
對一家歐洲企業而言,結論並非「永遠選擇 Mistral」或「永遠選擇最強勁的型號」。這將是錯誤的捷徑。正確的選擇取決於您試圖解決的問題類型。
無論您的問題涉及跨領域、文件處理、語言或一般用途的生產力,選用一款通才型大型語言模型(LLM)或許是明智之舉。
但若您使用的是:
那麼問題就變了。在這種情況下,你必須評估:一個專業化的模型——或者至少是可調整且可控的模型——是否能創造比演示效果更出色的封閉式服務更大的戰略價值。
一個實用的框架可以從以下五項準則著手:
市場上仍有一部分人會繼續將人工智慧視為一種工具來採購。對於許多應用場景而言,這確實是合理的選擇。但那些在歐洲高度專業化領域中運作的企業,應該開始將人工智慧視為戰略基礎設施來考量。正是在這個轉變過程中,像 Mistral Science 這樣的舉措才顯得至關重要。
最實用的教訓很簡單:不要將通用人工智慧的魅力與專用人工智慧的價值混為一談。

以下是會議中需討論的要點:
Mistral Science 雖非歐洲人工智慧發展的終點,但它無疑是最強烈的訊號之一,顯示歐洲已開始採取更明智的策略。不再僅是模仿全球領導者,而是選擇能在哪些領域建立自身優勢。
如果您正在考慮如何將人工智慧融入實際的決策流程,同時避免增加不必要的複雜性,不妨認識一下ELECTE。這是一個由人工智慧驅動的數據分析平台,旨在將原始數據轉化為可操作的洞察,其操作方式即使對非技術團隊而言也十分直觀。您可以親身體驗其運作方式,並了解哪種人工智慧架構最適合您的應用情境。

.svg)
.svg)
.svg)






