

คุณได้รับไฟล์ XML ผ่านทางอีเมลรับรอง คุณเปิดไฟล์ในเบราว์เซอร์ของคุณ เห็นเพียงแท็กที่สับสนและคิดว่าปัญหาคือการ 'อ่าน' ไฟล์นั้น ในความเป็นจริง นั่นเป็นเพียงอุปสรรคแรกเท่านั้น ปัญหาที่แท้จริงภายในบริษัทคือสิ่งอื่น:การตรวจสอบว่าข้อมูลนั้นถูกต้อง สอดคล้องกัน และพร้อมที่จะรวมไว้ในรายงานของคุณหรือไม่
สำหรับธุรกิจขนาดกลางและขนาดย่อมของอิตาลีหลายแห่ง ปัญหานี้ไม่ได้เป็นเพียงเรื่องทางเทคนิคอีกต่อไป ตั้งแต่การออกใบแจ้งหนี้ทางอิเล็กทรอนิกส์กลายเป็นข้อบังคับ XML ได้กลายเป็นส่วนหนึ่งของการบริหารจัดการ การควบคุม และการวิเคราะห์ในทุกวัน การดูเอกสารเพียงอย่างเดียวไม่เพียงพอ คุณจำเป็นต้องสามารถแยกแยะระหว่างไฟล์ที่อ่านได้กับไฟล์ที่เชื่อถือได้ คุณต้องเข้าใจว่าเมื่อใดการตรวจสอบอย่างรวดเร็วเพียงพอ และเมื่อใดที่ต้องมีการแยกวิเคราะห์ การตรวจสอบความถูกต้อง และการปรับให้เป็นมาตรฐานก่อนนำข้อมูลไปโหลดใน Excel ระบบ BI หรือแพลตฟอร์มการวิเคราะห์ข้อมูล
หากคุณกำลังมองหาคู่มือปฏิบัติเกี่ยวกับการอ่านไฟล์ XML นี่คือแนวทางที่ถูกต้อง: เริ่มต้นด้วยวิธีการที่ง่ายที่สุด ค้นหาจุดที่เกิดข้อผิดพลาด แล้วสร้างกระบวนการทำงานที่เปลี่ยน XML ดิบให้เป็นข้อมูลที่มีประโยชน์ต่อธุรกิจ นั่นคือจุดที่คุณสามารถลดข้อผิดพลาดและย่นระยะเวลาจาก 'ฉันได้ไฟล์มาแล้ว' เป็น 'ฉันได้ข้อมูลเชิงลึกที่นำไปใช้ได้แล้ว'
ไฟล์ XML จัดระเบียบข้อมูลให้เป็นโครงสร้างลำดับชั้น มีองค์ประกอบหลัก (root element) มีส่วนที่ซ้อนกันอยู่ภายใน และแต่ละบล็อกจะอธิบายข้อมูลหนึ่งชิ้นที่มีความหมายเฉพาะ สำหรับผู้ที่จัดการกระบวนการทางด้านการบริหาร รายละเอียดเหล่านี้สร้างความแตกต่างระหว่างข้อมูลที่เพียงแค่สามารถอ่านได้ กับข้อมูลที่สามารถนำไปใช้ประโยชน์ได้จริง
ประเด็นไม่ได้อยู่ที่การ 'เปิด' ไฟล์ ประเด็นคือการพิจารณาว่าไฟล์นั้นสามารถรวมเข้ากับกระบวนการควบคุม การบัญชี และการวิเคราะห์ได้โดยไม่เกิดข้อผิดพลาดหรือไม่
ลองใช้ใบแจ้งหนี้อิเล็กทรอนิกส์เป็นตัวอย่าง ภายในไฟล์เดียวกันนี้ คุณจะพบรายละเอียดของผู้จัดจำหน่าย รายละเอียดของลูกค้า จำนวนเงินที่ต้องเสียภาษี ภาษีมูลค่าเพิ่ม รายการสินค้า เงื่อนไขการชำระเงิน อ้างอิงคำสั่งซื้อ และบ่อยครั้ง ข้อยกเว้นที่ทำให้ยากต่อการอ่าน ในรูปแบบ XML ข้อมูลเหล่านี้ไม่ได้ถูกจัดเรียงตามลำดับเหมือนในเอกสารมาตรฐาน แต่จะถูกวางไว้ในตำแหน่งเฉพาะ และตำแหน่งนั้นจะอธิบายว่าแต่ละส่วนของข้อมูลหมายถึงอะไร
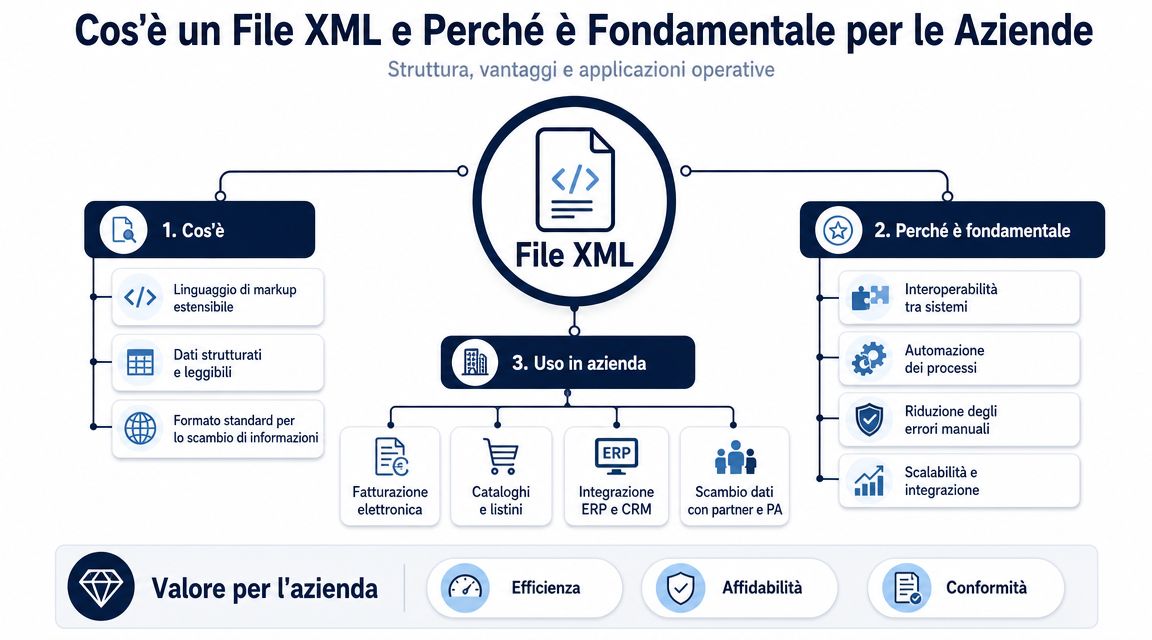
สำหรับผู้จัดการ ความแตกต่างที่มีประโยชน์ไม่ใช่ระหว่างแท็กและแอตทริบิวต์ในเชิงทฤษฎี แต่เป็นระหว่างข้อมูลที่แยกออกมาและข้อมูลที่เชื่อถือได้ การเห็น '1000.00' โดยไม่มีบริบทมีประโยชน์น้อยมาก การเห็นมันในที่ที่ถูกต้องในไฟล์ช่วยให้คุณเข้าใจว่ามันเป็นยอดรวมของเอกสาร จำนวนที่ต้องเสียภาษี ภาษีที่ต้องชำระ หรือมูลค่าของบรรทัดเดียว
นี่คือจุดที่ข้อได้เปรียบในการปฏิบัติงานครั้งแรกเกิดขึ้น XML รักษาบริบทของข้อมูลไว้
กฎทั่วไป:การอ่านไฟล์ XML อย่างถูกต้องหมายถึงการตรวจสอบความหมายของค่า ไม่ใช่เพียงแค่ค่าเอง
ในอิตาลี ปัญหานี้ได้กลายเป็นความจริงแล้วจากการนำระบบใบแจ้งหนี้อิเล็กทรอนิกส์มาใช้อย่างแพร่หลาย ในรูปแบบ FatturaPA นั้น XML ได้กลายเป็นมาตรฐานสำหรับเอกสารทางภาษี ดังนั้น การตีความข้อมูลนี้จึงไม่ใช่เรื่องเฉพาะของฝ่ายไอทีอีกต่อไป แต่เกี่ยวข้องกับการบริหารจัดการ การควบคุมการบริหาร การจัดซื้อจัดจ้าง และทุกคนที่ต้องใช้ข้อมูลนั้นในการตัดสินใจ
ในทางปฏิบัติ ฉันเห็นปัญหาเดิมซ้ำอยู่เสมอ ไฟล์มีอยู่ ข้อมูลก็มีครบถ้วน แต่เวลาที่ใช้ในการเปลี่ยนข้อมูลเหล่านั้นให้กลายเป็นข้อมูลที่มีประโยชน์นั้นยาวนานเกินไป มีคนเปิดไฟล์ XML ตรวจสอบด้วยสายตา คัดค่าข้อมูลไปใส่ใน Excel แก้ไขฟิลด์ที่ไม่สอดคล้องกัน เปลี่ยนชื่อซัพพลายเออร์ที่เขียนชื่อแตกต่างกัน และพยายามสร้างหมวดหมู่ค่าใช้จ่ายขึ้นมาใหม่ เนื่องจากไฟล์ไม่ได้จัดรูปแบบไว้ให้พร้อมสำหรับการวิเคราะห์ ต้นทุนที่เกิดขึ้นไม่ได้มีแค่ค่าใช้จ่ายในการดำเนินงานเท่านั้น มันคือเวลาที่สูญเสียไปในการได้ข้อมูลเชิงลึก
ด้วย FatturaPA ความเสี่ยงยิ่งชัดเจนมากขึ้น ไฟล์ที่ถูกต้องตามรูปแบบสองไฟล์สามารถก่อให้เกิดปัญหาการวิเคราะห์เดียวกันได้ หากไฟล์หนึ่งใช้คำอธิบายรายการที่คลุมเครือมาก หากการอ้างอิงคำสั่งซื้อไม่สมบูรณ์ หรือหากข้อมูลหลักของผู้จัดหาถูกป้อนด้วยรูปแบบที่แตกต่างกัน ณ จุดนี้ ปัญหาไม่ได้อยู่ที่การอ่าน XML ปัญหาคือการป้องกันไม่ให้ข้อมูลภาษีที่ถูกต้องกลายเป็นข้อมูลการจัดการที่ไม่น่าเชื่อถือ
ข้อผิดพลาดที่พบบ่อยคือการปฏิบัติต่อ XML ราวกับว่าเป็นไฟล์แนบที่ต้องดูเท่านั้น ภายในบริษัท การมอง XML เป็นแหล่งข้อมูลที่มีโครงสร้างซึ่งต้องตรวจสอบก่อนที่จะป้อนเข้าสู่รายงาน แดชบอร์ด และแบบจำลองค่าใช้จ่ายจะช่วยให้ได้ผลลัพธ์ที่ดีกว่า หากขั้นตอนนี้ถูกจัดการอย่างไม่เหมาะสม ทีมการเงินอาจพบว่าตัวเองกำลังอภิปรายตัวเลขที่ดูเหมือนถูกต้องแต่กลับอิงจากการจัดประเภทที่ไม่สอดคล้องกัน
คำถามที่ถูกต้องที่ควรถามตั้งแต่ต้นคือ:
นี่คือการตรวจสอบที่มีความเป็นประโยชน์อย่างมาก. พวกมันช่วยหลีกเลี่ยงการมีผู้จัดหาซ้ำในรายงาน, การตีความภาษีมูลค่าเพิ่มผิดพลาด, ศูนย์ต้นทุนที่ไม่ได้กรอกข้อมูลอย่างสมบูรณ์, และการกระทบยอดที่ช้าในตอนสิ้นเดือน.
นี่คือจุดที่ช่องว่างระหว่างการตีความทางเทคนิคกับคุณค่าทางธุรกิจปรากฏให้เห็นอย่างชัดเจน ตัวอ่านไฟล์ (parser) จะอ่านไฟล์นั้น ๆ กระบวนการที่ออกแบบมาอย่างดีจะผลิตข้อมูลที่สะอาด สามารถเปรียบเทียบได้ และพร้อมสำหรับการวิเคราะห์ แพลตฟอร์มเช่น ELECTE ได้ถูกพัฒนาขึ้นอย่างเฉพาะเจาะจงเพื่อเชื่อมช่องว่างนี้ ลดงานที่ต้องทำด้วยตนเองในการแปลง XML ที่ได้รับให้กลายเป็นข้อมูลเชิงลึกที่สามารถช่วยให้การตัดสินใจดีขึ้น
สำหรับการตรวจสอบอย่างรวดเร็วในไฟล์เดียว คุณไม่จำเป็นต้องใช้ตัวแยกวิเคราะห์หรือไลบรารี คุณต้องพิจารณาว่าคุณกำลังทำการตรวจสอบด้วยสายตาเพียงไม่กี่ฟิลด์ หรือคุณกำลังจัดการข้อมูลที่จะนำไปใช้ในบัญชี รายงาน หรือการควบคุมการจัดการ ความแตกต่างนี้มีความสำคัญ โดยเฉพาะอย่างยิ่งกับ FatturePA การตรวจสอบที่รีบเร่งในวันนี้อาจส่งผลให้เกิดการบันทึกข้อมูลที่ไม่ถูกต้องในชุดข้อมูลผู้จัดหาในวันพรุ่งนี้

เบราว์เซอร์, โปรแกรมแก้ไขข้อความ และโปรแกรมดูเฉพาะทาง ช่วยแก้ปัญหาเฉพาะอย่าง: การอ่านเนื้อหาอย่างรวดเร็วโดยไม่ต้องตั้งค่าขั้นตอนการทำงานทางเทคนิค สำหรับไฟล์เดียว นี่มักจะเพียงพอแล้ว คุณสามารถเปิดไฟล์ XML ใน Chrome, Edge หรือ Firefox เพื่อดูโครงสร้างของไฟล์ หรือใช้ Notepad, WordPad หรือ TextEdit หากคุณต้องการตรวจสอบแท็กโดยตรง ในกรณีของใบแจ้งหนี้อิเล็กทรอนิกส์ การใช้โปรแกรมดูเฉพาะจะทำให้ส่วนหัว รายการเอกสาร ยอดเงินที่ต้องเสียภาษี และ VAT อ่านได้ง่ายขึ้น
ประเด็นสำคัญคือ:
| เครื่องมือ | มีประโยชน์สำหรับ | ข้อจำกัดหลัก |
|---|---|---|
| เบราว์เซอร์ | การตรวจสอบโครงสร้างด้วยสายตาอย่างรวดเร็ว | ไม่ตรวจสอบความสอดคล้องระหว่างฟิลด์และส่วนต่างๆ |
| โปรแกรมแก้ไขข้อความ | การตรวจสอบแท็กโดยตรง | มันกลายเป็นเรื่องยุ่งยากเมื่อมีไฟล์ที่ยาวหรือซ้อนกัน |
| เอ็กเซล | การตรวจสอบเบื้องต้นในรูปแบบตาราง | มันจัดการลำดับชั้นและการทำซ้ำได้ไม่ดี |
| ผู้ชมที่ทุ่มเท | อ่านใบแจ้งหนี้และเอกสารภาษีได้ง่ายขึ้น | มันไม่ได้เตรียมข้อมูลสำหรับการวิเคราะห์หรือการอัตโนมัติ |
หากคุณต้องการตรวจสอบวันที่เอกสาร หมายเลข VAT ยอดรวมใบแจ้งหนี้ หรือว่ามีไฟล์แนบหรือไม่ เครื่องมือเหล่านี้เหมาะสม
หากในทางกลับกัน เป้าหมายคือการเปรียบเทียบซัพพลายเออร์ จัดหมวดหมู่ค่าใช้จ่าย หรือกรอกข้อมูลลงในแดชบอร์ด การดูข้อมูลเพียงอย่างเดียวจะทำให้การทำงานช้าลงและเปิดโอกาสให้เกิดข้อผิดพลาดจากการทำงานด้วยมือมากเกินไป นี่คือช่องว่างคลาสสิกระหว่างการดูไฟล์กับการได้มาซึ่งข้อมูลที่เชื่อถือได้ในเวลาที่เหมาะสม
การเปิดไฟล์ XML ไม่ได้หมายความว่าข้อมูลที่คุณจะใช้ในรายงานของคุณได้รับการตรวจสอบความถูกต้องแล้ว
อีกประเด็นที่ควรพิจารณาในทางปฏิบัติคือปริมาณ เอกสารสิบฉบับยังสามารถตรวจสอบด้วยมือได้ แต่ใบแจ้งหนี้ FatturePA หลายร้อยฉบับไม่สามารถทำได้ ในกรณีเช่นนี้ การพิจารณาขั้นตอนการทำงานที่สามารถทำซ้ำได้หรือเครื่องมือที่สามารถอ่านเนื้อหาในรูปแบบที่มีโครงสร้าง เช่น ผ่านAPI เพื่อดึงและจัดการเอกสารทางภาษีในลักษณะที่บูรณาการกันนั้น ถือว่าคุ้มค่าแล้ว
ในอิตาลี ปัญหาที่เกิดขึ้นซ้ำๆ ไม่ใช่การเปิด .xmlแต่การรู้ว่าต้องทำอย่างไรเมื่อ .xml.p7m ผ่านทาง PEC. ต้องมีการแยกแยะระหว่างไฟล์ XML ธรรมดาและไฟล์ที่มีการลงนามดิจิทัล. ไฟล์หลังต้องการเครื่องมือที่สามารถอ่านลายเซ็น, สกัดเนื้อหา และแสดง XML ที่ถูกต้อง, ตามที่ได้อธิบายไว้ คู่มือนี้เกี่ยวกับ XML และ XML P7M ในอีเมลรับรอง (PEC).
ที่นี่ ความผิดพลาดทำให้เสียเวลา:
สำหรับผู้ช่วยงานธุรการ ลำดับขั้นตอนที่มีประโยชน์ที่สุดคือ:
วิธีการเหล่านี้ใช้ได้ดีสำหรับการตรวจสอบระดับแรก อย่างไรก็ตาม พวกมันไม่สามารถแก้ปัญหาที่แท้จริงที่บริษัทเผชิญอยู่ได้: การแปลงไฟล์ XML ภาษี – ซึ่งมักไม่สม่ำเสมอหรือไม่สอดคล้องกัน – ให้เป็นข้อมูลที่สะอาดและสามารถเปรียบเทียบได้ โดยไม่เพิ่มเวลาที่ใช้ในการสกัดข้อมูลที่มีประโยชน์จากเอกสารที่ได้รับ
เมื่อไฟล์เริ่มกองพะเนิน งานที่ทำด้วยมือจะกลายเป็นสิ่งที่ไม่สามารถรับมือได้ ในจุดนั้น การอ่านไฟล์ XML ด้วยโค้ดไม่ใช่ทางออกที่งดงาม มันเป็นก้าวแรกในการหลีกเลี่ยงงานที่ทำซ้ำๆ ข้อผิดพลาดในการคัดลอก และชุดข้อมูลที่ไม่สอดคล้องกัน

แนวทางที่เหมาะสมในการอ่าน XML มักจะปฏิบัติตามตรรกะเดียวกันเสมอ: การแยกวิเคราะห์, การทำให้เป็นมาตรฐาน, การดึงข้อมูลตามเป้าหมาย ในบทเรียน Java และ Android ขั้นตอนการทำงานที่ถูกต้องจะเกี่ยวข้องกับ พาร์ส (), โดยการทำให้ต้นไม้เป็นปกติโดยใช้ doc.getDocumentElement().normalize() และจากนั้นโดยการคืนค่าฟิลด์ด้วย getElementsByTagNameซึ่งเป็นวิธีที่เชื่อถือได้มากกว่าการดูไฟล์ในโปรแกรมแก้ไขข้อความเพียงอย่างเดียว ดังที่แสดงโดย คู่มือเทคนิคเกี่ยวกับการอ่านข้อมูล XML.
ลำดับนี้มีความสำคัญมากกว่าภาษาที่คุณเลือกใช้ หากคุณข้ามขั้นตอนการปรับให้เป็นมาตรฐาน หากคุณค้นหาโหนดด้วยวิธีที่ง่ายเกินไป หรือหากคุณสมมติว่าแท็กจะปรากฏเพียงครั้งเดียวเท่านั้น สคริปต์ของคุณจะทำงานได้กับบางไฟล์ แต่จะล้มเหลวกับไฟล์ที่สำคัญที่สุดเท่านั้น
สำหรับโครงการที่ต้องเชื่อมต่อกับระบบภายนอก การสร้างกระบวนการสกัดข้อมูลที่สามารถทำซ้ำได้และมีเอกสารประกอบอย่างครบถ้วนจะเป็นประโยชน์อย่างยิ่ง หากคุณกำลังทำงานเกี่ยวกับการผสานรวมแอปพลิเคชัน เอกสารประกอบAPI ของ ELECTE ซึ่งรวมถึงโปรไฟล์ Postman ที่ได้รับการตรวจสอบแล้ว จะเป็นจุดเริ่มต้นที่มีประโยชน์ โดยเฉพาะอย่างยิ่งสำหรับการทำความเข้าใจวิธีการเชื่อมโยงชุดข้อมูลที่ได้ผ่านการทำความสะอาดแล้วกับกระบวนการถัดไป
ด้านล่างนี้คือตัวอย่างง่าย ๆ บางส่วน จุดประสงค์ไม่ใช่เพื่อครอบคลุมทุกสถานการณ์ที่เป็นไปได้ แต่เพื่อแสดงให้คุณเห็นตรรกะพื้นฐาน: เปิดไฟล์, ค้นหาโหนด, พิมพ์ค่า
นำเข้า xml.etree.ElementTree เป็น ETtree = ET.parse("fattura.xml") root = tree.getroot() numero = root.find(".//Numero") if numero is not None: print(numero.text)Python มักเป็นตัวเลือกที่รวดเร็วที่สุดสำหรับการสร้างต้นแบบ การแปลงข้อมูล และกระบวนการทำงานแบบเบา (lightweight pipelines) มันเหมาะอย่างยิ่งเมื่อคุณต้องการอ่านไฟล์ XML จำนวนมาก ดึงข้อมูลเพียงไม่กี่ฟิลด์ และบันทึกเป็น CSV หรือ JSON
const xmlString = `<fattura><Numero>123</Numero></fattura>`;const parser = new DOMParser();const xmlDoc = parser.parseFromString(xmlString, "application/xml");const numero = xmlDoc.getElementsByTagName("Numero")[0];console.log(numero.textContent);แนวทางนี้มีประโยชน์สำหรับการทดสอบบนหน้าเว็บอย่างรวดเร็วหรือเครื่องมือภายในองค์กรขนาดเล็ก มันทำงานได้ดีสำหรับอินเทอร์เฟซที่มีน้ำหนักเบา แต่ไม่ค่อยเหมาะสำหรับกระบวนการทำงานหลังบ้านที่มีโครงสร้าง
const fs = require("fs");const xml2js = require("xml2js");const xml = fs.readFileSync("fattura.xml", "utf8");xml2js.parseString(xml, (err, result) => {if (err) throw err;console.log(result.fattura.Numero[0]);});หากคุณทำงานบนฝั่งเซิร์ฟเวอร์และต้องการสร้างระบบอัตโนมัติ Node.js ยังคงเป็นตัวเลือกที่ใช้งานได้จริง ข้อดีคือช่วยให้คุณสามารถผสานการแยกวิเคราะห์ XML เข้ากับระบบไฟล์ คิวการประมวลผล และบริการภายในได้อย่างง่ายดาย
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();DocumentBuilder builder = factory.newDocumentBuilder();Document doc = builder.parse("fattura.xml");doc.getDocumentElement().normalize();NodeList lista = doc.getElementsByTagName("Numero");if (lista.getLength() > 0) {System.out.println(lista.item(0).getTextContent());}Java มักถูกใช้ในบริบทขององค์กรธุรกิจ การจัดการธุรกิจ และซอฟต์แวร์กลาง จุดสำคัญที่นี่ไม่ใช่แค่การอ่านข้อมูลเท่านั้น แต่ต้องทำในลักษณะที่สามารถคาดการณ์ได้และบำรุงรักษาได้ง่าย
library(XML)doc <- xmlParse("fattura.xml")numero <- xpathSApply(doc, "//Numero", xmlValue)print(numero)R มีความเหมาะสมเมื่อการแยกวิเคราะห์เป็นส่วนหนึ่งของงานวิเคราะห์ หากขั้นตอนต่อไปของคุณคือการวิเคราะห์ทางสถิติหรือการเตรียมข้อมูล คุณสามารถเก็บทุกอย่างไว้ในสภาพแวดล้อมเดียวกันได้
หากทีมของคุณเปิดไฟล์เดียวกันทุกสัปดาห์และดำเนินการตรวจสอบแบบเดิม ๆ คุณก็อยู่ในขอบเขตของระบบอัตโนมัติแล้ว
ประโยชน์ที่แท้จริงไม่ใช่ 'การอ่าน XML ด้วยโค้ด' แต่เป็นการปลดปล่อยผู้คนจากงานเชิงกลไกและสร้างกระบวนการทำงานที่สร้างชุดข้อมูลที่สอดคล้องกัน
ปัญหาที่แท้จริงเริ่มขึ้นเมื่อมีมากกว่าหนึ่งไฟล์ FatturaPA หนึ่งไฟล์สามารถจัดการได้เกือบตลอดเวลา ความยากลำบากเกิดขึ้นเมื่อคุณต้องรวบรวมเอกสารหลายเดือน ผู้จัดหาหลายราย ข้อมูลที่กรอกไม่สม่ำเสมอ และไฟล์แนบที่ฝังอยู่
ในธุรกิจขนาดกลางและขนาดย่อมของอิตาลี สถานการณ์ที่พบได้บ่อยที่สุดไม่ใช่ไฟล์ขนาดใหญ่เพียงไฟล์เดียว แต่เป็นชุดไฟล์ การส่งออกใบแจ้งหนี้ซื้อรายปีอาจส่งผลให้เกิดโครงสร้างที่มีมากกว่า 380,000 โหนดครอบคลุมใบแจ้งหนี้ 4,200 ฉบับ ซึ่งประกอบด้วยส่วนหัว รายการสินค้า รายละเอียดการชำระเงิน และไฟล์แนบที่เข้ารหัสแบบ base64 ในสถานการณ์เช่นนี้ ปัญหาไม่ได้อยู่ที่การเปิดเอกสาร แต่เป็นการแปลง XML ที่มีความหลากหลายให้กลายเป็นชุดข้อมูลที่สอดคล้องกัน
นี่คือจุดที่การเลือกทางเทคนิคเข้ามามีบทบาทซึ่งมีผลกระทบต่อธุรกิจ ในสภาพแวดล้อม .NET ไมโครซอฟท์ระบุว่า `XmlDocument` จะโหลดเอกสารเข้าสู่หน่วยความจำและมีประโยชน์สำหรับการอ่านและแก้ไข ในขณะที่สำหรับไฟล์ขนาดใหญ่หรือการดำเนินการแบบอ่านอย่างเดียว แนะนำให้ใช้วิธีที่มีประสิทธิภาพมากกว่า เช่น ตัวแยกวิเคราะห์แบบสตรีมมิ่งหรือ`XPathDocument` เพื่อหลีกเลี่ยงการใช้ RAM มากเกินไปตามที่ระบุไว้ในเอกสารของไมโครซอฟท์เกี่ยวกับการอ่าน XML ด้วย `XmlDocument` และ `XPathDocument`
ในทางปฏิบัติ:
การแลกเปลี่ยนนั้นง่าย โมเดลในหน่วยความจำช่วยให้คุณพัฒนาได้เร็วขึ้น โมเดลสตรีมมิ่งทำงานได้ดีกว่าในสภาพแวดล้อมการผลิตเมื่อมีไฟล์จำนวนมากหรือเมื่อไฟล์มีขนาดใหญ่
หลายทีมหยุดที่การตรวจสอบความถูกต้องของ XSD. มันมีประโยชน์ แต่มันไม่เพียงพอ. ไฟล์อาจสอดคล้องกับสคีมา และยังคงผลิตข้อมูลที่เสียหายในขั้นตอนต่อไป.
ตัวอย่างทั่วไปจากการดำเนินงานประจำวัน:
| ประเภทของการตรวจสอบ | มันตรวจสอบอะไรบ้าง? | ทำไมจึงจำเป็นต้องมี? |
|---|---|---|
| โครงสร้าง | แท็ก, รูปแบบ, ลำดับชั้น | หลีกเลี่ยงข้อผิดพลาดในการแยกวิเคราะห์ |
| ความหมาย | ความสอดคล้องทางตรรกะของข้อมูล | หลีกเลี่ยงการวิเคราะห์ที่ไม่ถูกต้อง |
| ปฏิบัติการ | การมีอยู่ของฟิลด์ที่มีประโยชน์สำหรับการรายงาน | หลีกเลี่ยงชุดข้อมูลที่ไม่สามารถใช้งานได้ |
กรณีที่น่ากลัวที่สุดคือ:'จำนวนเอกสารทั้งหมด'ที่ถูกต้องตามรูปแบบแต่ไม่ตรงกับผลรวมของรายการย่อย อาจเป็นเพราะกฎการปัดเศษในระบบบัญชีของผู้จัดจำหน่าย หรือรหัสภาษีมูลค่าเพิ่มที่ถูกต้องตามรูปแบบแต่ไม่สอดคล้องกับลักษณะของธุรกรรม
ไฟล์ที่ถูกต้องทางเทคนิคก็ยังสามารถทำให้รายงานของคุณคลาดเคลื่อนได้
ยังมีข้อผิดพลาดที่รู้จักกันดีอีกประการหนึ่งใน FatturaPA แท็ก'DatiBeniServizi'ประกอบด้วยคำอธิบายในรูปแบบอิสระ ค่าใช้จ่ายเดียวกันอาจปรากฏในหลายรูปแบบที่แตกต่างกัน โดยมีข้อความที่ชัดเจน ย่อ หรือเข้าใจยาก หากไม่รวมขั้นตอนการปรับให้เป็นมาตรฐาน การวิเคราะห์ตามหมวดหมู่ค่าใช้จ่ายจะไม่น่าเชื่อถือ
ด้วยเหตุนี้ ในกระบวนการไหลของข้อมูลที่มีความสำคัญ การอ่านไฟล์เป็นเพียงขั้นตอนแรกเท่านั้น ขั้นตอนที่สองคือชุดของกฎความสอดคล้องและการตรวจสอบความถูกต้อง นั่นคือจุดที่คุณภาพของข้อมูลได้รับการปกป้อง ไม่ใช่ในตัวแยกวิเคราะห์ข้อมูล
ไฟล์ XML ที่ถูกอ่านสำเร็จแล้ว ยังไม่ใช่ชุดข้อมูลที่มีประโยชน์ มันเป็นเพียงเอกสารที่มีโครงสร้างเท่านั้น หากต้องการดำเนินการวิเคราะห์ เปรียบเทียบ จัดกลุ่ม หรือสร้างแดชบอร์ด คุณแทบจะต้องแปลงไฟล์นี้เป็นรูปแบบที่ทำงานได้ง่ายกว่าเสมอ
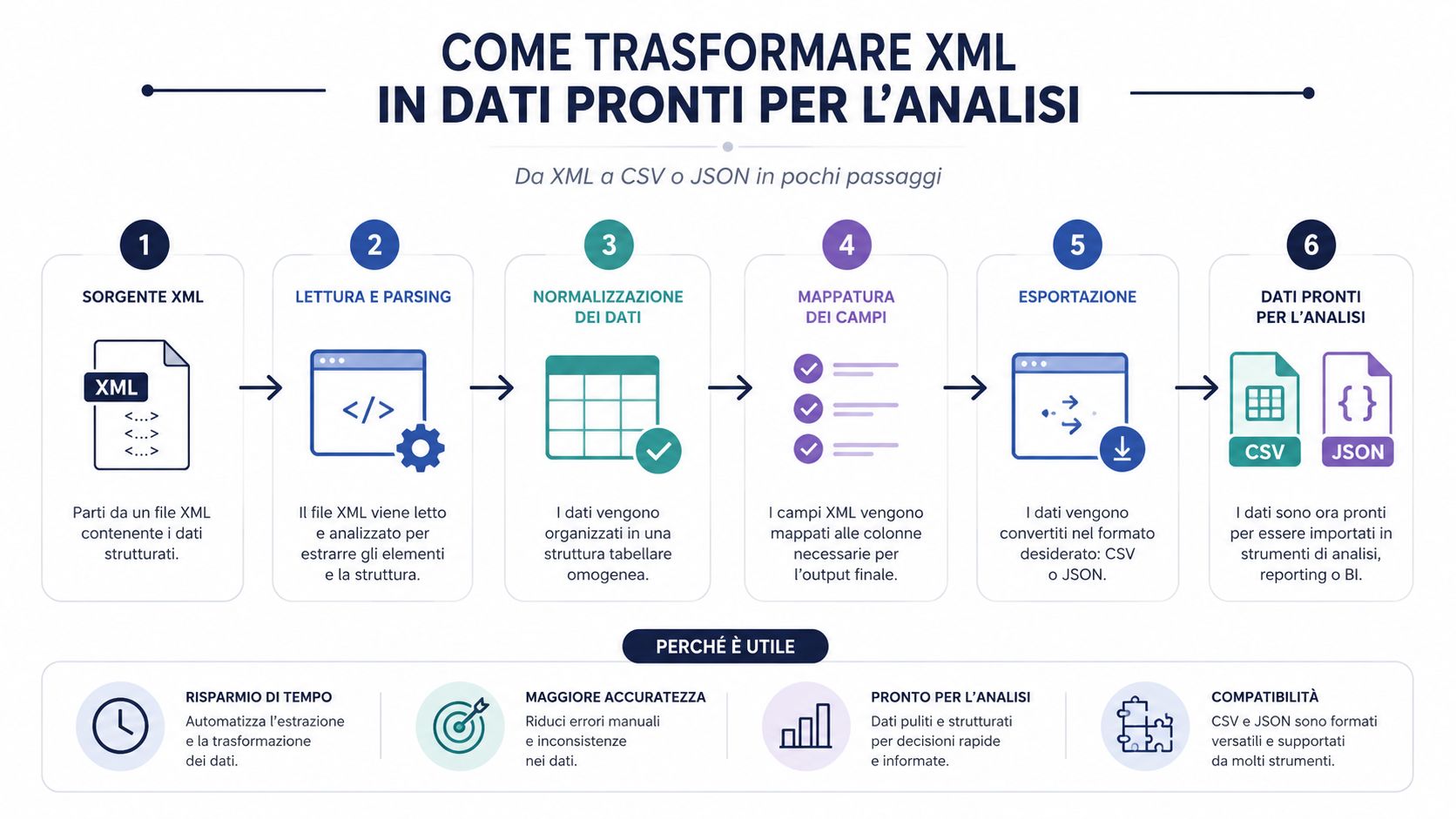
นี่คือจุดที่หลายกระบวนการมองข้ามไป ขวดคอคอขวดมักไม่ได้อยู่ที่การแยกวิเคราะห์เอง ไลบรารีที่ดีสามารถอ่าน XML ได้อย่างรวดเร็วมาก เวลาส่วนใหญ่ถูกใช้ไปกับการตีความโครงสร้าง การดึงข้อมูลที่เกี่ยวข้อง การทำความสะอาดและปรับข้อมูลให้เป็นมาตรฐาน และการโหลดข้อมูลเข้าสู่เครื่องมือวิเคราะห์
นั่นคือเหตุผลที่การแปลงเป็นCSVหรือJSONไม่ใช่แค่ความสะดวกเท่านั้น แต่เป็นขั้นตอนสำคัญในการดำเนินงาน หากคุณข้ามขั้นตอนนี้และทำงานกับไฟล์ดิบโดยตรง คุณมักจะจบลงด้วยการตรวจสอบด้วยตนเอง การสร้างคอลัมน์ชั่วคราว และตรรกะที่ยากต่อการทำซ้ำ
แหล่งข้อมูลที่เป็นประโยชน์สำหรับทุกคนที่ทำงานกับ XML และสเปรดชีตเป็นประจำคือคู่มือนี้เกี่ยวกับวิธีการถ่ายโอนข้อมูลจาก XML ไปยัง Excel ในรูปแบบที่เป็นระเบียบมากขึ้น
รูปแบบที่เหมาะสมขึ้นอยู่กับว่าคุณตั้งใจจะใช้ข้อมูลนั้นอย่างไรในภายหลัง
CSV ทำงานได้ดีเมื่อคุณต้องการหนึ่งแถวต่อเอกสาร หรือหนึ่งแถวต่อรายละเอียดใบแจ้งหนี้ จากนั้นใช้ Excel, Power Query หรือ BI
ตัวอย่างภาษา Python:
นำเข้า xml.etree.ElementTree เป็น ETimport csvtree = ET.parse("invoice.xml")root = tree.getroot()with open("invoices.csv", "w", newline="", encoding="utf-8") as f:writer = csv.writer(f)writer.writerow(["number", "date"])number = root.findtext(".//Numero")data = root.findtext(".//Data")writer.writerow([numero, data])ข้อได้เปรียบคือความง่ายของมัน ข้อเสียคือคุณต้องตัดสินใจอย่างรอบคอบว่าจะทำให้ลำดับชั้นแบนราบอย่างไร หากใบแจ้งหนี้มีรายการหลายรายการ คุณต้องตัดสินใจอย่างชัดเจนเกี่ยวกับความละเอียดและกุญแจการเชื่อมต่อ
JSON เหมาะที่สุดเมื่อคุณต้องการเก็บรักษาส่วนหนึ่งของโครงสร้างลำดับชั้น
ตัวอย่าง JavaScript:
const record = {numero: "123",data: "2024-01-15",righe: [{ descrizione: "Servizio", importo: "100.00" }]};console.log(JSON.stringify(record, null, 2));ใช้เมื่อคุณต้องการดำเนินการขั้นตอนต่อไปที่เกี่ยวข้องกับ API, data lake หรือแอปพลิเคชันที่ทำงานได้ดีกับวัตถุที่ซ้อนกัน
นี่คือกฎง่ายๆ ที่ควรจำไว้:
ไฟล์ XML เป็นตัวบรรจุ. CSV และ JSON คือรูปแบบที่ทำให้เนื้อหาสามารถใช้งานได้จริง.
หากคุณต้องการลดระยะเวลาในการได้มาซึ่งข้อมูลเชิงลึก นี่คือจุดที่คุณควรทุ่มเทความพยายาม ไม่ใช่การหาเครื่องมือแสดงผลที่ใช้งานง่ายกว่า แต่เป็นการกำหนดกระบวนการแปลงข้อมูลที่มั่นคงและสามารถทำซ้ำได้
เมื่อไฟล์ถูกอ่าน ตรวจสอบความถูกต้อง และแปลงแล้ว ลักษณะของงานจะเปลี่ยนไป คุณไม่ต้องดิ้นรนกับแท็กอีกต่อไป คุณกำลังวิเคราะห์ต้นทุน ความผิดปกติ ผู้จัดหา หมวดหมู่การใช้จ่าย และแนวโน้มการดำเนินงานในที่สุด
ในทางปฏิบัติแล้ว ค่าไม่ได้อยู่ที่เวลาที่ใช้ในการแยกวิเคราะห์ แต่อยู่ที่เวลาที่ใช้ในการแปลงไฟล์ดิบให้กลายเป็นข้อมูลที่คุณสามารถนำไปใช้ได้ ด้วยกระบวนการทำงานแบบแมนนวล บุคคลต้องเปิดเอกสาร ทำความเข้าใจโครงสร้างของมัน แยกฟิลด์ ทำความสะอาดค่า ปรับให้ข้อความเป็นมาตรฐาน และจากนั้นสร้างรายงาน เป็นกระบวนการที่เปราะบาง
ตัวอย่างคลาสสิกใน FatturaPA คือช่องข้อความอิสระในDatiBeniServizi บริการเดียวกันสามารถอธิบายได้หลายวิธีโดยผู้ให้บริการที่แตกต่างกัน หากคุณนำเข้าข้อมูลนั้นโดยไม่มีการแมปที่สอดคล้องกัน การวิเคราะห์ตามหมวดหมู่ต้นทุนจะสร้างข้อมูลสรุปที่ไร้ความหมาย
ด้วยเหตุนี้ ก่อนที่จะใช้แพลตฟอร์มการวิเคราะห์ จำเป็นต้องมีชั้นเตรียมข้อมูล:
เมื่อขั้นตอนนี้ทำอย่างถูกต้อง แพลตฟอร์มการวิเคราะห์ใด ๆ ก็จะทำงานได้อย่างมีประสิทธิภาพมากขึ้น หากคุณต้องการสำรวจด้านการตัดสินใจและด้านการมองเห็นของขั้นตอนนี้อย่างลึกซึ้งขึ้น แหล่งข้อมูลเกี่ยวกับวิธีการสร้างเรื่องราวด้วยข้อมูลจะมีประโยชน์ เพราะมันแสดงให้เห็นว่าชุดข้อมูลที่สะอาดสามารถถูกเปลี่ยนให้กลายเป็นเรื่องราวที่มีประโยชน์สำหรับผู้ตัดสินใจได้อย่างไร
ณ จุดนี้ ไฟล์ XML จะไม่ถือเป็นปัญหาทางเทคนิคอีกต่อไป แต่จะกลายเป็นวัตถุดิบสำหรับข้อมูลเชิงลึก ชุดข้อมูลที่เตรียมไว้อย่างดีสามารถใช้เพื่อวิเคราะห์ค่าใช้จ่าย ติดตามแนวโน้ม ชี้ให้เห็นความไม่สอดคล้อง และระบุข้อยกเว้นได้
ในการเลือกแพลตฟอร์มที่เหมาะสมกับ 'ระยะสุดท้าย' นี้ อาจเป็นประโยชน์หากเปรียบเทียบสิ่งที่ซอฟต์แวร์วิเคราะห์ธุรกิจสมัยใหม่มีให้กับการทำงานแบบแมนนวลล้วนๆ ที่ใช้สเปรดชีตและตารางหมุน
เกณฑ์ที่ถูกต้องในที่นี้ไม่ใช่ 'มันสามารถเปิดไฟล์ XML ได้หรือไม่?' นั่นเป็นเพียงขั้นต่ำสุดเท่านั้น คำถามที่เกี่ยวข้องคืออีกเรื่องหนึ่ง:
| คำถาม | ทำไมมันถึงสำคัญ |
|---|---|
| ข้อมูลอยู่ในรูปแบบที่สะอาดแล้ว | หลีกเลี่ยงการสรุปอย่างเฉพาะเจาะจงจากข้อมูลที่ไม่ถูกต้อง |
| หมวดหมู่มีความสอดคล้องกัน | คุณเปรียบเทียบซัพพลายเออร์และช่วงเวลาจริง ๆ หรือไม่? |
| ความผิดปกติใด ๆ จะปรากฏให้เห็นทันที | ลดเวลาที่เสียไปกับการตรวจสอบด้วยตนเอง |
| รายงานนี้สามารถเข้าถึงได้โดยผู้เชี่ยวชาญด้านธุรกิจและการเงิน | เร่งกระบวนการตัดสินใจ |
ความแตกต่างระหว่างกระบวนการที่ยังไม่สมบูรณ์และกระบวนการที่สมบูรณ์แล้วไม่ได้อยู่ที่ความสามารถในการอ่านไฟล์ XML แต่อยู่ที่ความสามารถในการแปลงไฟล์เหล่านั้นให้เป็นฐานข้อมูลที่เชื่อถือได้ ซึ่งไม่บังคับให้ทีมต้องทำงานซ้ำเดิมทุกครั้ง
หากคุณต้องการอ่านไฟล์ XML ในลักษณะที่เป็นประโยชน์ต่อธุรกิจของคุณ ให้คำนึงถึงรายการตรวจสอบนี้ไว้ มันมีประโยชน์มากกว่าคำจำกัดความทางเทคนิคใด ๆ และช่วยให้คุณเลือกวิธีที่ถูกต้องโดยไม่ต้องเสียเวลา
อย่าใช้แนวทางเดิมเสมอไป เบราว์เซอร์, โปรแกรมแก้ไข และโปรแกรมดูเหมาะสำหรับการตรวจสอบอย่างรวดเร็วเท่านั้น ส่วนพาร์เซอร์และสคริปต์จำเป็นต้องใช้เมื่อไฟล์ต้องถูกป้อนเข้าสู่กระบวนการที่ทำซ้ำ ๆ หากคุณสับสนระหว่างการนำเสนอข้อมูลกับการประมวลผลข้อมูล คุณเสี่ยงที่จะสร้างรายงานบนพื้นฐานที่ไม่มั่นคง
ไฟล์ .xml.p7m ต้องการขั้นตอนเฉพาะในกระบวนการจัดการลายเซ็น หากเนื้อหาดังกล่าวมาจาก PEC การตรวจสอบนี้ไม่ใช่เพียงเรื่องบังเอิญเท่านั้น แต่เป็นส่วนหนึ่งของการตีความเอกสารอย่างถูกต้อง
การยึดถือโครงสร้างข้อมูลไม่ได้รับประกันว่าชุดข้อมูลจะมีความถูกต้องสมบูรณ์ ความไม่สอดคล้องทางตรรกะ เช่น ยอดรวมที่ไม่ตรงกันหรือการจัดประเภทภาษีที่คลุมเครือ เป็นสาเหตุหลักที่บั่นทอนการวิเคราะห์ การตรวจสอบความถูกต้องเชิงความหมายคือสิ่งที่แยกความแตกต่างระหว่างไฟล์ที่ "ยอมรับได้" กับข้อมูลที่เชื่อถือได้
CSV และ JSON ไม่ใช่เพียงแค่การเปลี่ยนแปลงทางผิวเผินเท่านั้น แต่เป็นสิ่งที่ทำให้ XML สามารถใช้งานได้โดยเครื่องมือวิเคราะห์ข้อมูล, แผ่นข้อมูล, ระบบการประมวลผลแบบต่อเนื่อง, และรายงานต่าง ๆ ยิ่งคุณกำหนดการเปลี่ยนแปลงนี้ไว้เร็วเท่าใด คุณก็จะสามารถลดการทำงานด้วยตนเองและการแก้ไขปัญหาแบบฉุกเฉินได้เร็วขึ้นเท่านั้น
เป้าหมายของคุณไม่ใช่การอ่านไฟล์ XML แต่คือการได้รับข้อมูลเชิงลึกที่มีประโยชน์โดยไม่ทำให้ระบบเต็มไปด้วยข้อมูลที่ไม่สะอาด หากการไหลของข้อมูลไม่ได้สร้างชุดข้อมูลที่สม่ำเสมอ ปัญหาไม่ได้อยู่ที่แดชบอร์ดสุดท้าย แต่อยู่ไกลขึ้นไปในกระบวนการต้นน้ำมากกว่า
ในทางปฏิบัติ คุณสามารถใช้รายการตรวจสอบย่อยนี้ก่อนเริ่มโครงการใหม่ใด ๆ:
หากคุณต้องการเปลี่ยนข้อมูลที่พร้อมใช้งานให้กลายเป็นข้อมูลเชิงลึกที่ชัดเจนและนำไปปฏิบัติได้ELECTEช่วย SMEs ให้สามารถเปลี่ยนจากชุดข้อมูลที่สะอาดไปสู่การรายงานที่ชาญฉลาด โดยใช้วิธีการที่เข้าถึงได้แม้กระทั่งทีมที่ไม่มีความเชี่ยวชาญทางเทคนิค นี่คือวิธีที่รวดเร็วที่สุดในการเชื่อมช่องว่างระหว่างข้อมูลการดำเนินงานกับการตัดสินใจ

.svg)
.svg)
.svg)
.webp)





