

ข้อมูลของคุณกำลังเล่าเรื่องราวอยู่แล้ว ปัญหาคือมันมักจะพูดเบาเกินไป
ทุกวัน ธุรกิจขนาดกลางและขนาดย่อม (SME) จะรวบรวมข้อมูลจากลูกค้า เช่น ข้อเสนอแนะ คำสั่งซื้อ ตั๋วสนับสนุน การทำธุรกรรมทางการเงิน อีเมลการขาย และบันทึกใน CRM ข้อมูลทั้งหมดนี้มีข้อมูลเชิงลึกที่มีประโยชน์ บางส่วนบ่งชี้ว่าลูกค้าอาจกำลังจะเลิกใช้บริการ ขณะที่บางส่วนบ่งชี้ถึงความเสี่ยงในการดำเนินงาน และบางส่วนเปิดเผยว่าสินค้าใดกำลังจะได้รับความนิยมหรือกำลังจะสูญเสียแรงผลักดัน อย่างไรก็ตาม หากไม่มีวิธีการที่ชัดเจน ข้อมูลเชิงลึกเหล่านี้ก็จะกลายเป็นเพียงเสียงรบกวนเท่านั้น
ในบรรดาอัลกอริทึมที่ช่วยจัดระเบียบความวุ่นวายนี้ตัวจำแนกประเภทแบบเบย์เซียนไร้เดียงสา (Naive Bayesian) ถือว่ามีบทบาทพิเศษ พวกมันมีตรรกะที่เรียบง่าย ฝึกฝนได้อย่างรวดเร็ว และมักมีประสิทธิภาพมากกว่าที่ชื่อ 'ไร้เดียงสา' จะบ่งบอก พวกมันไม่ใช่ตัวเลือกที่เหมาะสมสำหรับทุกสถานการณ์ แต่ในปัญหาทางธุรกิจในโลกจริงหลายกรณี พวกมันมอบสมดุลที่หายากระหว่างความเร็ว ความสามารถในการตีความ และผลลัพธ์ที่มีประโยชน์
หากคุณทำงานในโลกธุรกิจ คุณไม่จำเป็นต้องเป็นนักวิจัยเพื่อที่จะเข้าใจพวกเขา คุณเพียงแค่ต้องรู้ว่าพวกเขาทำอะไร ทำไมพวกเขาถึงทำงานได้ดีแม้ว่าจะทำให้ความเป็นจริงดูง่ายขึ้นมาก และในสถานการณ์ใดที่พวกเขาสามารถช่วยคุณตัดสินใจได้ดีขึ้น นี่คือจุดที่ควรหยุดคิดพิจารณาอย่างถี่ถ้วน
หลายบริษัทมองหาแบบจำลองที่ซับซ้อนเกินไป ในขณะที่สิ่งที่ปัญหาต้องการอย่างแท้จริงนั้น คือแบบจำลองที่เชื่อถือได้และใช้งานง่ายเป็นอันดับแรก ด้วยเหตุนี้เอง ในวงการการเงิน ค้าปลีก หรือการดูแลลูกค้า แนวทางที่ชัดเจนที่สุดมักจะเป็นผู้ชนะ ไม่ใช่แนวทางที่ดูสวยงามที่สุดในทางทฤษฎี
ตัวจำแนกเบย์เซียนแบบไร้เดียงสา (Naive Bayesian classifiers)มีพื้นฐานมาจากแนวคิดที่ใช้งานได้จริงอย่างมาก หากคุณมีเบาะแสบางอย่างเกี่ยวกับกรณีใหม่ คุณสามารถประมาณได้ว่ากรณีนั้นน่าจะอยู่ในหมวดหมู่ใด หากอีเมลมีคำบางคำ อาจเป็นสแปม หากธุรกรรมแสดงรูปแบบบางอย่าง อาจต้องตรวจสอบเพิ่มเติม หากรีวิวใช้คำศัพท์บางคำ อาจบ่งบอกถึงความพึงพอใจหรือไม่พึงพอใจ
คำว่า 'เบย์เซียน' มักทำให้นึกถึงสูตรที่ซับซ้อน แต่ในความเป็นจริง แก่นแท้ของวิธีนี้คือความเข้าใจง่าย คุณนำสิ่งที่คุณรู้อยู่แล้วมาเพิ่มหลักฐานใหม่ แล้วปรับปรุงการตัดสินใจของคุณ มันเป็นวิธีการที่มีโครงสร้างในการให้เหตุผลภายใต้ความไม่แน่นอน – ซึ่งเป็นสิ่งที่ผู้จัดการทำทุกวัน เพียงแต่ถูกทำให้เป็นระบบด้วยอัลกอริทึม
สิ่งที่น่าประหลาดใจคือวิธีการนี้ยังคงทำงานได้ดีแม้ในสภาพแวดล้อมสมัยใหม่ที่มีข้อมูลจำนวนมหาศาลและการตัดสินใจที่รวดเร็ว ไม่ใช่เพราะมันอธิบายโลกได้อย่างสมบูรณ์แบบ แต่เพราะมันแยกสัญญาณที่มีประโยชน์ออกจากสัญญาณรบกวนด้วยต้นทุนการคำนวณที่ต่ำมาก
เมื่อพูดถึงปัญหาทางธุรกิจ คำถามที่ถูกต้องไม่ใช่ "โมเดลใดที่ซับซ้อนที่สุด?" แต่เป็น "โมเดลใดที่ให้ผลลัพธ์ที่เชื่อถือได้ภายในกรอบเวลาที่สามารถนำไปใช้ได้จริงในโลกแห่งความเป็นจริง?"
นั่นคือเหตุผลที่ตัวจำแนกประเภทแบบเบย์เซียนแบบไร้เดียงสา (Naive Bayesian) ยังคงมีความสำคัญ พวกมันช่วยให้คุณจำแนก แยกแยะ แบ่งส่วน และจัดลำดับความสำคัญ และพวกมันยังช่วยให้คุณนำความน่าจะเป็นเข้าไปในกระบวนการตัดสินใจได้ โดยไม่ต้องทำให้ทุกโครงการกลายเป็นฝันร้ายทางเทคนิค
หลักการพื้นฐานคือทฤษฎีบทของเบย์ กล่าวอย่างง่ายคือ มันทำงานดังนี้: คุณเริ่มต้นด้วยความน่าจะเป็นเริ่มต้น จากนั้นปรับปรุงมันเมื่อมีข้อมูลใหม่เข้ามา
ในทางสถิติ สูตรนี้เขียนได้ดังนี้:P(y|x) ∝ P(y) ⋅ ∏ P(x_i|y) ซึ่งหมายความว่าความน่าจะเป็นของคลาสหนึ่งเมื่อพิจารณาจากชุดข้อมูลสังเกตการณ์ขึ้นอยู่กับสองปัจจัย ปัจจัยแรกคือความน่าจะเป็นเบื้องต้นของคลาสนั้น ปัจจัยที่สองคือระดับที่แต่ละข้อมูลสังเกตการณ์สอดคล้องกับคลาสดังกล่าว
มาดูตัวอย่างทางธุรกิจกัน คุณต้องตัดสินใจว่าอีเมลนี้เป็นสแปมหรือไม่ คุณมีความน่าจะเป็นทั่วไปว่าอีเมลที่เข้ามาเป็นสแปม จากนั้นคุณค้นหาคำบางคำเช่น 'ข้อเสนอ', 'ฟรี' หรือ 'คลิกที่นี่' คำแต่ละคำเหล่านี้มีอิทธิพลต่อการตัดสินใจในท้ายที่สุด
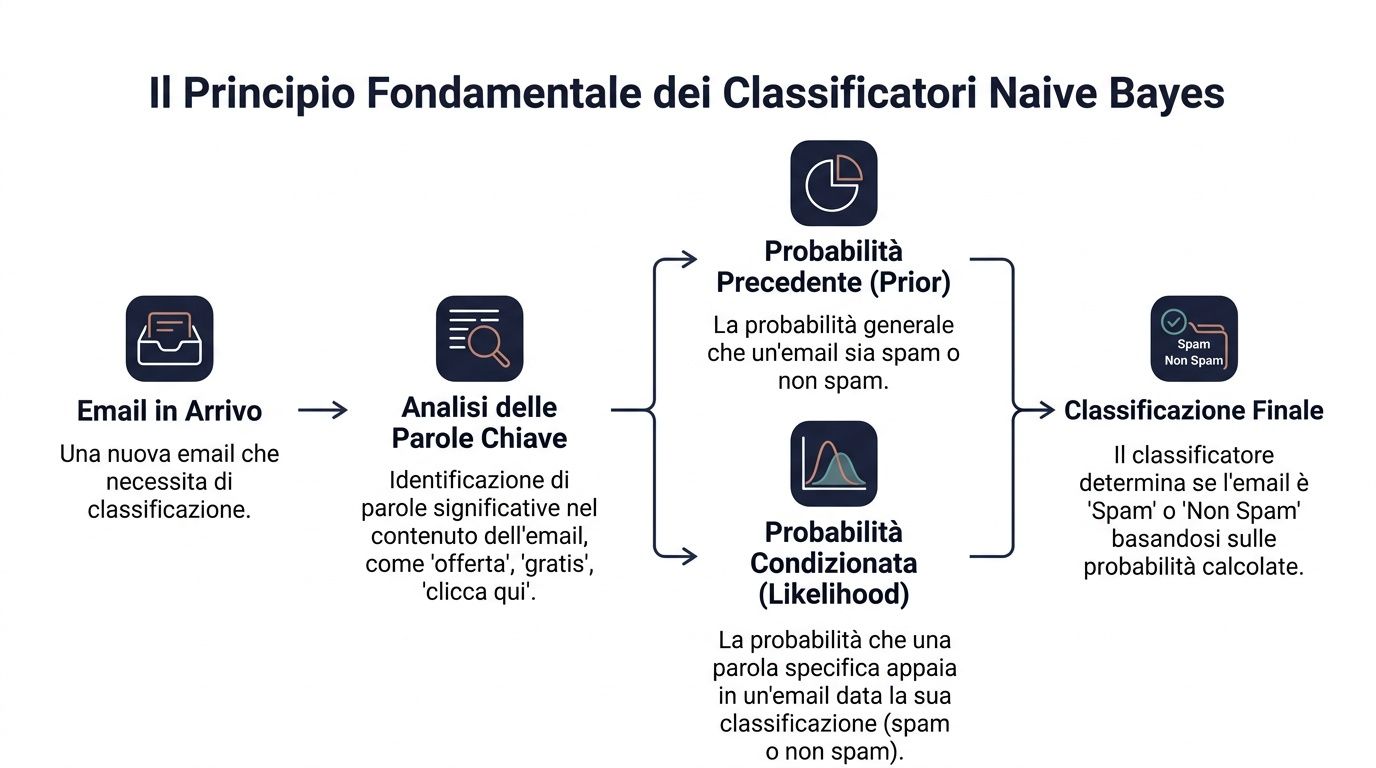
ผู้จัดการทำสิ่งที่คล้ายกันทุกวัน พวกเขาไม่เคยตัดสินใจในสุญญากาศ พวกเขาเริ่มต้นด้วยบริบทพื้นฐานและสร้างต่อจากนั้น ลูกค้าที่ซื้อสินค้าเป็นประจำจะมีโปรไฟล์เริ่มต้นที่แน่นอน หากพวกเขาหยุดเปิดอีเมล ลดมูลค่าการสั่งซื้อ และเปิดตั๋วสนับสนุนที่สำคัญ การประเมินของคุณก็จะเปลี่ยนไป
คำว่า'ไร้เดียงสา'หมายถึงสมมติฐานเฉพาะอย่างหนึ่ง แบบจำลองนี้ถือว่าลักษณะต่างๆ เป็นอิสระจากกันและกัน โดยถือว่าคลาสเป็นที่ทราบแล้ว
ในทางปฏิบัติ เมื่อทำการจัดประเภทอีเมล ให้ถือว่าแต่ละคำเป็นเบาะแสแยกกัน อย่าพยายามสร้างแบบจำลองความสัมพันธ์ที่ซับซ้อนทั้งหมดระหว่างคำต่างๆ นี่เป็นการทำให้ง่ายขึ้นอย่างมีนัยสำคัญ ในความเป็นจริง คำหลายคำปรากฏร่วมกันและพฤติกรรมทางธุรกิจหลายอย่างมีความสัมพันธ์กัน
อย่างไรก็ตาม การเลือกเช่นนี้เองที่ทำให้แบบจำลองมีน้ำหนักเบาอย่างมาก มันไม่จำเป็นต้องเรียนรู้เครือข่ายของความสัมพันธ์ที่ซับซ้อน มันเพียงแค่ประมาณค่าความน่าจะเป็นที่ง่ายกว่า และรวมค่าเหล่านั้นอย่างมีประสิทธิภาพ
กฎทั่วไป:Naive Bayes ไม่ได้พยายามจำลองโลกทั้งใบ แต่มุ่งเน้นที่จะตัดสินใจอย่างมีประสิทธิภาพโดยอาศัยข้อสมมติเพียงไม่กี่ข้อและด้วยความรวดเร็วสูง
นี่คือจุดที่มักเกิดความเข้าใจผิดขึ้นบ่อยครั้ง หลายคนอ่านคำว่า 'สมมติฐานที่ไร้เดียงสา' แล้วสรุปว่านั่นคือ 'โมเดลที่อ่อนแอ' ซึ่งไม่ใช่กรณีนี้ โมเดลสามารถถูกทำให้เรียบง่ายอย่างมากและยังคงมีความแข็งแกร่งได้ หากการทำให้เรียบง่ายนั้นสะท้อนถึงสิ่งที่สำคัญต่อภารกิจการตัดสินใจ
ในปี 2004 การวิเคราะห์เชิงทฤษฎีได้ให้หลักฐานที่มั่นคงสำหรับประสิทธิภาพของตัวจำแนก Naive Bayes แม้ว่าจะมีการสมมติฐานเรื่องความเป็นอิสระก็ตาม พร้อมทั้งอธิบายว่าเหตุใดจึงสามารถไปถึงอัตราความผิดพลาดแบบลิมิตได้เร็วกว่าการถดถอยโลจิสติก ในการประยุกต์ใช้ในลักษณะเดียวกัน ในการกรองสแปม พวกมันสามารถบรรลุความแม่นยำเกินกว่า 99%และสามารถขยายไปยังเอกสารหลายล้านฉบับ ตามที่ได้อธิบายไว้ในรายการเกี่ยวกับตัวจำแนก Naive Bayes
ประเด็นนี้มีความสำคัญสำหรับกลุ่มผู้ฟังที่เป็นธุรกิจ. คุณค่าของอัลกอริทึมไม่ได้อยู่ที่คะแนนสุดท้ายเพียงอย่างเดียว. แต่ยังอยู่ที่ความสามารถในการฝึกฝนอย่างรวดเร็ว, ปรับตัวกับชุดข้อมูลขนาดใหญ่, และยังคงสามารถตีความได้.
เมื่อคุณมีข้อความ, หมวดหมู่, แท็ก หรือสัญญาณที่กระจัดกระจายอยู่, ตัวจำแนกแบบเบย์เซียนบริสุทธิ์ทำงานได้ดีเพราะ:
อย่างไรก็ตาม มีสองประเด็นที่ควรคำนึงถึง
ด้วยเหตุนี้ Naive Bayes ควรถูกมองว่าเป็นเครื่องมือที่มีประสิทธิภาพสูงสำหรับงานจำแนกประเภทอย่างรวดเร็ว มากกว่าที่จะเป็นไม้กายสิทธิ์ที่สามารถใช้ได้กับทุกสถานการณ์ อย่างไรก็ตาม ในบริบททางปฏิบัติหลายประการ มันเป็นหนึ่งในวิธีที่ชาญฉลาดที่สุดในการเริ่มต้น
ข้อผิดพลาดที่พบบ่อยคือการพูดถึง Naive Bayes ราวกับว่าเป็นโมเดลเดียวที่เหมือนกันในทุกสถานการณ์ ในความเป็นจริงแล้ว มีรูปแบบที่แตกต่างกัน ซึ่งออกแบบมาสำหรับข้อมูลประเภทต่างๆ
การเลือกที่เหมาะสมขึ้นอยู่กับรูปแบบของข้อมูลที่คุณมี หากคุณเลือกตัวเลือกที่ไม่ถูกต้อง โมเดลอาจยังคงสร้างการคาดการณ์ได้ แต่จะไม่ใช้วิธีที่เหมาะสมที่สุดกับปัญหาของคุณ
Gaussian Naive Bayesเป็นรูปแบบที่เหมาะสมที่สุดเมื่อคุณลักษณะเป็นแบบต่อเนื่อง ลองนึกถึงจำนวนเงินเฉลี่ยต่อธุรกรรม อายุของลูกค้า ระยะเวลาเฉลี่ยระหว่างการซื้อสองครั้ง กำไรต่อหน่วย หรือมูลค่าใบเสร็จรับเงิน
ที่นี่ โมเดลสมมติว่าค่าต่าง ๆ ภายในแต่ละคลาสมีการกระจายตัวตามการแจกแจงแบบเกาส์เซียน คุณไม่ควรคิดว่านี่เป็นข้อจำกัดทางวิชาการ เพียงแต่ให้คำนึงถึงแนวคิดในทางปฏิบัติคือ สำหรับแต่ละคลาส โมเดลจะประมาณค่าเฉลี่ยและค่าเบี่ยงเบนมาตรฐานที่เป็นตัวแทน
แนวทางนี้มีประโยชน์เมื่อคุณต้องการจำแนกกรณีต่างๆ เช่น:
ในการทดสอบประสิทธิภาพของ scikit-learn โดยใช้ชุดข้อมูลที่คล้ายกับข้อมูลอีคอมเมิร์ซของอิตาลี โมเดล Naive Bayesสามารถทำค่าความแม่นยำได้ 95% จากตัวอย่าง 1,000 ชุด โดยใช้เวลาฝึกฝนเร็วกว่าโลจิสติกเรเกรสชัน15% การเปรียบเทียบที่ให้ไว้คือ0.01 วินาที เทียบกับ 0.1 วินาที บน CPU มาตรฐาน ด้วยการฝึกแบบปิดรูปแบบ (closed-form training) ดังที่แสดงในบทของ Jake VanderPlasเกี่ยวกับการจำแนกประเภท Naive Bayes อย่างละเอียด
สำหรับธุรกิจแล้ว ประเด็นไม่ได้อยู่ที่จุดทศนิยม สิ่งสำคัญคือสายพันธุ์นี้สามารถให้ผลลัพธ์ที่ดีได้โดยไม่ต้องใช้เวลาฝึกอบรมนานหรือมีโครงสร้างพื้นฐานที่ซับซ้อน
หากคุณกำลังทำงานกับข้อความ, ตั๋ว, รีวิว หรือความคิดเห็น,Multinomial Naive Bayesมักจะเป็นตัวเลือกที่ชัดเจน. ในที่นี้, คุณลักษณะคือจำนวนหรือความถี่. ในทางปฏิบัติ, แบบจำลองจะตรวจสอบว่าคำหรือคำศัพท์ปรากฏบ่อยเพียงใด.
มันคือสถานการณ์คลาสสิกของ:
เหตุผลที่มันทำงานได้ดีมากนั้นค่อนข้างตรงไปตรงมา แม้ว่าคำศัพท์ในเอกสารทางธุรกิจอาจมีความหลากหลายมาก แต่เอกสารแต่ละชิ้นจะมีเพียงส่วนน้อยของคำที่เป็นไปได้ทั้งหมด ข้อมูลถูกกระจายอยู่ทั่วไป Multinomial Naive Bayes จัดการกับโครงสร้างประเภทนี้ได้ดีเป็นพิเศษ
ในการศึกษาทวีตภาษาอิตาลีจำนวน 100,000 ข้อความที่ติดป้ายกำกับด้านความรู้สึก ตัวจำแนกประเภท Multinomial Naive Bayes ทำคะแนน F1 ได้ 0.88 และเร็วกว่าSVMถึง 10 เท่าตามที่รายงานไว้ในคู่มือของ GeeksforGeeksเกี่ยวกับตัวจำแนกประเภท Naive Bayes
เพื่อช่วยให้คุณจำสิ่งนี้ได้ ลองนึกภาพว่า: หากข้อมูลของคุณดูเหมือนเอกสารที่เต็มไปด้วยคำที่ถูกนับไว้ แบบจำลองมัลติโนเมียลจะเป็นตัวเลือกแรกที่ควรลองเกือบทุกครั้ง
หากบริษัทของคุณต้องการประมวลผลข้อความในปริมาณมาก คำถามไม่ใช่แค่ "โมเดลมีความแม่นยำแค่ไหน?" เท่านั้น แต่ยังรวมถึง "โมเดลสามารถประมวลผลคำขอได้กี่รายการโดยไม่ทำให้ทีมทำงานช้าลง?"
Bernoulli Naive Bayesทำงานกับคุณลักษณะแบบไบนารี มันไม่สนใจว่าสัญญาณปรากฏกี่ครั้ง แต่จะนับเพียงว่ามีอยู่หรือไม่มีอยู่เท่านั้น
ตัวแปรนี้มีประโยชน์เมื่อการมีอยู่ของแอตทริบิวต์มีความสำคัญมากกว่าความถี่ของมัน ตัวอย่างทางธุรกิจ:
แนวทางนี้มีประโยชน์มากเมื่อคุณต้องการแยกแยะปรากฏการณ์ที่ซับซ้อนออกเป็นตัวชี้วัดแบบง่าย ๆ ที่ตอบได้เป็นใช่/ไม่ใช่ ซึ่งสามารถติดตามได้ง่าย ในการวิเคราะห์ความรู้สึก ตัวอย่างเช่น การมีอยู่ของคำที่เป็นลบเพียงคำเดียวอาจมีความสำคัญมากกว่าจำนวนครั้งที่คำนั้นถูกกล่าวซ้ำ
Bernoulli ไม่ได้ 'ซับซ้อนน้อยกว่า' การแจกแจงแบบพหุนาม มันเพียงแค่เหมาะสมกว่าเมื่อข้อมูลอธิบายถึงการมีอยู่หรือไม่มีอยู่ ความแตกต่างนี้ละเอียดอ่อนในทฤษฎี แต่มีความสำคัญในทางปฏิบัติ
| ตัวแปร | ประเภทข้อมูลที่เหมาะสม | ตัวอย่างกรณีการใช้งานทางธุรกิจ |
|---|---|---|
| เกาส์เซียน ไนฟ์ เบย์ | ข้อมูลต่อเนื่อง | จัดประเภทธุรกรรมตามความเสี่ยงโดยใช้จำนวนเงิน ความถี่ และค่าเฉลี่ย |
| มัลติโนเมียล ไนฟ์ เบย์ส์ | ข้อความ, จำนวน, ความถี่ | วิเคราะห์รีวิวของลูกค้าและตั๋วตามความรู้สึกหรือหมวดหมู่ |
| Bernoulli Naive Bayes | ข้อมูลแบบไบนารี, มี/ไม่มี | ประเมินสัญญาณใช่/ไม่ใช่ที่เกี่ยวข้องกับการปฏิบัติตามข้อกำหนด การสนับสนุน หรือการใช้งานผลิตภัณฑ์ |
ในการตัดสินใจที่ถูกต้อง ให้ปฏิบัติตามกฎง่าย ๆ นี้:
หลายทีมติดขัดเพราะพวกเขากำลังมองหาแบบจำลองที่ 'ดีที่สุด' อย่างแท้จริง เกือบทุกครั้ง ทางเลือกที่ถูกต้องคือแบบจำลองที่เหมาะกับประเภทของข้อมูลมากที่สุด
ข่าวดีก็คือการนำ Naive Bayes ไปใช้ในทางปฏิบัติไม่จำเป็นต้องเป็นโครงการขนาดใหญ่ แม้แต่ต้นแบบที่เรียบง่ายก็เพียงพอที่จะเข้าใจว่าโมเดลนี้ทำงานอย่างไรและต้องการข้อมูลอะไรบ้าง

ตัวจำแนกประเภทมักจะถูกสร้างขึ้นในสี่ขั้นตอนเสมอ
การเตรียมข้อมูล
คุณจำเป็นต้องรวบรวมตัวอย่างในอดีตที่ได้ถูกติดป้ายกำกับไว้แล้ว หากคุณกำลังจำแนกประเภทรีวิว คุณจำเป็นต้องมีข้อความที่ได้ถูกทำเครื่องหมายว่าเป็นเชิงบวกหรือเชิงลบแล้ว หากคุณกำลังวิเคราะห์ความเสี่ยงในการดำเนินงาน คุณจำเป็นต้องมีกรณีในอดีตที่มีผลลัพธ์ที่ทราบแล้ว
การฝึกอบรมโมเดล
โมเดลจะตรวจสอบข้อมูลและประมาณความน่าจะเป็นที่เกี่ยวข้อง ในตัวจำแนกประเภทแบบเบย์เซียนแบบไร้เดียงสา ขั้นตอนนี้จะรวดเร็วเนื่องจากขั้นตอนการฝึกอบรมไม่จำเป็นต้องมีการปรับค่าให้เหมาะสมที่ใช้ทรัพยากรมากเป็นพิเศษ
การทำนายกรณีใหม่กรอกข้อมูลใหม่และโมเดลจะกำหนดคลาสให้ ตัวอย่างเช่น "สแปม", "ไม่ใช่สแปม", "ลูกค้าเสี่ยง", "ลูกค้าที่มั่นคง"
การประเมินผล
: เปรียบเทียบการคาดการณ์กับข้อมูลจริงบนชุดทดสอบแยกต่างหาก ที่นี่ คุณไม่ได้เพียงแค่ตรวจสอบว่าโมเดลทำงานได้หรือไม่ แต่คุณกำลังดูว่ามันทำผิดพลาดอย่างไร
หากคุณต้องการทำความเข้าใจภาพรวมที่กว้างขึ้นของวิธีการทำนาย บทสรุปของอัลกอริทึมการเรียนรู้ของเครื่องนี้จะช่วยให้คุณเข้าใจตำแหน่งของ Naive Bayes ในกลุ่มวิธีการที่กว้างขึ้น
เพื่ออธิบายกระบวนการนี้ นี่คือตัวอย่างง่าย ๆ โดยใช้ scikit-learn คุณไม่จำเป็นต้องอ่านในฐานะนักพัฒนา เพียงแค่เข้าใจขั้นตอนการทำงานก็เพียงพอแล้ว
# นำเข้าเครื่องมือหลักจาก sklearn.datasets import load_iris จาก sklearn.model_selection import train_test_split จาก sklearn.naive_bayes import GaussianNB จาก sklearn.metrics import accuracy_score# โหลดชุดข้อมูลตัวอย่าง X, y = load_iris(return_X_y=True)# ให้เราแบ่งข้อมูลออกเป็นชุดฝึกอบรมและชุดทดสอบ X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# สร้างโมเดล modelmodel = GaussianNB()# ฝึกโมเดลด้วยข้อมูลในอดีต model.fit(X_train, y_train)# ทำนายข้อมูลที่ไม่เคยเห็นมาก่อน y_pred = model.predict(X_test)# วัดความแม่นยำ print(accuracy_score(y_test, y_pred))ข้อความนี้มีความหมายมากกว่าที่ปรากฏ
GaussianNB() เลือกตัวเลือกสำหรับข้อมูลต่อเนื่องฟิต () นี่คือช่วงเวลาที่โมเดลเรียนรู้ทำนาย() นำสิ่งที่เขาได้เรียนรู้ไปปฏิบัติaccuracy_score() ตรวจสอบจำนวนการจัดประเภทที่ถูกต้องทั้งหมดสำหรับข้อมูลข้อความ กระบวนการจะคล้ายกัน แต่ก่อนนำโมเดลไปใช้ คุณจำเป็นต้องแปลงข้อความเป็นตัวเลขเสียก่อน ในทางปฏิบัติ ขั้นตอนนี้คือการเปลี่ยนคำต่าง ๆ ให้กลายเป็นคุณลักษณะที่สามารถนำไปใช้กับตัวจำแนกประเภทได้
หลังจากที่ได้ดูโค้ดอย่างรวดเร็ว อาจเป็นประโยชน์ที่จะเห็นคำอธิบายแบบภาพว่ามันทำงานอย่างไร
แบบจำลองแรกไม่ได้มีจุดประสงค์เพื่อแสดงให้เห็นถึงความสมบูรณ์แบบ แต่มีจุดประสงค์เพื่อตอบคำถามเชิงปฏิบัติสามข้อ
นี่คือจุดที่ความแข็งแกร่งของ Naive Bayes โดดเด่นอย่างแท้จริง คุณสามารถสร้างพื้นฐานที่มั่นคงได้อย่างรวดเร็ว จากนั้นจึงประเมินได้ว่าควรเพิ่มความซับซ้อนให้กับโครงการหรือว่าวิธีแก้ปัญหาที่เรียบง่ายนั้นสามารถสร้างคุณค่าได้แล้ว
แบบจำลองการจัดหมวดหมู่ไม่ได้ถูกตัดสินเพียงแค่ว่ามัน 'ดูเหมือนจะทำงานได้' เท่านั้น แต่ถูกตัดสินจากจำนวนครั้งที่มันทำผิดพลาด และจากความผิดพลาดเหล่านั้นมีผลกระทบต่อธุรกิจมากน้อยเพียงใด

ความถูกต้องเป็นเกณฑ์ที่เข้าใจได้ง่ายที่สุด มันบอกคุณว่ามีการทำนายถูกต้องกี่ครั้งจากทั้งหมด มันมีประโยชน์ แต่หากใช้เพียงอย่างเดียวอาจทำให้เข้าใจผิดได้
หากมีเพียงไม่กี่รายการจากหนึ่งร้อยรายการเท่านั้นที่น่าสงสัยจริง ๆ โมเดลที่จัดประเภทเกือบทุกอย่างว่าปกติอาจดูเหมือนมีประสิทธิภาพดีในแง่ของความแม่นยำ แต่กลับยังขาดประสิทธิภาพในจุดที่สำคัญจริง
เพื่อเข้าใจสิ่งนี้ ให้คิดถึงตาข่ายจับปลา
ในธุรกิจ ความแตกต่างนี้มีความสำคัญอย่างมาก
โมเดลที่ดีไม่ใช่โมเดลที่ทำผิดพลาดน้อยโดยทั่วไป แต่เป็นโมเดลที่ทำผิดพลาดในลักษณะที่มีค่าใช้จ่ายต่ำที่สุดต่อกระบวนการของคุณ
เพื่อทำความเข้าใจเพิ่มเติมเกี่ยวกับวิธีที่อัลกอริทึมเรียนรู้จากข้อมูลในอดีตและเหตุผลที่คุณภาพของการฝึกอบรมส่งผลต่อผลลัพธ์สุดท้าย คุณสามารถอ่านบทความเชิงลึกนี้เกี่ยวกับการฝึกอบรมอัลกอริทึมได้
เบย์ส์แบบไร้เดียงสาเป็นวิธีที่เรียบง่าย แต่ไม่สามารถทนต่อข้อผิดพลาดบางประการที่เกิดขึ้นในทางปฏิบัติได้
ข้อผิดพลาดแรก: การละเลยปัญหาการนับเป็นศูนย์
หากคำหรือค่าใดไม่เคยปรากฏในข้อมูลการฝึกฝนสำหรับคลาสใดคลาสหนึ่ง ความน่าจะเป็นอาจลดลงเป็นศูนย์และทำให้การคำนวณผิดพลาดได้ นี่คือเหตุผลที่Laplace smoothing มักถูกใช้ เนื่องจากจะเพิ่มการปรับเล็กน้อยให้กับจำนวนนับ
ข้อผิดพลาดที่สอง: การใช้คุณลักษณะที่มีความสัมพันธ์สูง
หากสองคอลัมน์ให้ข้อมูลที่เกือบจะเหมือนกัน โมเดลมีความเสี่ยงที่จะประเมินสัญญาณสูงเกินไป โมเดลไม่ 'เข้าใจ' ว่าสองคุณลักษณะนั้นเกือบจะซ้ำกัน
ข้อผิดพลาดที่สาม: การไว้วางใจในความน่าจะเป็นดิบมากเกินไป
Naive Bayes มักทำงานได้ดีในงานจัดอันดับ แต่ความน่าจะเป็นของมันอาจมั่นใจเกินไป สำหรับธุรกิจ นี่หมายความว่า การจัดอันดับเองอาจมีประโยชน์ ในขณะที่ค่าความน่าจะเป็นที่แม่นยำควรถูกตีความด้วยความระมัดระวัง
เพื่อลดความเสี่ยงเหล่านี้ให้เหลือน้อยที่สุด ขอแนะนำให้:
คุณค่าที่แท้จริงของตัวจำแนกแบบเบย์เซียนไร้เดียงสาจะปรากฏชัดเมื่อคุณหยุดมองพวกมันเป็นเพียงการคำนวณทางคณิตศาสตร์ และเริ่มใช้พวกมันเป็นเครื่องมือสำหรับการจัดลำดับความสำคัญ ในธุรกิจ การจำแนกอย่างมีประสิทธิภาพเกือบจะหมายถึงการตัดสินใจที่ดีขึ้นเสมอ

ลองนึกภาพทีมการเงินที่กำลังวิเคราะห์กระแสธุรกรรม คำอธิบายการดำเนินงาน และข้อมูลในอดีต ทุกบรรทัดไม่ใช่แค่บันทึกธรรมดา แต่เป็นโอกาสในการตัดสินใจ: ปล่อยผ่านไป ตรวจสอบเพิ่มเติม ระงับไว้ หรือส่งต่อไปยังนักวิเคราะห์
ด้วย Naive Bayes คุณสามารถรวมตัวชี้วัดที่แตกต่างกันเข้าด้วยกันในการจัดประเภทเดียว บางตัวเป็นตัวเลข บางตัวเป็นแบบไบนารี และบางตัวเป็นข้อความ โมเดลนี้ช่วยในการระบุกรณีที่ใกล้เคียงกับรูปแบบที่เคยสังเกตเห็นว่าเป็นปกติหรือผิดปกติมากที่สุด
ประโยชน์ในทางปฏิบัติมีสองประการ:
มันไม่ได้มาแทนที่การตัดสินใจของมนุษย์ในบริบทที่มีการกำกับดูแล แต่มันช่วยจัดระเบียบการตัดสินใจเหล่านั้น และในกระบวนการปฏิบัติงานที่มีปริมาณงานสูง สิ่งนี้สร้างความแตกต่างอย่างแท้จริง
ในการตลาด การแบ่งกลุ่มมักเกี่ยวข้องกับการจัดกลุ่มลูกค้าแต่ละรายให้อยู่ในกลุ่มเฉพาะ เช่น ลูกค้าที่ภักดี ลูกค้าที่คำนึงถึงราคาเป็นหลัก ลูกค้าที่มีความเสี่ยงที่จะเลิกใช้บริการ ลูกค้าที่ตอบสนองต่อการส่งเสริมการขาย และลูกค้าที่ไม่ได้ใช้งาน
นี่คือจุดที่ Naive Bayes มีประโยชน์ เนื่องจากสามารถรวมสัญญาณที่หลากหลายได้อย่างรวดเร็ว:
ทีม CRM ไม่จำเป็นต้องมีทฤษฎีพฤติกรรมมนุษย์ที่สมบูรณ์แบบ สิ่งที่จำเป็นคือการแบ่งกลุ่มลูกค้าที่ดีพอที่จะกระตุ้นให้เกิดการกระทำที่เหมาะสม เช่น การเปลี่ยนข้อความ ความถี่ในการติดต่อ หรือประเภทของข้อเสนอ
เมื่อแบบจำลองช่วยเลือกข้อความต่อไปสำหรับลูกค้าที่เหมาะสม มันก็สร้างคุณค่าทางการดำเนินงานแล้ว
ในธุรกิจค้าปลีกและอีคอมเมิร์ซ การจัดหมวดหมู่เป็นรากฐานของกิจกรรมที่อาจดูแตกต่างกันแต่มีหลักการพื้นฐานเดียวกัน: การนำความเป็นระเบียบมาสู่ความวุ่นวาย
คุณสามารถจัดหมวดหมู่สินค้าตามประสิทธิภาพการขายได้ คุณสามารถอ่านรีวิวและตั๋วการสนับสนุนเพื่อระบุหมวดหมู่ที่ก่อให้เกิดปัญหาได้ คุณสามารถสังเกตเห็นรูปแบบของความต้องการที่ช่วยให้ทีมวางแผนการส่งเสริมการขายและระดับสต็อกได้อย่างมีประสิทธิภาพมากขึ้น
ในสภาพแวดล้อมประเภทนี้ ข้อมูลมักจะมีปริมาณมาก หลากหลาย และไม่สมบูรณ์แบบเสมอไป นั่นคือเหตุผลที่โมเดลซึ่งรวดเร็ว สามารถปรับขนาดได้ และอ่านง่าย จึงมีคุณค่าอย่างยิ่ง ไม่ใช่เพราะเป็นทางเลือกที่ดูหรูหราที่สุด แต่เพราะสามารถผสานเข้ากับกระบวนการทำงานได้อย่างไร้รอยต่อโดยไม่ทำให้ช้าลง
หากคุณต้องการดูว่าวิธีการวิเคราะห์ข้อมูลที่นำมาประยุกต์ใช้กับธุรกิจมีรูปแบบอย่างไรในโครงการจริง คุณสามารถดูกรณีศึกษาเหล่านี้ได้
การเข้าใจ Naive Bayes มีประโยชน์. การนำไปใช้อย่างมีประสิทธิภาพในบริบททางธุรกิจเป็นอีกเรื่องหนึ่ง.
ปัญหาแทบไม่เคยเกิดจากอัลกอริทึมเพียงอย่างเดียว งานที่แท้จริงอยู่ที่โมเดล คุณจำเป็นต้องเชื่อมโยงแหล่งข้อมูลที่แตกต่างกัน จัดการกับฟิลด์ที่ขาดหายไป เตรียมข้อความ ปรับปรุงป้ายกำกับ ตรวจสอบคุณภาพของผลลัพธ์ และนำเสนอผลลัพธ์ในรูปแบบที่ผู้ตัดสินใจสามารถเข้าใจได้
สำหรับธุรกิจขนาดกลางและขนาดย่อม (SME) ขั้นตอนนี้มักเป็นจุดที่ติดขัด ไม่ใช่เพราะขาดความสนใจใน AI แต่เป็นเพราะเวลาของทีมงานมีจำกัดและลำดับความสำคัญในการดำเนินงานไม่สามารถรอได้
นี่คือจุดที่เหมาะสมในการใช้แพลตฟอร์มที่จัดการกับความซับซ้อนทางเทคนิค โซลูชันที่ขับเคลื่อนด้วย AI ช่วยให้คุณสามารถเปลี่ยนข้อมูลดิบให้กลายเป็นข้อมูลเชิงลึกที่สามารถนำไปใช้ได้ โดยไม่ต้องให้ธุรกิจเขียนโค้ด เลือกไลบรารี หรือดูแลระบบอัตโนมัติ
แพลตฟอร์มเช่นELECTE ซึ่งเป็นแพลตฟอร์มวิเคราะห์ข้อมูลด้วยปัญญาประดิษฐ์สำหรับธุรกิจขนาดกลางและขนาดย่อม ทำให้วิธีการเช่นตัวจำแนกเบย์เซียนแบบไร้เดียงสาสามารถเข้าถึงได้โดยไม่ต้องมีความเชี่ยวชาญเฉพาะทางในด้านการเรียนรู้ของเครื่อง ผลประโยชน์ไม่ใช่เพียงแค่ความเร็วเท่านั้น แต่ยังเป็นการลดความขัดแย้งระหว่างข้อมูลกับการตัดสินใจ
เมื่อระบบอัตโนมัติทำงานได้ดี ทีมงานจะไม่คิดในแง่ของสูตรอีกต่อไป แต่จะคิดในแง่ของคำถามที่มีประโยชน์แทน:
นี่คือเหตุผลว่าทำไมบริษัทต่างๆ จึงมองหาเครื่องมือเพื่อช่วยประเมินความน่าเชื่อถือของเนื้อหาที่สร้างโดย AI และสัญญาณทางข้อความที่ปรากฏในกระบวนการภายในองค์กรมากขึ้นเรื่อยๆ ในบริบทนี้ การปรึกษาคู่มือเกี่ยวกับเครื่องมือตรวจจับ AI ของอิตาลีอาจเป็นประโยชน์ โดยเฉพาะอย่างยิ่งหากทีมของคุณทำงานกับเอกสาร เนื้อหา และการตรวจสอบทางภาษา
ในทางปฏิบัติ ความแตกต่างนั้นง่ายมาก แทนที่จะต้องจัดการกับกระบวนการทางเทคนิคที่แยกส่วนกัน คุณเปลี่ยนจุดสนใจไปที่ผลลัพธ์ทางธุรกิจ และนี่คือจุดที่ AI กลายเป็นสิ่งที่มีศักยภาพอย่างแท้จริง ไม่ใช่แค่เรื่องที่น่าสนใจเท่านั้น
ตัวจำแนกเบย์เซียนแบบไร้เดียงสาสอนบทเรียนสำคัญให้เรา ในด้านการวิเคราะห์ ความเรียบง่าย เมื่อถูกนำมาใช้อย่างมีประสิทธิภาพ สามารถให้ผลลัพธ์ที่ดีกว่าความซับซ้อนเมื่อถูกจัดการอย่างไม่ดี
ด้วยพื้นฐานทางความน่าจะเป็นที่เข้าใจง่าย ความสามารถในการปรับขนาดที่ดี และกรณีการใช้งานที่เป็นประโยชน์ในทางปฏิบัติ วิธีการนี้ยังคงเป็นเครื่องมือที่เชื่อถือได้สำหรับบริษัทที่ต้องการจัดประเภทข้อมูล ระบุสัญญาณที่ซ่อนอยู่ และดำเนินการด้วยความมั่นใจมากขึ้น คุณไม่จำเป็นต้องเป็นผู้เชี่ยวชาญด้านการเรียนรู้ของเครื่องเพื่อเข้าใจคุณค่าของมัน สิ่งที่จำเป็นคือการเชื่อมโยงคณิตศาสตร์กับการตัดสินใจในการดำเนินงาน
เมื่อการเชื่อมต่อนี้ชัดเจนแล้ว ปัญญาประดิษฐ์จะไม่ใช่ปัญหาทางเทคนิคอีกต่อไป แต่จะกลายเป็นข้อได้เปรียบทางองค์กร นั่นคือจุดที่การคาดการณ์เริ่มสร้างความแตกต่างอย่างแท้จริง
หากคุณต้องการเปลี่ยนข้อมูลที่กระจัดกระจายให้กลายเป็นข้อมูลเชิงลึกที่ชัดเจน ลอง ELECTEแพลตฟอร์มนี้ช่วยให้ธุรกิจขนาดกลางและขนาดย่อมเชื่อมต่อแหล่งข้อมูล, ทำให้การวิเคราะห์เป็นระบบอัตโนมัติ, และสร้างรายงานและการคาดการณ์ที่ช่วยให้การตัดสินใจรวดเร็วและมีข้อมูลมากขึ้น

.svg)
.svg)
.svg)





.webp)
