

PEC yoluyla bir XML dosyası alıyorsun. Tarayıcıda açtığında, bir sürü etiketle karşılaşıyorsun ve sorunun “dosyayı okumak” olduğunu düşünüyorsun. Aslında bu sadece ilk engel. Şirket içindeki asıl sorun başka: bu verilerin doğru, tutarlı ve raporlarına eklenmeye hazır olup olmadığını anlamak.
Birçok İtalyan KOBİ için bu konu artık dar anlamıyla teknik bir mesele değildir. Elektronik faturalandırma zorunlu hale geldiğinden beri, XML idare, yönetim kontrolü ve analiz alanlarındaki günlük işlerin bir parçası haline gelmiştir. Belgeyi görüntülemek yeterli değildir. Okunabilir bir dosya ile güvenilir bir dosya arasında ayrım yapabilmelisiniz. Verileri Excel’e, iş zekası (BI) sistemine veya bir analiz platformuna yüklemeden önce, ne zaman hızlı bir kontrolün yeterli olduğunu, ne zaman ise ayrıştırma, doğrulama ve normalleştirme işlemlerinin gerekli olduğunu anlamalısınız.
XML dosyalarını okumaya dair pratik bir rehber arıyorsanız, doğru yol şudur: basit yöntemlerle başlamak, bunların nerede aksadığını anlamak, ardından ham XML’i iş için yararlı verilere dönüştüren bir akış oluşturmak. İşte bu sayede hatalar azalır ve “dosyaya sahibim” ile “kullanılabilir bir içgörü elde ettim” arasındaki süre kısalır.
Bir XML dosyası, verileri hiyerarşik bir yapı içinde düzenler. Bir ana öğe vardır, iç içe geçmiş bölümler bulunur ve her blok, belirli bir anlamı olan bir bilgiyi tanımlar. İdari süreçleri yönetenler için bu ayrıntı, okunabilir bir veri ile gerçekten kullanılabilir bir veri arasındaki farkı belirler.
Mesele dosyayı “açmak” değil. Mesele, o dosyanın kontrol, muhasebe ve analiz süreçlerine hatasız bir şekilde dahil edilip edilemeyeceğini anlamaktır.
Bir elektronik faturayı ele alalım. Aynı dosya içinde tedarikçi verileri, müşteri verileri, vergi matrahı, KDV, ürün satırları, ödeme koşulları, sipariş referansları ve genellikle okunmasını zorlaştıran istisnalar bir arada bulunur. XML’de bu bilgiler, sıradan bir sayfada olduğu gibi arka arkaya sıralanmaz. Belirli konumlara yerleştirilirler ve bu konum, neyi temsil ettiklerini açıklar.
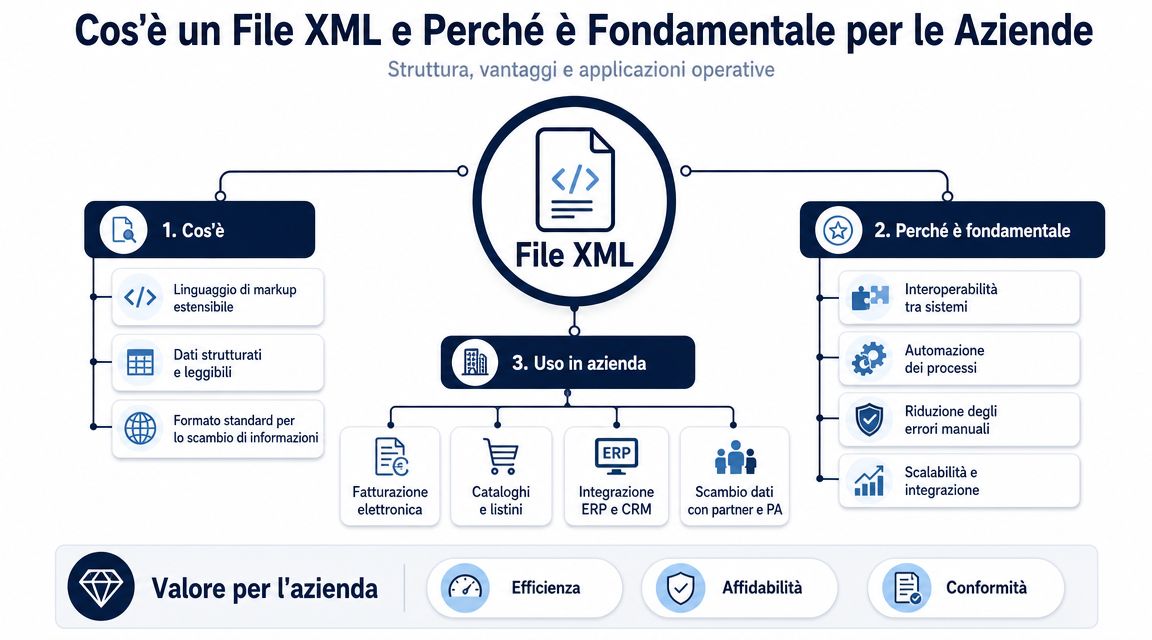
Bir yönetici için önemli olan ayrım, teorik anlamda etiketler ve öznitelikler arasındaki ayrım değildir. Bu ayrım, tek başına bir veri ile güvenilir bir veri arasındadır. Bağlamından kopuk olarak “1000,00” rakamını okumak pek bir işe yaramaz. Bu rakamı dosyanın doğru yerinde okumak ise bunun belgenin toplam tutarı, vergiye tabi tutar, vergi tutarı mı yoksa tek bir satırın değeri mi olduğunu anlamayı sağlar.
İşte ilk operasyonel avantaj burada ortaya çıkıyor. XML, verinin bağlamını korur.
Pratik kural: Bir XML dosyasını iyi okumak, sadece değeri değil, o değerin anlamını da doğrulamak demektir.
İtalya'da bu konu, elektronik faturalandırmanın yaygınlaşmasıyla somut bir hal almıştır. FatturaPA formatında, XML vergi belgeleri için standart haline gelmiştir. Dolayısıyla, bu belgelerin okunması artık sadece BT departmanının işi değildir. Bu süreç, idare, yönetim kontrolü, satın alma departmanlarını ve karar almak için bu verileri kullanması gereken herkesi ilgilendirir.
Uygulamada her zaman aynı sorunu görüyorum. Dosya mevcut, veriler de var, ancak bunları yararlı bilgiye dönüştürmek için gereken süre çok uzuyor. Bir kişi XML dosyasını açıyor, gözle kontrol ediyor, değerleri Excel’e kopyalıyor, tutarsız alanları düzeltiyor, farklı şekillerde yazılmış tedarikçilerin adlarını yeniden adlandırıyor ve dosyanın analiz için hazır bir biçimde sunmadığı harcama kategorilerini yeniden oluşturmaya çalışıyor. Maliyet sadece operasyonel değil. Bu, içgörü elde etmek için harcanan zamanın boşa gitmesidir.
FatturaPA ile bu risk daha da belirgin hale geliyor. Biçim açısından doğru olan iki dosya bile, birinde satır açıklamaları çok hatalıysa, sipariş referansları eksikse veya tedarikçi kayıtlarında farklı varyantlar varsa, aynı analiz sorunlarına yol açabilir. Bu noktada sorun, XML’i okumak değildir. Asıl sorun, geçerli mali verilerin güvenilirliği düşük yönetim verilerine dönüşmesini önlemektir.
Sıkça yapılan bir hata, XML’i görüntülenecek bir ek olarak ele almaktır. Şirket içinde, XML’i raporlara, gösterge panellerine ve harcama modellerine beslenmeden önce kontrol edilmesi gereken yapılandırılmış bir veri kaynağı olarak değerlendirmek daha etkili bir yaklaşımdır. Bu aşama yanlış yönetilirse, finans ekibi görünüşte doğru olan ancak tutarsız sınıflandırmalara dayanan rakamlar üzerinde tartışmak zorunda kalır.
Başlangıçta sorulması gereken doğru sorular şunlardır:
Bunlar oldukça somut kontroller. Raporlarda aynı tedarikçilerin iki kez yer almasını, KDV’nin yanlış yorumlanmasını, maliyet merkezlerinin eksik doldurulmasını ve ay sonunda uzlaşmaların yavaş ilerlemesini önlemeye yararlar.
İşte burada teknik okuma ile iş değeri arasındaki fark ortaya çıkıyor. Bir ayrıştırıcı dosyayı okur. İyi tasarlanmış bir süreç, temiz, karşılaştırılabilir ve analize hazır veriler üretir. ELECTE gibi platformlar, tam da bu farkı ortadan kaldırmak için ortaya çıkmıştır; alınan XML ile daha iyi kararlar almak için gerekli içgörüler arasında duran manuel iş yükünü azaltır.
Tek bir dosya üzerinde hızlı kontroller yapmak için ayrıştırıcılara veya kütüphanelere gerek yoktur. Önemli olan, birkaç alanı görsel olarak kontrol edip etmediğinizi ya da muhasebe, raporlama veya yönetim kontrolüne aktarılacak verilerle uğraşıp uğraşmadığınızı anlamaktır. Bu fark önemlidir, özellikle de FatturePA söz konusu olduğunda. Bugün aceleyle yapılan bir kontrol, yarın tedarikçi veri setinde hatalı bir satır haline gelebilir.

Tarayıcılar, metin düzenleyiciler ve özel görüntüleyiciler belirli bir sorunu çözer: teknik bir akış kurmadan içeriği hızlıca okumak. Tek başına bir dosya için bu genellikle yeterlidir. Yapısını görmek için bir XML dosyasını Chrome, Edge veya Firefox'ta açabilir ya da etiketleri doğrudan incelemek istiyorsanız Not Defteri, WordPad veya TextEdit'i kullanabilirsiniz. Elektronik faturalar söz konusu olduğunda, özel bir görüntüleyici sayesinde başlıklar, belge satırları, vergi matrahı ve KDV daha okunaklı hale gelir.
İşin özü şudur:
| Araç | Şu durumlarda yararlıdır: | En önemli sınırlama |
|---|---|---|
| Tarayıcı | Yapının hızlı gözle kontrolü | Alanlar ve bölümler arasındaki tutarlılığı kontrol etmez |
| Metin düzenleyici | Etiketlerin doğrudan denetimi | Uzun veya iç içe geçmiş dosyalarda kullanımı zorlaşıyor |
| Excel | Tablo biçiminde ön kontrol | Hiyerarşileri ve tekrarları kötü yönetir |
| Özel görüntüleyici | Faturaların ve vergi belgelerinin daha net okunması | Verileri analiz veya otomasyon için hazırlamaz |
Belge tarihini, KDV numarasını, fatura toplamını veya eklerin olup olmadığını kontrol etmeniz gerekiyorsa, bu araçlar bu amaç için uygundur.
Oysa amaç tedarikçileri karşılaştırmak, harcamaları sınıflandırmak ya da bir gösterge tablosunu beslemekse, yalnızca dosyayı görüntülemek işi yavaşlatır ve manuel hatalara çok fazla yer bırakır. Bu, bir dosyayı görmekle zamanında güvenilir bir veriye ulaşmak arasındaki klasik uçurumdur.
Bir XML dosyasını açmak, raporlarda kullanacağınız verileri doğrulamakla aynı şey değildir.
Bir başka pratik husus da hacimle ilgilidir. On satırlık bir belge elle de kontrol edilebilir. Ancak yüzlerce FatturePA faturası için bu mümkün değildir. Bu durumda, tekrarlanabilir bir iş akışı veya içeriği yapılandırılmış bir şekilde okuyan araçlar üzerinde düşünmek daha mantıklıdır; örneğin, vergi belgelerini entegre bir şekilde almak ve yönetmek için API kullanımı gibi.
İtalya’da sıkça karşılaşılan sorun, bir .xml, ancak bir şey geldiğinde ne yapacağını anlamak .xml.p7m PEC yoluyla. Basit XML dosyaları ile dijital olarak imzalanmış dosyalar arasında ayrım yapmak gerekir. İkinci durumda, imzayı okuyabilen, içeriği ayıklayabilen ve doğru XML'i görüntüleyebilen araçlara ihtiyaç vardır; bu konuda şu şekilde açıklanmaktadır: PEC'de XML ve XML P7M'ye ilişkin bu kılavuz.
Burada hatalar zamana mal olur:
Bir idari personel için en yararlı adımlar basittir:
Bu yöntemler, birinci aşama denetimlerde görevlerini başarıyla yerine getiriyor. Ancak şirket için asıl sorun olan, genellikle düzensiz veya tutarsız olan vergi XML’lerini, alınan belge ile yararlı bilgi arasında geçen süreyi uzatmadan temiz ve karşılaştırılabilir verilere dönüştürme sorununu çözmüyorlar.
Dosyalar birikmeye başladığında, manuel çalışma artık sürdürülebilir olmaktan çıkar. Bu noktada, XML dosyalarını kod yazarak okumak pek de akıllıca bir seçim değildir. Bu, tekrarlayan işlerden, kopyalama hatalarından ve tutarsız veri kümelerinden kaçınmanın ilk adımıdır.

XML okumaya yönelik sağlam bir yaklaşım her zaman aynı mantığı izler: ayrıştırma, normalleştirme, hedefli veri çıkarma. Java ve Android eğitimlerinde doğru akış şu aşamalardan geçer: parse(), milin normalleştirilmesinden itibaren doc.getDocumentElement().normalize() ve ardından şu yöntemlerle tarlaların ıslahı getElementsByTagName, metin düzenleyicide görüntülemeye kıyasla daha istikrarlı bir yöntemdir; bunun örneği şöyledir: XML verilerinin okunmasına ilişkin bu teknik kılavuz.
Bu adım, seçtiğiniz dilden daha önemlidir. Normalleştirme adımını atlarsanız, düğümleri çok basit bir şekilde ararsanız ya da bir etiketin her zaman yalnızca bir kez göründüğünü varsayarsanız, komut dosyanız bazı dosyalarda çalışacak, ancak tam da önemli olan dosyalarda hata verecektir.
Daha sonra harici sistemlerle entegre edilmesi gereken projeler için, tekrarlanabilir ve belgelenmiş bir veri alma akışı oluşturmak faydalı olabilir. Uygulama entegrasyonları üzerinde çalışıyorsanız, özellikle önceden temizlenmiş bir veri kümesini sonraki süreçlere nasıl bağlayacağınızı anlamak için, doğrulanmış Postman profili içeren ELECTE API belgeleri yararlı bir kaynak olabilir.
Aşağıda basit örnekler bulabilirsiniz. Amaç her durumu ele almak değil, temel mantığı göstermektir: dosyayı açmak, bir düğüm bulmak, bir değeri yazdırmak.
import xml.etree.ElementTree as ETtree = ET.parse("fattura.xml")root = tree.getroot()numero = root.find(".//Numero")if numero is not None:print(numero.text)Python, prototipler, dönüşümler ve hafif iş akışları için genellikle en hızlı seçenektir. Çok sayıda XML dosyasını okumak, birkaç alanı ayıklamak ve bunları CSV veya JSON formatında kaydetmek gerektiğinde mükemmel bir seçimdir.
const xmlString = `<fattura><Numero>123</Numero></fattura>`;const parser = new DOMParser();const xmlDoc = parser.parseFromString(xmlString, "application/xml");const numero = xmlDoc.getElementsByTagName("Numero")[0];console.log(numero.textContent);Bu yaklaşım, sayfada yapılan hızlı testler veya küçük iç araçlar için kullanışlıdır. Hafif arayüzler için uygundur, ancak yapılandırılmış arka ofis iş akışları için o kadar uygun değildir.
const fs = require("fs");const xml2js = require("xml2js");const xml = fs.readFileSync("fattura.xml", "utf8");xml2js.parseString(xml, (err, result) => {if (err) throw err;console.log(result.fattura.Numero[0]);});Sunucu tarafında çalışıyorsanız ve otomasyonlar oluşturmak istiyorsanız, Node.js pratik bir seçenek olmaya devam ediyor. Bunun avantajı, XML okuma işlemini dosya sistemi, işleme kuyrukları ve dahili hizmetlerle kolayca entegre edebilmektir.
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();DocumentBuilder builder = factory.newDocumentBuilder();Document doc = builder.parse("fattura.xml");doc.getDocumentElement().normalize();NodeList lista = doc.getElementsByTagName("Numero");if (lista.getLength() > 0) {System.out.println(lista.item(0).getTextContent());}Java, genellikle kurumsal ortamlarda, yönetim sistemlerinde ve orta katman yazılımlarında kullanılır. Burada asıl önemli olan, veriyi sadece okumak değil, bunu öngörülebilir ve bakımının kolay bir şekilde yapmaktır.
library(XML)doc <- xmlParse("fattura.xml")numero <- xpathSApply(doc, "//Numero", xmlValue)print(numero)R, ayrıştırma işleminin analitik bir çalışmanın parçası olduğu durumlarda mantıklıdır. Bir sonraki adımınız istatistiksel bir analiz veya veri hazırlığıysa, her şeyi aynı ortamda tutabilirsiniz.
Ekibiniz her hafta aynı dosyaları açıyor ve aynı kontrolleri tekrarlıyorsa, zaten otomasyon alanındasınız demektir.
Asıl kazanç, “kod kullanarak XML okumak” değildir. İnsanları mekanik bir işten kurtarmak ve tutarlı veri kümeleri üreten bir akış oluşturmaktır.
Ciddi sorunlar, dosya tek bir dosya olmaktan çıktığında başlar. Tek bir FatturaPA dosyası neredeyse her zaman yönetilebilir. Zorluk, aylarca biriken belgeleri, farklı tedarikçileri, tutarsız şekilde doldurulmuş alanları ve ekli dosyaları bir araya getirmeniz gerektiğinde ortaya çıkar.
İtalyan KOBİ’lerinde en yaygın durum, tek başına bir “mega dosya” değil, bir parti halindedir. Yıllık olarak dışa aktarılan alacak faturaları, başlıklar, ayrıntı satırları, ödeme bilgileri ve base64 formatındaki ekler dahil olmak üzere 4.200 faturadan oluşan ve 380.000'den fazla düğüm içeren bir yapı oluşturabilir. Bu senaryolarda sorun, belgeyi açmak değildir. Sorun, heterojen XML'leri tutarlı bir veri kümesine dönüştürmektir.
Burada, iş açısından etkileri olan bir teknik seçim devreye giriyor. .NET ortamında Microsoft, XmlDocument’ın belgeyi belleğe yüklediğini ve okuma ile düzenleme işlemleri için yararlı olduğunu belirtirken, büyük boyutlu dosyalar veya salt okuma işlemleri söz konusu olduğunda, XmlDocument ve XPathDocument ile XML okuma konusunda Microsoft belgelerinde de belirtildiği üzere, aşırı RAM tüketimini önlemek için akışlı ayrıştırıcı veya XPathDocument gibi daha verimli yaklaşımlara yönelmenin daha uygun olduğunu ifade ediyor.
Pratikte:
Buradaki dengeleme basit. Bellek içi model, daha hızlı geliştirme yapmanızı sağlar. Akış modeli ise, dosya sayısı arttığında veya dosya boyutları büyüdüğünde üretim ortamında daha iyi performans gösterir.
Birçok ekip, XSD doğrulamasıyla yetinir. Bu yararlıdır, ancak yeterli değildir. Bir dosya şemaya uygun olsa bile, sonraki aşamalarda hatalı veriler üretebilir.
Operasyonel çalışmalardan tipik örnekler:
| Kontrol türü | Neyi kontrol eder? | Neden gereklidir? |
|---|---|---|
| Yapısal | Etiket, biçim, hiyerarşi | Ayrıştırma hatalarını önleyin |
| Anlamsal | Verilerin mantıksal tutarlılığı | Yanlış analizlerden kaçının |
| Hizmet veriyor | Raporlama için gerekli alanların varlığı | Kullanılamaz veri kümelerini önleyin |
En aldatıcı durum şudur: Belgenin Toplam Tutarı, biçimsel olarak geçerli olmasına rağmen satırların toplamıyla tutarsızdır; bu durum, örneğin tedarikçinin yönetim sistemindeki yuvarlama kuralları nedeniyle ortaya çıkabilir. Ya da KDV kodları biçimsel olarak kabul edilebilir olsa da işlemin niteliğiyle tutarsızdır.
Biçim açısından hatasız bir dosya bile raporlamanızı bozabilir.
FatturaPA'da bilinen bir başka tuzak daha var. DatiBeniServizi etiketi serbest açıklamalar içerir. Aynı maliyet, düz, kısaltılmış veya anlaşılması zor metinlerle birçok farklı şekilde görünebilir. Bir normalleştirme adımı eklemezseniz, harcama kategorisine göre yapılacak herhangi bir analiz güvenilmez hale gelir.
Bu nedenle, ciddi veri akışlarında dosya okuma işlemi yalnızca birinci aşamadır. İkinci aşama ise her zaman tutarlılık ve temizlikle ilgili bir dizi kuraldır. Veri kalitesi, ayrıştırıcıda değil, işte bu aşamada korunur.
Düzgün bir şekilde okunan bir XML dosyası, henüz kullanışlı bir veri kümesi değildir. Bu, yapılandırılmış bir belgedir. Analizler, karşılaştırmalar, gruplandırmalar ve gösterge panelleri oluşturmak için, neredeyse her zaman bu dosyayı işlenmesi daha kolay bir biçime dönüştürmeniz gerekir.
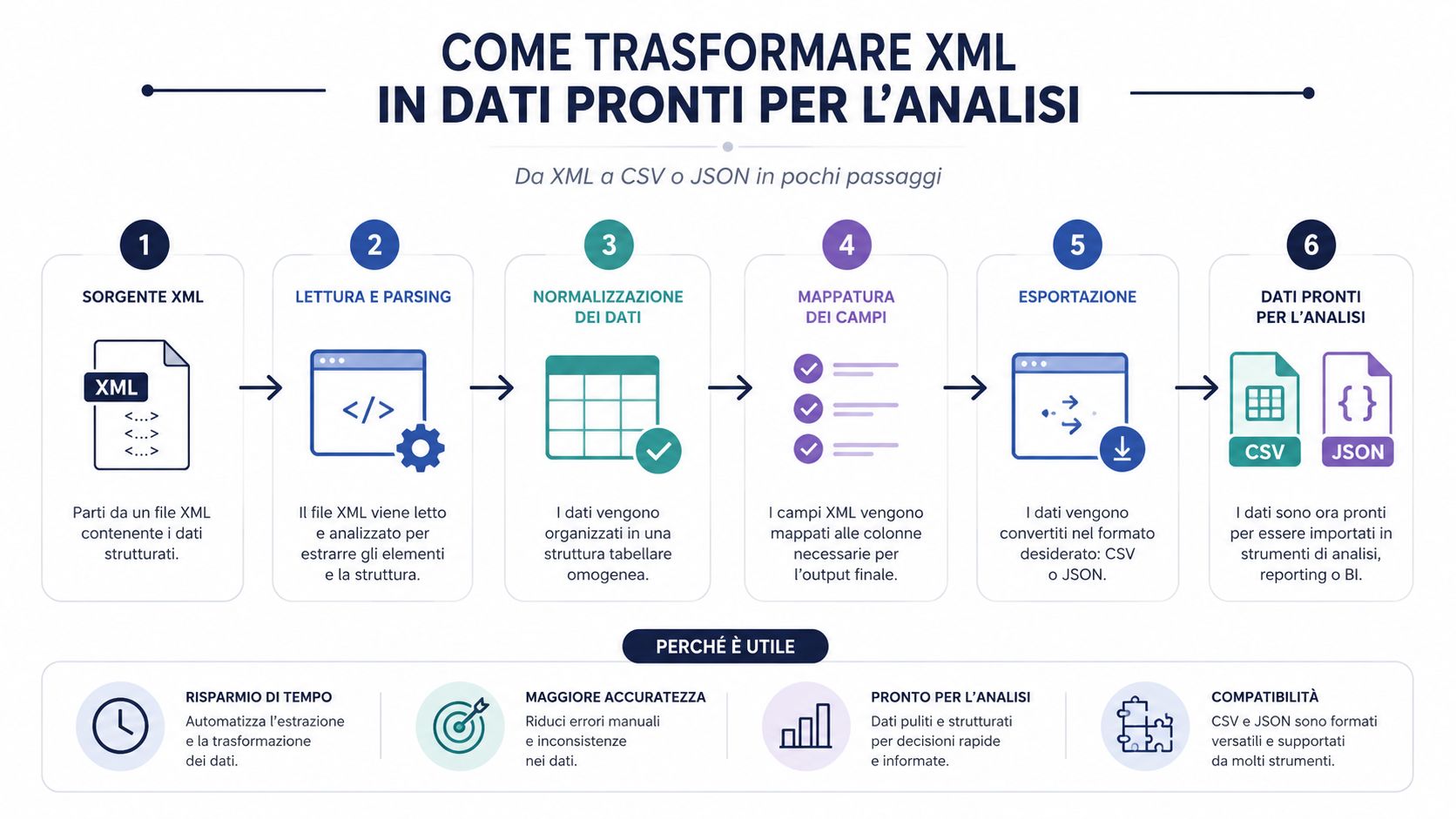
Bu, birçok süreçte göz ardı edilen bir noktadır. Darboğaz nadiren salt ayrıştırma işlemidir. İyi bir kütüphane, bir XML dosyasını hızlı bir şekilde okur. Zaman, yapının yorumlanması, gerekli alanların çıkarılması, temizleme, normalleştirme ve bir analiz aracına yüklenmesi aşamalarında harcanır.
Bu nedenle CSV veya JSON formatına dönüştürme işlemi sadece bir kolaylık değildir. Bu, iş akışının merkezinde yer alan bir adımdır. Bu aşamayı atlayıp doğrudan ham dosya üzerinde çalışırsanız, neredeyse her zaman manuel kontroller, doğaçlama sütunlar ve tekrarlanması zor mantıklarla karşı karşıya kalırsınız.
XML ve elektronik tablolar arasında sık sık çalışanlar için yararlı bir kaynak, XML’den Excel’e daha düzenli bir şekilde geçiş yapmayı anlatan bu kılavuzdur.
Doğru format, verileri daha sonra nasıl kullanacağınıza bağlıdır.
CSV, belge başına bir satır ya da fatura detayı başına bir satır istediğinizde ve ardından Excel, Power Query veya BI kullanmak istediğinizde iyi sonuç verir.
Python örneği:
import xml.etree.ElementTree as ETimport csvtree = ET.parse("fattura.xml")root = tree.getroot()with open("fatture.csv", "w", newline="", encoding="utf-8") as f:writer = csv.writer(f)writer.writerow(["numero", "data"])numero = root.findtext(".//Numero")data = root.findtext(".//Data")writer.writerow([numero, data])Bunun avantajı basitliğidir. Sınırı ise hiyerarşiyi nasıl düzleştireceğinize iyi karar vermeniz gerektiğidir. Bir faturada birden fazla ayrıntı satırı varsa, ayrıntı düzeyi ve bağlantı anahtarı konusunda net bir seçim yapmanız gerekir.
Hiyerarşik yapının bir kısmını korumak istediğinizde JSON daha uygundur.
JavaScript örneği:
const record = {numero: "123",data: "2024-01-15",righe: [{ descrizione: "Servizio", importo: "100.00" }]};console.log(JSON.stringify(record, null, 2));Bir sonraki adımın bir API, bir veri gölü veya iç içe geçmiş nesnelerle iyi çalışan bir uygulama olduğu durumlarda bunu kullanın.
İşte size yardımcı olacak pratik bir kural:
XML dosyası bir kapsayıcıdır. CSV ve JSON ise içeriğin gerçekten işlenebilir hale getirilmesini sağlayan biçimlerdir.
Eğer içgörü elde etme süresini kısaltmak istiyorsanız, işte bu noktada yöntemlere yatırım yapmanızda fayda var. Daha kullanışlı bir görüntüleyici bulmaya değil, istikrarlı ve tekrarlanabilir bir dönüşüm tanımlamaya.
Dosya okunduktan, doğrulandıktan ve işlendikten sonra, işin niteliği değişir. Artık etiketlerle uğraşmıyorsunuz. Nihayet maliyetler, sapmalar, tedarikçiler, harcama kategorileri ve operasyonel eğilimler üzerinde kafa yoruyorsunuz.
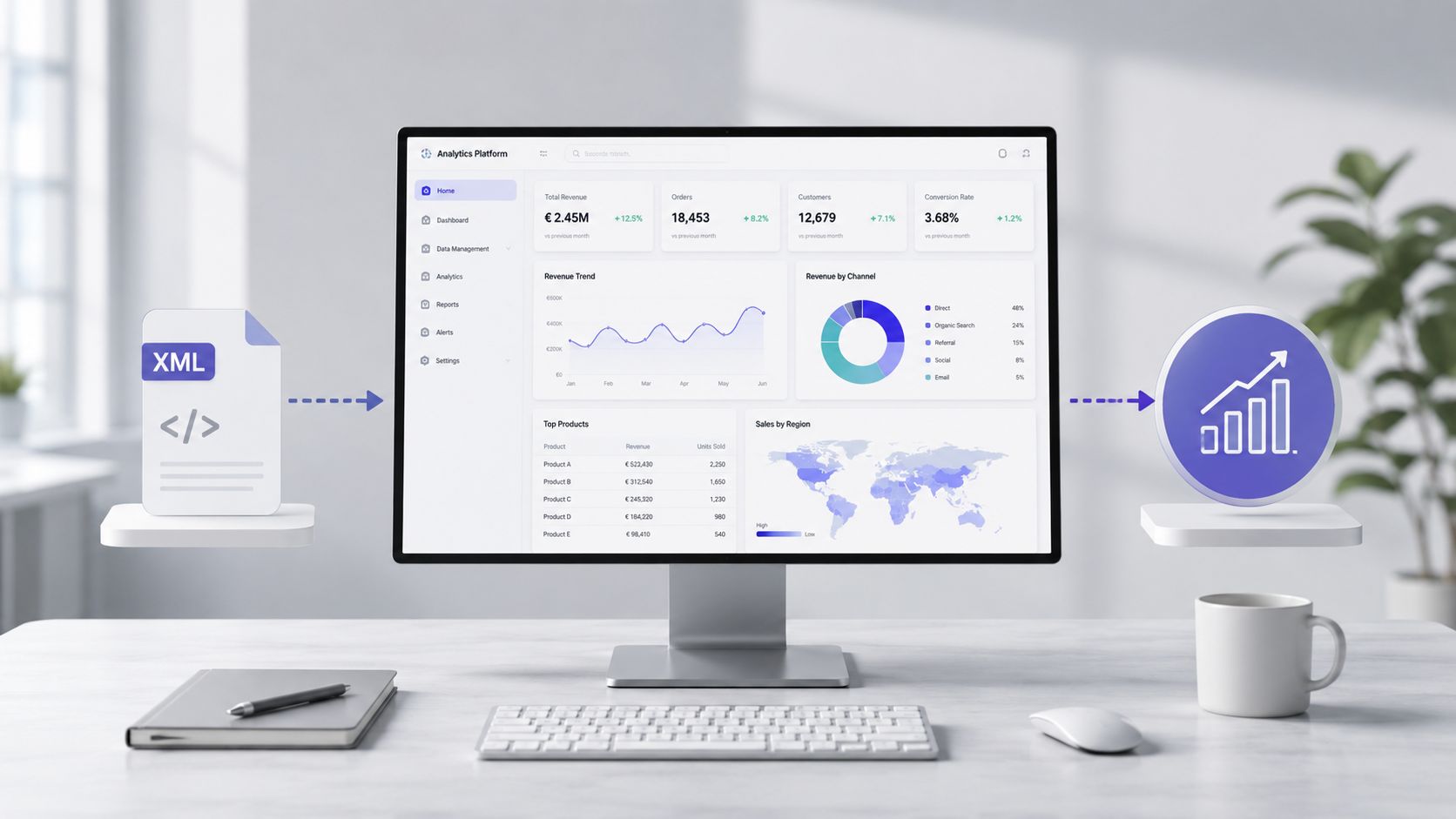
Gerçek hayatta, asıl değer ayrıştırma süresinde yatmaz. Değer, ham dosyadan karar verebileceğiniz bir bilgiye ulaşana kadar geçen sürede yatmaktadır. Manuel bir iş akışında, bir kişinin belgeyi açması, yapısını anlaması, alanları ayıklaması, değerleri temizlemesi, metinleri normalleştirmesi ve ardından raporları oluşturması gerekir. Bu, kırılgan bir süreçtir.
FatturaPA’da klasik bir örnek, DatiBeniServizi’deki serbest metindir. Aynı hizmet, farklı tedarikçiler tarafından birçok farklı şekilde tanımlanabilir. Bu verileri tutarlı bir eşleme olmadan içe aktarırsanız, maliyet kategorisine göre yapılan analiz gereksiz toplama sonuçları verir.
Bu nedenle, analiz platformundan önce bir veri hazırlama katmanı gereklidir:
Bu aşama doğru bir şekilde gerçekleştirildiğinde, herhangi bir analiz platformu daha iyi çalışır. Bu adımın karar verme ve görselleştirme yönlerini daha derinlemesine incelemek isterseniz, verilerle hikâyeler oluşturmaya dair kaynak oldukça faydalıdır; çünkü temiz bir veri kümesinin karar vericiler için nasıl yararlı bir hikâyeye dönüştüğünü gösterir.
Bu noktada XML dosyası artık teknik bir sorun olmaktan çıkar ve içgörü elde etmek için bir hammadde haline gelir. İyi hazırlanmış bir veri kümesi, harcama analizlerine, trend takibine, sapmaların tespit edilmesine ve istisnaların değerlendirilmesine katkı sağlayabilir.
Bu son aşamaya uygun bir platform seçmek için, modern bir iş analitiği yazılımının sunduklarını, tamamen manuel olan ve elektronik tablolar ile pivot tablolarına dayalı iş akışlarıyla karşılaştırmanız size yardımcı olabilir.
Burada doğru kriter “XML dosyasını açabiliyor mu?” değildir. Bu en temel şarttır. Asıl önemli soru şudur:
| Soru | Neden önemli? |
|---|---|
| Veriler zaten temiz bir şekilde giriliyor | Yanlış verilere dayalı kesin içgörülerden kaçının |
| Kategoriler birbiriyle tutarlıdır | Tedarikçileri ve dönemleri gerçekten karşılaştırıyor musunuz? |
| Anormallikler hemen ortaya çıkıyor | Manuel kontrollerde harcanan zamanı azaltın |
| Bu rapor, işletme ve finans alanındaki kişiler tarafından okunabilir | Karar verme sürecini hızlandırır |
Gelişmemiş bir süreç ile olgun bir süreç arasındaki fark, XML dosyalarını okuma yeteneğinde değildir. Bu fark, bu dosyaları güvenilir bir veritabanına dönüştürebilme yeteneğinde yatmaktadır; böylece ekip her seferinde aynı işi tekrarlamak zorunda kalmaz.
XML dosyalarını iş açısından faydalı bir şekilde okumak istiyorsanız, bu kontrol listesini göz önünde bulundurun. Bu liste, herhangi bir teknik tanımdan daha somuttur ve zaman kaybetmeden doğru yöntemi seçmenize yardımcı olur.
Her zaman aynı yaklaşımı kullanmayın. Tarayıcılar, düzenleyiciler ve görüntüleyiciler hızlı kontroller için uygundur. Ayrıştırıcılar ve komut dosyaları ise dosyanın tekrarlanan işlemlere veri sağlaması gerektiğinde kullanılır. Görüntüleme ile veri işlemeyi birbirine karıştırırsanız, raporları zayıf temeller üzerine inşa etme riskiyle karşı karşıya kalırsınız.
Dosyalar .xml.p7m bunlar, imzanın yönetimine ilişkin özel bir adım gerektirir. İçerik PEC’den geliyorsa, bu kontrol ikincil bir işlem değildir. Belgenin doğru şekilde okunmasının bir parçasıdır.
Bir şablona uyulması, veri setinin sağlam olacağını garanti etmez. Toplamların tutarsızlığı veya belirsiz vergi sınıflandırmaları gibi mantıksal tutarsızlıklar, analizi en sık bozan unsurlardır. Anlamsal kontrol, “kabul edilebilir” bir dosyayı güvenilir bir veriden ayıran unsurdur.
CSV ve JSON sadece kozmetik bir değişiklik değildir. Bunlar, XML’in analitik araçlar, elektronik tablolar, iş akışları ve raporlar tarafından işlenebilir hale geldiği noktadır. Bu dönüşümü ne kadar erken tanımlarsanız, manuel iş yükünü ve doğaçlamayı o kadar çabuk azaltırsınız.
Amacınız XML dosyalarını okumak değil. Hedef, sistemi hatalı verilerle kirletmeden yararlı içgörüler elde etmektir. Akış tutarlı bir veri kümesi üretmiyorsa, sorun nihai gösterge tablosunda değildir. Sorun çok daha öncesinde yatmaktadır.
Pratikte, her yeni projeye başlamadan önce bu mini kontrol listesini kullanabilirsin:
Hazırlanmış verileri net ve eyleme geçirilebilir içgörülere dönüştürmek istiyorsanız, ELECTE, teknik bilgiye sahip olmayan ekipler için de erişilebilir bir yaklaşımla KOBİ’lerin temiz veri setinden akıllı raporlamaya geçmesine yardımcı olur. Bu, operasyonel veriler ile karar alma süreci arasındaki mesafeyi kısaltmanın en hızlı yoludur.

.svg)
.svg)
.svg)
.webp)





