

Verileriniz zaten bir hikaye anlatıyor. Sorun şu ki, genellikle çok sessiz kalıyorlar.
Her gün bir KOBİ, müşteri geri bildirimleri, siparişler, destek talepleri, finansal hareketler, ticari e-postalar ve CRM notları biriktirir. Tüm bu veriler yararlı ipuçları içerir. Bazıları, ayrılmak üzere olan bir müşteriye işaret eder. Bazıları ise operasyonel bir riski önceden haber verir. Diğerleri ise hangi ürünlerin satışlarının artacağına veya azalacağına dair ipucu verir. Ancak net bir yöntem olmadan bu ipuçları sadece gürültüden ibarettir.
Bu kaosun içine düzen getirmekte yardımcı olan algoritmalar arasında, naif Bayes sınıflandırıcıları özel bir yere sahiptir. Mantığı anlaşılması kolaydır, eğitimi hızlıdır ve çoğu zaman “naif” isminin düşündürdüğünden daha etkilidirler. Her senaryo için doğru seçim olmayabilirler, ancak birçok gerçek iş probleminde hız, yorumlanabilirlik ve faydalı sonuçlar arasında nadir görülen bir denge sunarlar.
İş dünyasında çalışıyorsanız, bunları anlamak için bir araştırmacı olmanıza gerek yok. Ne yaptıklarını, gerçekliği büyük ölçüde basitleştirmelerine rağmen neden iyi işlediklerini ve hangi durumlarda daha iyi kararlar almanıza yardımcı olabileceklerini bilmeniz yeterlidir. İşte tam da bu noktada durup düşünmeye değer.
Birçok şirket, sorunun öncelikle güvenilir ve kullanımı kolay bir modele ihtiyaç duyduğu durumlarda bile, karmaşık modeller arar. Finans, perakende veya müşteri hizmetleri alanlarında da aynı nedenden ötürü, genellikle teorik olarak en zarif olan değil, en net olan süreç galip gelir.
Naif Bayes sınıflandırıcıları oldukça somut bir fikirden yola çıkar. Yeni bir vaka hakkında bazı ipuçları varsa, bu vakanın hangi kategoriye ait olduğunu yüksek olasılıkla tahmin edebilirsiniz. Bir e-posta belirli kelimeler içeriyorsa, spam olabilir. Bir işlem belirli kalıplar gösteriyorsa, incelenmesi gerekebilir. Bir yorumda belirli terimler kullanılıyorsa, bu memnuniyet veya memnuniyetsizliği işaret ediyor olabilir.
“Bayesci” kelimesi, karmaşık formülleri akla getirir. Oysa bu yöntemin özü sezgiseldir. Zaten bildiklerinizi alırsınız, yeni kanıtları ekler ve yargınızı güncellersiniz. Bu, belirsizlik ortamında mantıklı bir şekilde düşünmenin düzenli bir yoludur; tam da yöneticilerin her gün yaptığı şey, sadece bir algoritma sayesinde sistematik hale getirilmiş hali.
Şaşırtıcı olan şey, bu yaklaşımın, bol miktarda verinin ve hızlı kararların alındığı modern ortamlarda bile hâlâ iyi sonuç vermesidir. Bunun nedeni, dünyayı kusursuz bir şekilde tanımlaması değil, çok düşük bir hesaplama maliyetiyle yararlı sinyali gürültüden ayırmasıdır.
İş dünyasındaki sorunlarda asıl soru “en gelişmiş model hangisi?” değildir. Asıl soru “hangi model, gerçek iş hayatının gerektirdiği zaman dilimlerinde güvenilir kararlar almamı sağlar?”dır.
Bu nedenle, naif Bayes sınıflandırıcıları hâlâ önemini korumaktadır. Bu sınıflandırıcılar, sınıflandırma, filtreleme, segmentasyon ve önceliklendirme işlemlerinde size yardımcı olur. Ayrıca, her projeyi teknik bir şantiyeye dönüştürmeden karar verme sürecine olasılık analizini dahil etmenizi sağlar.
Temel ilke Bayes teoremi'dir. Basitçe şöyle ifade edilebilir: başlangıçta bir olasılık varsayarsınız, ardından yeni bilgiler geldikçe bu olasılığı güncellersiniz.
Veri dilinde bu formül şu şekilde ifade edilir: P(y|x) ∝ P(y) ⋅ ∏ P(x_i|y). Bu, bir sinyal kümesi verildiğinde bir sınıfın olasılığının iki unsura bağlı olduğu anlamına gelir. Birincisi, sınıfın başlangıç olasılığıdır. İkincisi ise her bir sinyalin o sınıfla ne kadar uyumlu olduğudur.
Bunu bir iş örneğiyle açıklayalım. Bir e-postanın spam olup olmadığını anlaman gerekiyor. Gelen bir e-postanın spam olma ihtimali genel olarak var. Ardından “teklif”, “ücretsiz”, “buraya tıkla” gibi bazı kelimelere bakıyorsun. Bu kelimelerin her biri nihai kararını etkiliyor.
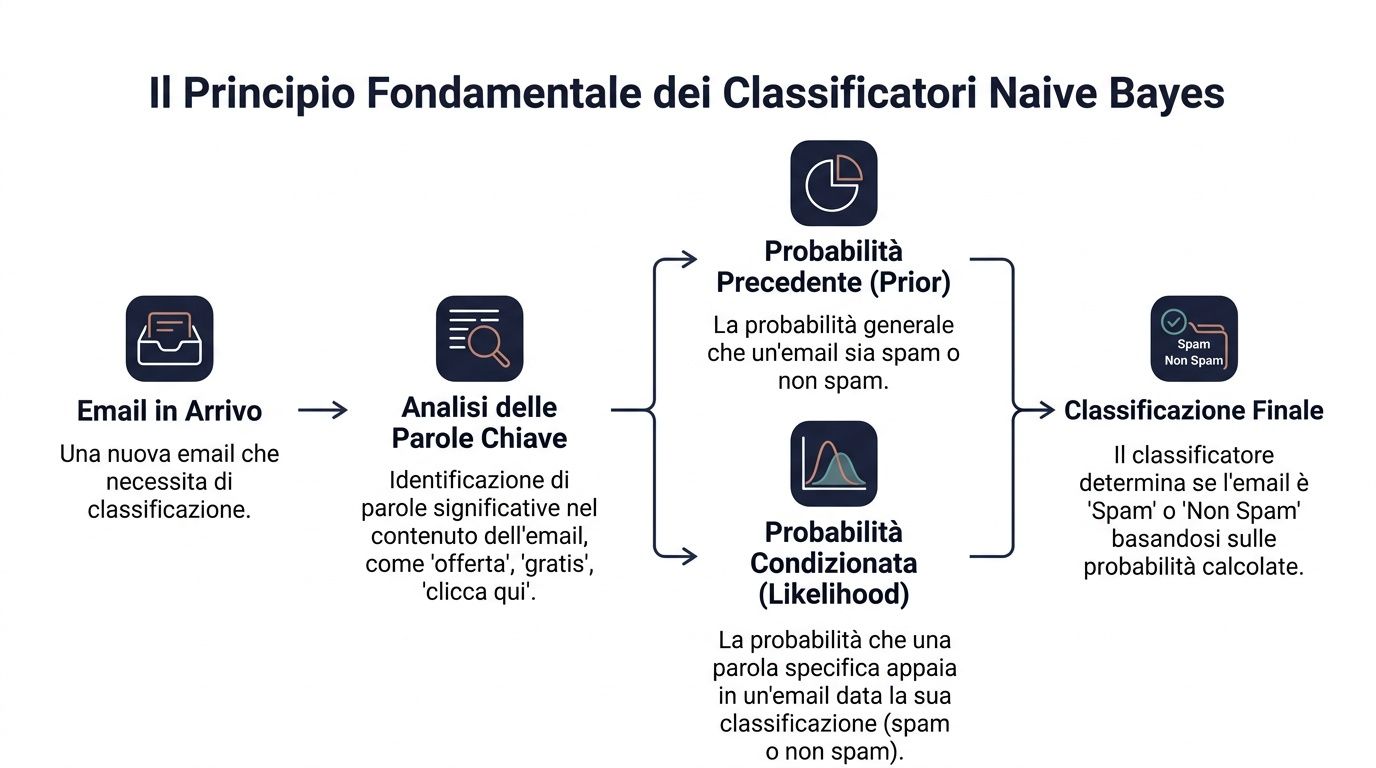
Bir yönetici her gün buna benzer şeyler yapar. Asla boşlukta karar vermez. Temel bir bağlamdan yola çıkar ve ipuçları ekler. Her zaman düzenli olarak alışveriş yapan bir müşterinin belirli bir başlangıç profili vardır. Eğer daha sonra e-postaları açmayı bırakırsa, sipariş tutarını düşürürse ve kritik bir destek talebi açarsa, sizin değerlendirmeniz değişir.
"Naive" terimi, belirli bir varsayımı ifade eder. Model, sınıfın bilindiği için özellikleri birbirinden bağımsızmış gibi ele alır.
Pratikte, bir e-postayı sınıflandırırken her kelimeyi ayrı bir ipucu olarak değerlendirin. Terimler arasındaki tüm karmaşık ilişkileri modellemeye çalışmayın. Bu, oldukça basitleştirilmiş bir yaklaşımdır. Gerçekte, birçok kelime bir arada geçer ve birçok kurumsal davranış birbiriyle bağlantılıdır.
Oysa tam da bu seçim, modeli oldukça hafif kılıyor. Karmaşık bir bağımlılık ağını öğrenmesi gerekmiyor. Daha basit olasılıkları tahmin etmesi ve bunları verimli bir şekilde birleştirmesi gerekiyor.
Pratik kural: Naive Bayes, dünyayı baştan sona yeniden inşa etmeye çalışmaz. Az sayıda varsayımla ve büyük bir hızla yararlı kararlar almaya çalışır.
Yanlış anlaşılmalar genellikle buradan kaynaklanır. Birçok kişi “naif varsayım” ifadesini okuyup “zayıf model” sonucuna varır. Durum böyle değildir. Bir model, karar verme sürecinde önemli olan unsurları yakaladığı sürece, oldukça basitleştirilebilir ve yine de geçerliliğini koruyabilir.
2004 yılında yapılan bir teorik analiz, bağımsızlık varsayımına rağmen Naive Bayes sınıflandırıcılarının etkinliği için sağlam gerekçeler ortaya koymuş ve bunların neden lojistik regresyondan daha hızlı bir şekilde asimptotik hataya ulaşabildiğini açıklamıştır. Aynı uygulama alanında, spam filtrelemede %99'un üzerinde doğruluk oranlarına ulaşmakta ve Naive Bayes sınıflandırıcılarına ayrılmış maddede belirtildiği gibi milyonlarca belgeye kadar ölçeklenebilmektedir.
Bu nokta, kurumsal bir kitle için önemlidir. Bir algoritmanın değeri sadece nihai puanda yatmaz. Aynı zamanda hızlı bir şekilde eğitilebilme, geniş veri kümelerine uyum sağlayabilme ve yorumlanabilirliğini koruyabilme yeteneğinde de yatmaktadır.
Metinler, kategoriler, etiketler veya işaretler dağınık olduğunda, naif Bayes sınıflandırıcıları şu nedenlerle iyi sonuç verir:
Ancak akılda tutulması gereken iki nokta var.
Bu nedenle Naive Bayes, evrensel bir sihirli değnek olarak değil, hızlı sınıflandırma problemlerinde oldukça etkili bir araç olarak görülmelidir. Bununla birlikte, birçok pratik bağlamda, başlangıç için en akıllıca yöntemlerden biridir.
Sıkça yapılan bir hata, Naive Bayes'ten sanki her durumda aynı tek bir modelmiş gibi bahsetmektir. Oysa farklı veri türleri için tasarlanmış çeşitli varyantları bulunmaktadır.
Doğru seçim, elinizdeki verilerin yapısına bağlıdır. Yanlış varyantı seçerseniz, model yine de bir tahmin üretebilir, ancak sorununuz için en uygun şekilde işlem yapmaz.
Gaussian Naive Bayes, özellikler sürekli olduğunda en uygun seçenektir. Örneğin, bir işlemin ortalama tutarı, müşteri yaşı, iki satın alma arasındaki ortalama süre, birim kâr marjı veya fiş tutarı gibi özellikleri düşünün.
Bu modelde, her sınıf içindeki değerlerin Gauss dağılımına uyduğu varsayılmaktadır. Bunu akademik bir kısıtlama olarak düşünmenize gerek yok. Pratik açıdan şunu hatırlamanız yeterlidir: model, her sınıf için bir ortalama değer ve bir dağılım tahmin eder.
Bu yaklaşım, aşağıdaki gibi durumları sınıflandırmak istediğinizde yararlıdır:
İtalyan e-ticaret verilerine benzer bir veri kümesi üzerinde yapılan bir scikit-learn karşılaştırma testinde, bir Naive Bayes modeli 1000 örnekle %95 doğruluk oranına ulaşmış ve eğitim süresi açısından lojistik regresyona göre %15 daha iyi bir performans sergilemi ştir. Jake VanderPlas'ın In Depth Naive Bayes Classification başlıklı bölümünde gösterildiği gibi, kapalı formda eğitim sayesinde, standart CPU'da karşılaştırma 0,01 saniye ile 0,1 saniye arasındadır.
Bir şirket için asıl mesele ondalık basamak değildir. Asıl mesele, bu varyantın uzun eğitim süreleri ve ağır bir altyapı gerektirmeden iyi sonuçlar verebilmesidir.
Metinler, biletler, yorumlar veya geri bildirimlerle çalışıyorsanız, Multinomial Naive Bayes genellikle en doğal tercihtir. Burada özellikler, sayımlar veya sıklıklardır. Pratikte model, kelimelerin veya terimlerin kaç kez geçtiğine bakar.
Bu, şu klasik senaryodur:
Bunun iyi sonuç vermesinin nedeni oldukça somuttur. İş dünyasındaki metinlerde kelime dağarcığı geniş olabilir, ancak her belge olası kelimelerin sadece küçük bir kısmını içerir. Veriler dağınıktır. Multinomial Naive Bayes, tam da bu tür bir yapıyı iyi bir şekilde işler.
GeeksforGeeks'in Naive Bayes sınıflandırıcıları hakkındaki kılavuzunda belirtildiği üzere, duygu etiketleri eklenmiş 100.000 İtalyanca tweet üzerinde yapılan bir çalışmada, Multinomial Naive Bayes, SVM'ye kıyasla 10 kat daha hızlı bir performans göstererek 0,88 F1 puanı elde etti.
Bunu kolayca hatırlamak için şöyle düşünün: Eğer veriniz, sayılmış kelimelerle dolu bir belgeye benziyorsa, çok terimli model neredeyse her zaman denemeniz gereken ilk seçenektir.
Şirketiniz büyük miktarda metin okumak zorundaysa, asıl soru sadece “model ne kadar doğru?” değildir. Aynı zamanda “ekibin iş akışını yavaşlatmadan kaç isteği sınıflandırabiliyor?” sorusudur.
Bernoulli Naive Bayes, ikili özelliklerle çalışır. Bir sinyalin kaç kez ortaya çıktığı önemli değildir. Önemli olan, sinyalin mevcut olup olmadığıdır.
Bu varyant, bir özniteliğin varlığının sıklığından daha önemli olduğu durumlarda yararlıdır. İş dünyasından bazı örnekler:
Bu mantık, karmaşık olguları izlemesi kolay evet/hayır göstergelerine dönüştürmek istediğinizde oldukça kullanışlıdır. Örneğin duygu analizinde, olumsuz bir kelimenin kaç kez tekrarlandığı değil, o kelimenin geçip geçmediği daha önemli olabilir.
Bernoulli dağılımı, multinom dağılımından “daha az gelişmiş” değildir. Veri, varlığı ya da yokluğu ifade ettiğinde, bu dağılım daha uygundur. Aradaki fark, sözde küçük görünse de sonuçlarda büyük bir fark yaratır.
| Varyant | İdeal Veri Türü | Kurumsal Kullanım Örneği |
|---|---|---|
| Gauss Naive Bayes | Sürekli veriler | İşlemleri tutar, sıklık ve ortalama değerleri kullanarak riske göre sınıflandırmak |
| Çok terimli Naive Bayes | Metinler, hesaplamalar, sıklıklar | Müşteri yorumlarını ve biletlerini duygu analizi veya kategoriye göre incelemek |
| Bernoulli Naive Bayes | İkili veriler, var/yok | Uyum, destek veya ürün kullanımı alanlarındaki evet/hayır sinyallerini değerlendirmek |
Doğru seçimi yapmak için şu basit kuralı uygulayın:
Birçok ekip, mutlak olarak “en iyi” modeli aramaya çalışırken tıkanır. Doğru seçim, neredeyse her zaman, veri türüyle en uyumlu modeldir.
İyi haber şu ki, Naive Bayes yöntemini uygulamaya koymak devasa bir proje gerektirmiyor. Okunabilir bir prototip bile, modelin nasıl çalıştığını ve hangi verilere ihtiyaç duyduğunu anlamaya yeter.

Bir sınıflandırıcı neredeyse her zaman dört aşamada oluşturulur.
Verilerinin Hazırlanması Önceden etiketlenmiş geçmiş örnekleri toplamalısınız. Yorumları sınıflandırıyorsanız, olumlu veya olumsuz olarak işaretlenmiş metinlere ihtiyacınız vardır. Operasyonel riski analiz ediyorsanız, sonucu bilinen geçmiş vakalara ihtiyacınız vardır.
modelinin eğitimi Model verileri inceler ve ilgili olasılıkları tahmin eder. Naive Bayesian sınıflandırıcılarında bu adım hızlıdır, çünkü eğitim süreci özellikle yoğun optimizasyonlar gerektirmez.
'da yeni vakalara ilişkin tahminler: Yeni kayıtları girin; model bir sınıf atayacaktır. Örneğin, "spam", "spam değil", "riskli müşteri", "istikrarlı müşteri".
Değerlendirmesi: Tahminleri ayrı bir test seti üzerinde gerçek sonuçlarla karşılaştırın. Burada sadece modelin çalışıp çalışmadığını incelemiyorsunuz. Modelin nasıl hata yaptığını da inceliyorsunuz.
Tahminsel yaklaşımların genel çerçevesini daha ayrıntılı olarak incelemek istiyorsanız, makine öğrenimi algoritmalarına ilişkin bu genel bakış, Naive Bayes yöntemini daha geniş bir yöntemler ailesi içinde konumlandırmanıza yardımcı olacaktır.
Süreci somutlaştırmak için, işte scikit-learn ile hazırlanmış basit bir örnek. Bunu bir geliştirici gibi okumaya gerek yok. Akışı anlamanız yeterli.
# Temel araçları içe aktarıyoruzfrom sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_splitfrom sklearn.naive_bayes import GaussianNBfrom sklearn.metrics import accuracy_score# Örnek veri setini yüklüyoruzX, y = load_iris(return_X_y=True)# Verileri eğitim ve test için ikiye ayıralımX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# Modeli oluşturalım model = GaussianNB()# Modeli geçmiş veriler üzerinde eğitelim model.fit(X_train, y_train)# Daha önce görülmemiş veriler üzerinde tahminler yapalım y_pred = model.predict(X_test)# Doğruluğu ölçelim print(accuracy_score(y_test, y_pred))Bu alıntı, göründüğünden çok daha fazlasını anlatıyor.
GaussianNB() sürekli veriler için seçeneği seçin.fit() bu, modelin öğrendiği andır.predict() öğrendiklerini uygulamaya koyar.accuracy_score() Toplamda kaç sınıflandırmanın doğru olduğunu kontrol edin.Metin verileri söz konusu olduğunda, süreç benzer şekilde ilerler, ancak modeli uygulamadan önce metni sayılara dönüştürmeniz gerekir. Pratikte, kelimeleri bir sınıflandırıcı tarafından kullanılabilir özelliklere dönüştürürsünüz.
Koda ilk göz attıktan sonra, mekanizmanın görsel bir açıklamasını incelemek faydalı olabilir.
İlk model, mükemmelliği kanıtlamak için değildir. Üç pratik soruyu yanıtlamak için kullanılır.
Naive Bayes'in gücü burada ortaya çıkıyor. Hızlı bir şekilde sağlam bir temel oluşturabilirsiniz. Bu noktadan sonra, projeyi karmaşıklaştırmanın mantıklı olup olmadığını ya da basit bir çözümün halihazırda değer yaratıp yaratmadığını anlayabilirsiniz.
Bir sınıflandırma modeli, sadece “işe yarıyor gibi görünüyor” diye değerlendirilemez. Bu model, nasıl hata yaptığına ve bu hataların iş üzerinde ne kadar ağırlık taşıdığına göre değerlendirilir.

Doğruluk, en sezgisel ölçüttür. Toplam tahminlerin kaç tanesinin doğru olduğunu gösterir. Yararlıdır, ancak tek başına yanıltıcı olabilir.
Yüz işlemden sadece birkaçı gerçekten şüpheliyse, neredeyse her şeyi normal olarak sınıflandıran bir model, doğruluk açısından iyi görünebilir ancak asıl gerekli olduğu yerlerde yetersiz kalabilir.
Bunu anlamak için bir balık ağını düşünün.
İş dünyasında bu ayrım çok önemlidir.
İyi bir model, genel olarak çok az hata yapan model değildir. Süreciniz için en az maliyetli şekilde hata yapan modeldir.
Bir algoritmanın geçmiş verilerden nasıl öğrendiğini ve eğitimin kalitesinin nihai sonucu neden etkilediğini daha iyi anlamak için, algoritma eğitiminin ne olduğunu anlatan bu ayrıntılı makaleyi okuyabilirsiniz.
Naive Bayes basit bir yöntemdir, ancak bazı pratik hataları affetmez.
İlk hata: Sıfır sıklığı sorununu göz ardı etmek.
Belirli bir sınıf için bir kelime veya değer eğitim verilerinde hiç geçmiyorsa, olasılık sıfıra düşebilir ve hesaplamayı bozabilir. Bu nedenle, sayılara küçük bir düzeltme ekleyen Laplace yumuşatma yöntemi sıklıkla kullanılır.
İkinci hata: birbiriyle çok yakından ilişkili özellikler kullanmak.
Eğer iki sütun neredeyse aynı bilgiyi veriyorsa, model sinyali fazla tahmin etme riski taşır. Model, bu iki ipucunun neredeyse birbirinin aynısı olduğunu “anlayamaz”.
Üçüncü hata: ham olasılıklara fazla güvenmek.
Naive Bayes genellikle iyi bir sıralama yapar, ancak olasılıkları fazla kesin olabilir. İş dünyası açısından bu, sıralamanın yararlı olabileceği, ancak olasılığın kesin değerinin dikkatli bir şekilde yorumlanması gerektiği anlamına gelir.
Bu riskleri azaltmak için şunları yapmanızda fayda var:
Naif Bayes sınıflandırıcılarının gerçek değeri, onları matematiksel bir alıştırma olarak görmeyi bırakıp öncelik belirleme aracı olarak kullanmaya başladığınızda ortaya çıkar. İş dünyasında, doğru sınıflandırma yapmak neredeyse her zaman daha iyi kararlar vermek anlamına gelir.

İşlem akışlarını, işlem açıklamalarını ve geçmiş verileri analiz eden bir finans ekibini düşünün. Her satır sadece bir kayıt değildir. Bu, potansiyel bir karardır: işlemden geçirmek, daha ayrıntılı incelemek, engellemek ya da bir analiste iletmek.
Naive Bayes ile farklı göstergeleri tek bir sınıflandırmada birleştirebilirsiniz. Bunların bazıları sayısal, bazıları ikili, bazıları ise metin tabanlıdır. Model, hangi vakaların normal veya anormal olarak gözlemlenmiş kalıplara daha çok benzediğini anlamaya yardımcı olur.
Bunun pratik faydası iki yönlüdür:
Yasal düzenlemelerin geçerli olduğu ortamlarda insan yargısının yerini almaz. Onu düzenler. Ve yüksek hacimli operasyonel süreçlerde bu, gerçek bir fark yaratır.
Pazarlamada sınıflandırma, genellikle her müşteriyi bir hedef gruba atamak anlamına gelir. Sadık müşteriler. Fiyata duyarlı müşteriler. Kaybetme riski olan müşteriler. Promosyonlara duyarlı müşteriler. Hareketsiz müşteriler.
Burada Naive Bayes, farklı türdeki sinyalleri hızlı bir şekilde bir araya getirebildiği için yararlıdır:
Bir CRM ekibinin mükemmel bir insan davranış teorisine ihtiyacı yoktur. Mantıklı adımlar atabilmesini sağlayacak kadar iyi bir segmentasyona ihtiyacı vardır. Örneğin, mesajı, iletişim sıklığını veya teklif türünü değiştirmek gibi.
Bir model, doğru müşteriye yönelik bir sonraki mesajın seçilmesine yardımcı olduğunda, halihazırda operasyonel değer yaratıyor demektir.
Perakende ve e-ticarette sınıflandırma, birbirinden farklı gibi görünen ancak aynı mantığı paylaşan faaliyetleri destekler: kaosu düzenlemek.
Ürünleri satış profillerine göre sınıflandırabilirsiniz. Hangi kategorilerin sorunlara yol açtığını anlamak için yorumları ve destek taleplerini inceleyebilirsiniz. Ekibin promosyonları ve stokları daha net bir şekilde planlamasına yardımcı olacak talep kalıplarını tespit edebilirsiniz.
Bu tür ortamlarda veriler genellikle çok sayıda, çeşitlilik arz eder ve her zaman kusursuz değildir. Bu nedenle hızlı, ölçeklenebilir ve anlaşılır bir model büyük önem taşır. Bu, en göz alıcı model olduğu için değil, iş akışına entegre olup onu yavaşlatmadığı içindir.
İş dünyasına uygulanan analitik yaklaşımlarının somut projelerde nasıl hayata geçtiğini görmek isterseniz, bu vaka çalışmalarına göz atabilirsiniz.
Naive Bayes algoritmasını anlamak faydalıdır. Ancak bunu kurumsal bir ortamda doğru bir şekilde uygulamak bambaşka bir konudur.
Sorun neredeyse hiçbir zaman sadece algoritmada değildir. Asıl iş, modelin etrafında döner. Farklı veri kaynaklarını birbirine bağlamalı, eksik alanları yönetmeli, metinleri hazırlamalı, etiketleri güncellemeli, çıktıların kalitesini kontrol etmeli ve sonuçları karar vericiler için anlaşılır bir şekilde yorumlamalısınız.
Bir KOBİ için bu aşama genellikle kritik bir noktadır. Bunun nedeni yapay zekaya ilginin olmaması değil, ekibin zamanının sınırlı olması ve operasyonel önceliklerin ertelenemeyecek olmasıdır.
Bu noktada, teknik karmaşıklığı üstlenen bir platform kullanmak mantıklıdır. Yapay zeka destekli bir çözüm, işletmenin kod yazmasını, kütüphaneler seçmesini veya manuel iş akışlarını yönetmesini gerektirmeden ham verileri anlaşılır içgörülere dönüştürmeyi sağlar.
ELECTE gibi bir platform , yani KOBİ'ler için yapay zeka destekli bir veri analizi platformu, makine öğrenimi konusunda uzmanlık gerektirmeden naif Bayes sınıflandırıcıları gibi yöntemleri erişilebilir hale getirir. Bunun avantajı sadece hız değildir. Asıl avantaj, veri ile karar arasındaki sürtüşmenin azalmasıdır.
Otomasyon düzgün çalıştığında, ekip artık formüller üzerinden düşünmez. Bunun yerine, faydalı sorular üzerinden düşünür:
Bu nedenle, giderek daha fazla şirket, yapay zeka tarafından üretilen içeriklerin güvenilirliğini ve iç süreçlerde dolaşan metin sinyallerini değerlendirmelerine yardımcı olacak araçlar arıyor. Bu bağlamda, özellikle ekibiniz belgeler, içerikler ve dil denetimleri ile çalışıyorsa, İtalyanca bir yapay zeka tespit aracı kılavuzuna başvurmak da faydalı olabilir.
Pratikte fark çok basit. Parça parça teknik adımlarla uğraşmak yerine, dikkatinizi şirketin sonuçlarına yöneltirsiniz. İşte bu noktada yapay zeka sadece ilgi çekici olmakla kalmaz, gerçekten uygulanabilir hale gelir.
Naif Bayes sınıflandırıcıları önemli bir ders vermektedir. Analitik alanında, doğru uygulanan basitlik, kötü yönetilen karmaşıklığı geride bırakabilir.
Sezgisel bir olasılık temeli, iyi bir ölçeklenebilirlik ve oldukça somut kullanım örnekleri sayesinde, bu yaklaşım bilgileri sınıflandırmak, gizli sinyalleri okumak ve daha güvenli bir şekilde hareket etmek isteyen şirketler için güvenilir bir araç olmaya devam ediyor. Bunların değerini anlamak için makine öğrenimi uzmanı olmaya gerek yok. Önemli olan matematiği operasyonel kararlarla birleştirmektir.
Bu bağlantı netleştiğinde, yapay zeka teknik bir konu olmaktan çıkar ve kurumsal bir avantaj haline gelir. İşte o noktada tahminler etkisini göstermeye başlar.
Dağınık verileri net içgörülere dönüştürmek istiyorsanız, ELECTE'yi deneyin. Bu platform, KOBİ'lerin veri kaynaklarını birbirine bağlamasına, analizleri otomatikleştirmesine ve daha hızlı ve bilinçli kararlar almak için yararlı raporlar ve tahminler elde etmesine yardımcı olur.

.svg)
.svg)
.svg)






