

Ви легко можете опинитися в такій ситуації: у вас є система управління, можливо, CRM, кілька файлів Excel, які надсилаються електронною поштою, а тим часом хтось каже вам, що для «серйозної аналітики» потрібно обирати між «озером даних» і «сховищем даних». У цей момент розмова одразу переходить на технології, але справжня проблема в іншому. Чи справді вам потрібна нова архітектура даних, чи просто потрібно зробити вже наявні дані зрозумілими та корисними?
Для малого та середнього бізнесу це розрізнення має більше значення, ніж просто термінологія. Неправильний вибір призводить не лише до технічних складнощів. Він спричиняє затягування проектів, залежність від консультантів, запізнення зі звітами та інвестиції, які не завжди перетворюються на кращі рішення. Однак рішення нічого не робити змушує компанію діяти навмання.
Справа не в тому, щоб вивчити жаргон постачальників. Справа в тому, щоб зрозуміти, яке рішення відповідає вашому бізнесу, вашому бюджету та тим компетенціям, якими ви насправді володієте. Тут ви знайдете практичний посібник, який допоможе поглянути на дискусію «дата-лейк проти дата-сховища» очима того, хто має збалансувати витрати, доступність та операційний прибуток.
Сьогодні тиск з боку керівництва щодо «використання даних» є цілком реальним. Обсяги даних зростають, джерел стає дедалі більше, а менеджери вимагають швидших прогнозів, інформаційних панелей та сповіщень. Тим часом на розгляд виноситься низка термінів, які, здається, змушують вас негайно прийняти рішення щодо архітектури системи.
Однак для багатьох малих та середніх підприємств саме в цьому і полягає пастка. Вас переконують, що першим кроком має бути вибір між двома моделями інфраструктури, тоді як насправді проблема часто набагато конкретніша: розрізнені дані, несумісні формати, ручне формування звітів і відсутність людей, які б мали час навести лад.
Є й інші важливі питання. Чи справді у вас проблема з архітектурою? Або, можливо, проблема полягає в доступі до даних? Якщо ви оберете неправильне рішення, ви ризикуєте вкласти кошти в технічний проєкт замість того, щоб покращити контроль над бізнесом. Якщо ж ви нічого не оберете, то й надалі будете приймати рішення на основі неповної інформації.
Керівнику малого чи середнього підприємства не потрібні університетські лекції. Йому потрібні прості критерії, щоб зрозуміти, що потрібно, а що ні, і де ховаються справжні витрати.
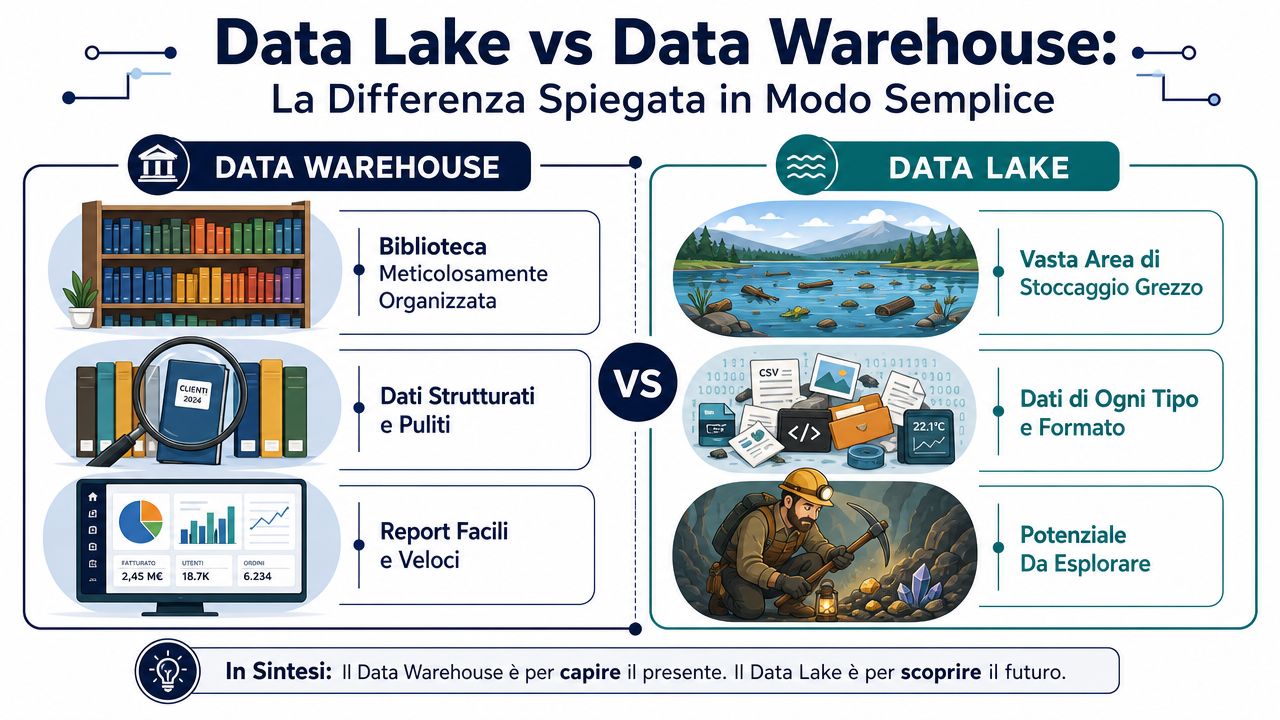
Найкраще цю різницю можна зрозуміти на прикладі двох дуже наочних зображень.
Сховище даних нагадує добре організовану бібліотеку. Кожна книга надходить уже каталогізованою, класифікованою та розміщеною на відповідній полиці. Коли ви шукаєте інформацію, ви швидко її знаходите, оскільки порядок було визначено заздалегідь. Натомість «озеро даних» нагадує велике сховище, куди надходять коробки найрізноманітнішого змісту. Ви кладете туди впорядковані файли, журнали, PDF-файли, зображення, експортовані дані з системи управління, веб-дані. Порядок ви встановлюєте пізніше, коли вам потрібно їх проаналізувати.
Тут варто згадати єдиний технічний нюанс, який дійсно заслуговує на увагу.
Ця відмінність також відображає їхнє історичне походження. Склад даних (data warehouse) було створено для бізнес-аналітики на основі вже очищених та структурованих даних, тоді як озеро даних (data lake) з’явилося пізніше для зберігання необроблених даних у різноманітних форматах. Саме тому склад даних краще підходить для звітності та ключових показників ефективності (KPI), тоді як озеро даних є більш гнучким для аналізу та машинного навчання, як пояснюється в цьому аналізі відмінностей між складом даних та озером даних.
Склад даних добре підходить для пошуку відповідей на вже відомі запитання. Озеро даних стає у нагоді, коли ви знаєте, що дані можуть містити цінну інформацію, але ще не знаєте, у якому саме вигляді.
Якщо ваша мета — отримати інформацію про продажі, рентабельність, замовлення, запаси, затримки, результати діяльності та щомісячні порівняння, то система «Warehouse» концептуально найкраще відповідає вашим потребам. Вона забезпечує надійну основу для стандартних звітів, послідовних SQL-запитів та відтворюваних даних.
Якщо ж ви працюєте з дуже різними типами даних, такими як системні журнали, PDF-файли, електронні листи, тексти, зображення або машинні потоки, «озеро даних» надає більше свободи. ІТ-команди можуть централізувати різнорідні джерела, тоді як фахівці з підготовки звітності й надалі віддають перевагу структурованим середовищам для швидкого та узгодженого аналізу. У цей контекст вписується й ширша тема прийняття рішень на основі даних у бізнесі, для чого необхідні насамперед доступні дані, а вже потім — складні технології.
У дискусії щодо того, що краще — «озеро даних» чи «сховище даних», багато хто плутає гнучкість із миттєвою користю.
Дата-лейк може містити майже все. Але те, що він щось містить, ще не означає, що ці дані можна відразу проаналізувати. Дата-сховище менш гнучке на етапі введення даних, але більш корисне, коли потрібні швидкі та стандартизовані відповіді. Для малого та середнього бізнесу ця різниця має більше значення, ніж теорія. Адже проблема не в тому, щоб зберігати більше даних. А в тому, щоб приймати кращі рішення.
Дві компанії можуть мати однакові вихідні дані, але отримувати зовсім різні результати. Часто різниця полягає не в обсязі зібраних даних, а в тому, як їх систематизують, готують і роблять доступними для осіб, які приймають рішення.
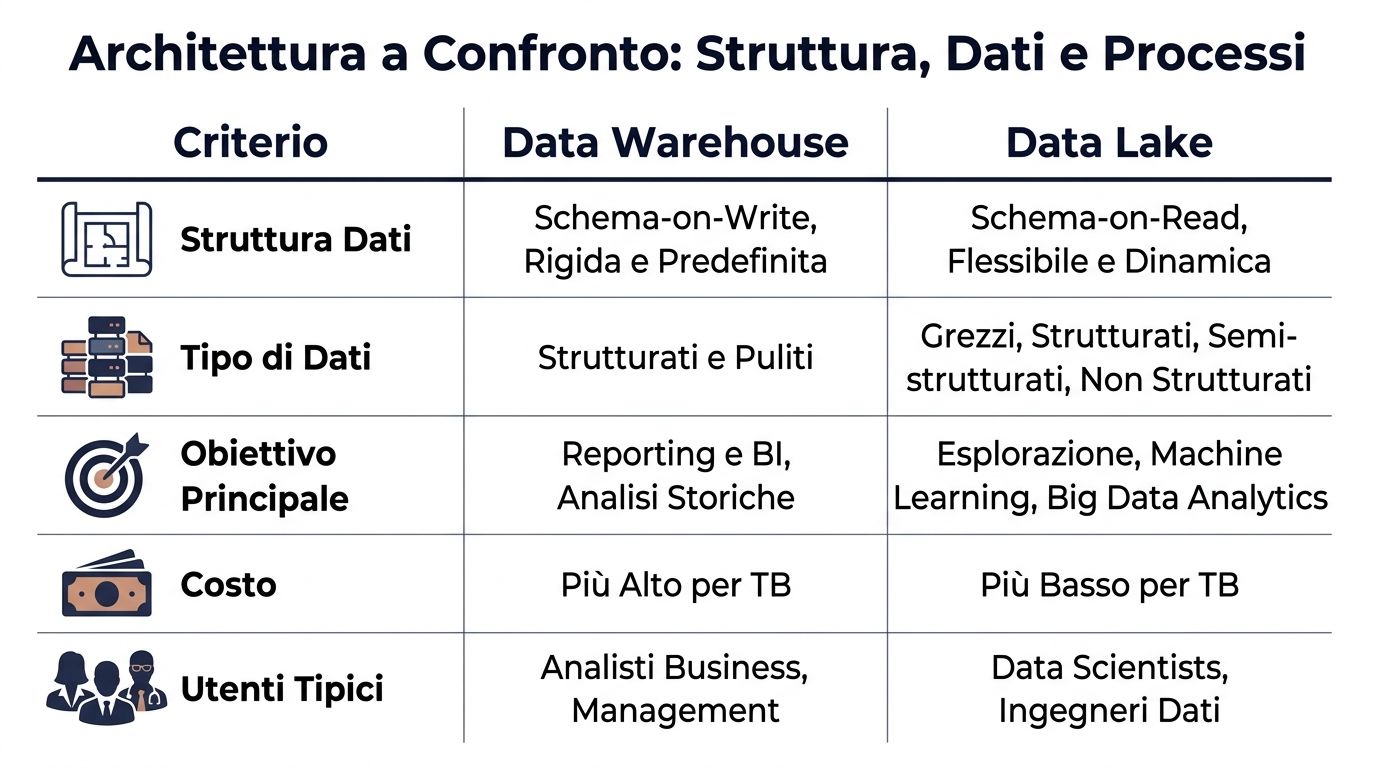
| Критерій | Сховище даних | Озеро даних |
|---|---|---|
| Структура даних | Схема при записі, визначена до завантаження | Схема під час читання, що визначається під час аналізу |
| Тип даних | Насамперед — впорядковані та охайні | Структуровані, напівструктуровані та неструктуровані |
| Типовий процес | ETL: спочатку перетворюйте, а потім завантажуйте | ELT: спочатку завантаження, потім перетворення |
| Типові користувачі | Бізнес-аналітик, фінанси, управління | Інженер з обробки даних, науковець з даних, технічні команди |
| Очікувані показники | Більш передбачувані для бізнес-аналітики та звітності | Більше змінних, залежать від запиту та підготовки |
У сховищі даних класичний процес — це ETL: витяг даних, їх перетворення та завантаження. Спочатку це вимагає більше зусиль, але згодом зменшує труднощі. Користувач, який переглядає інформаційну панель, бачить узгоджені поля, стабільні визначення та KPI, значення яких не змінюється від відділу до відділу.
У «озері даних» потік даних зазвичай будується за принципом ELT: спочатку витягують, потім завантажують, а перетворюють лише згодом, якщо це потрібно. Такий підхід надає більшу технічну свободу, але відкладає частину роботи на потім. Для малого чи середнього підприємства таке відкладення часто означає накопичення завдань, які потім лягають на плечі команди в найгірший момент — саме тоді, коли потрібна швидка реакція.
Практична порада: якщо кілька осіб мають ознайомитися з одним і тим самим документом та ухвалити оперативні рішення, структура, визначена до завантаження, дозволяє уникнути помилок, зайвих суперечок та втрати часу.
З оперативної точки зору, сховище даних призначене для повторюваних запитів, регулярних звітів та інформаційних панелей, які використовуються щодня. Озеро даних добре справляється з великими обсягами та різними форматами, але час відгуку та зручність використання значною мірою залежать від того, як дані були каталогізовані, підготовлені та організовані. Технічне порівняння, опубліковане CloudOptimo, добре підсумовує цю думку: сховище даних націлене на передбачуваність, а озеро даних — на гнучкість.
Для малого та середнього бізнесу це питання не є суто теоретичним. Коли керівник відділу продажів відкриває ранковий звіт, він хоче бачити чіткі цифри та оперативні результати. Натомість, якщо технічна команда має аналізувати файли, журнали або різнорідні документи, вона може погодитися на більшу затримку в обмін на більш широкий обсяг зібраних даних.
Практична різниця полягає не лише в технічних аспектах. Різниця полягає в тому, хто вміє користуватися даними, не звертаючись щоразу за допомогою.
Добре налагоджене сховище даних наближає дані до бізнесу. А саме «озеро» даних частіше наближає їх до технічної команди. Саме тому багато малих і середніх підприємств запізно усвідомлюють одну незручну річ: справжній вибір полягає не між двома технологіями, а між системою, яка робить дані доступними, та системою, яка лише зберігає їх, не перетворюючи на кращі рішення.
Тим, хто розглядає ці варіанти в рамках проекту з модернізації ІТ, слід враховувати не лише репозиторій, а й операційну модель. Хмарні рішення для малого та середнього бізнесу допомагають зрозуміти саме цей аспект: де закінчується інфраструктура і де починаються витрати, необхідні компетенції та повсякденні обов’язки.
«Озеро даних» часто подають як найбільш економічний варіант, оскільки воно зберігає необроблені дані та зменшує обсяг початкової роботи. Це правда лише частково. Якщо відсутні каталог, правила доступу, послідовна система іменування та мінімальний контроль якості, початкова економія перетворюється на втрачений час на пошук файлів, відновлення визначень та перевірку надійності даних.
Саме тому для багатьох малих та середніх підприємств правильне порівняння не полягає в абстрактному протиставленні «озера» та «складу». Корисне запитання інше: чи справді потрібно будувати одну з цих комплексних архітектур, чи доцільніше почати з більш легкого рівня, який дасть швидкий аналітичний огляд, не навантажуючи систему відразу всією цією складністю?
Для малого та середнього бізнесу найдорожча помилка часто виникає через неправильно сформульоване запитання: «Що дешевше — data lake чи data warehouse?». У компанії справжній рахунок приходить пізніше. Він приходить тоді, коли дані не взаємодіють між собою, звіти ламаються при кожній зміні системи управління, а кожен запит проходить через консультантів або розробників, а не через команду, яка має приймати рішення.

Зберігання даних займає менше часу, ніж здається. Більше часу вимагають ті завдання, які забезпечують надійність і практичну корисність даних: моделювання, інтеграція, управління доступом, контроль якості, моніторинг, виправлення помилок та підтримка користувачів.
Створення сховища даних вимагає певних зусиль на початковому етапі. Необхідно визначити показники, побудувати конвеєри даних, узгодити джерела та підтримувати все в порядку, коли змінюються ERP-системи, CRM-системи або бізнес-правила. Натомість керівництво отримує більш стабільні показники, а звітність стає більш передбачуваною.
Дата-лейк часто пропонується як більш просте рішення. Ви завантажуєте дані різних типів і відкладаєте частину рішень щодо структури. Проблема полягає в тому, що таке відкладення не позбавляє вас роботи. Воно лише переносить її на пізніший етап, де вона проявляється у вигляді каталогізації, забезпечення безпеки, обчислювальних витрат, дублювання, несумісних версій та постійних перевірок того, які дані є дійсно надійними.
Для малого та середнього підприємства існує ризик заплатити двічі. Спочатку за збір даних. Потім за те, щоб нарешті зробити їх доступними для аналізу.
Справжня складність полягає не в технічних аспектах. Вона полягає в операційних аспектах.
Якщо кожен новий звіт вимагає ручного втручання, якщо фінансовий директор і менеджер з продажу використовують різні визначення одного й того самого показника, якщо підприємець змушений чекати кілька днів, щоб отримати достовірні дані, то проект з обробки даних уже з’їдає прибуток. Навіть якщо інфраструктура, на папері, виглядає сучасною.
Тому варто оцінювати не лише архітектуру, а й модель управління. Хмарні рішення для малого та середнього бізнесу допомагають саме розібратися в цій різниці: що ви насправді купуєте, яка частина технічного обслуговування залишається під вашим контролем і наскільки ви щомісяця залежите від кваліфікованих фахівців.
На італійському ринку ті, хто інвестує в аналітику, прагнуть отримати відчутні результати. Скорочення ручної праці. Швидше укладення угод. Кращий контроль над продажами, рентабельністю, запасами та грошовими потоками. А не складна платформа, доступ до якої мають лише одиниці.
Це змінює критерії вибору. МСП не слід задаватися питанням, яка архітектура є більш привабливою чи гнучкішою в абстрактному сенсі. Воно має з’ясувати, скільки часу потрібно для створення надійних інформаційних панелей, скільки людей знадобиться для їхнього обслуговування та як швидко проект почне приносити користь.
У роздрібній торгівлі приховані витрати швидко випливають на поверхню. Якщо дані про продажі, повернення, акції та залишки надходять із різних систем, достатньо одного неправильного визначення понять «маржа» чи «чистий обсяг продажів», щоб підірвати довіру до звітів. У такому разі проблема полягає не в обраній базі даних. Проблема в тому, що власник знову починає приймати рішення на основі Excel.
У сфері фінансів ціна помилки стає ще більш очевидною. Звітність, звірка даних, управлінський контроль та аналіз відхилень вимагають узгоджених і простежуваних даних. Якщо кожна перевірка викликає суперечки щодо походження цифр, проект втрачає рентабельність інвестицій ще до свого завершення.
Тому на практиці багатьом малим та середнім підприємствам не потрібно створювати з нуля повноцінне озеро даних або сховище даних. Їм потрібна більш компактна, зручна в управлінні та орієнтована на прийняття рішень система.
Якщо вам не вдається забезпечити стабільну якість даних, дотримання правил доступу та узгодженість визначень упродовж часу, проблема полягає не у виборі між «озером» і «складом». Проблема в тому, що ви придбали складну систему, не маючи на той момент сценарію використання, який би це виправдовував.
Питання не в тому, яка архітектура є «найкращою» в абсолютному сенсі. Питання в тому, яку проблему вам потрібно вирішити завтра вранці.

У роздрібній торгівлі склад працює ефективно, коли доводиться постійно відповідати на одні й ті самі операційні питання:
Те саме стосується і сфери фінансів. Якщо вам потрібно об’єднувати структуровані дані, складати періодичну звітність, аналізувати портфелі або оцінювати економічні тенденції за стабільними критеріями, сховище даних залишається очевидним вибором.
Лейк доречний у тих випадках, коли ваша компанія збирає дуже різноманітні дані, а ви не хочете або не можете заздалегідь визначити всі параметри.
Реалістичним прикладом є енергетична компанія, яка поєднує:
У таких умовах традиційний сховище даних змушує вас спочатку проєктувати взаємозв’язки між джерелами, які ви, можливо, ще не до кінця розумієте. Озеро даних дозволяє централізувати всі дані та надавати їм структуру лише тоді, коли це потрібно для конкретного аналізу. Саме в таких ситуаціях гнучкість озера даних і створює справжню цінність.
Дата-лейк — це не просто «сучасніший» варіант. Це розумний вибір лише тоді, коли різноманітність даних виправдовує ту складність, яку ви на себе берете.
Більшість малих та середніх підприємств не стикаються з такою ситуацією. Вони переважно мають дані з ERP, CRM, електронної комерції, бухгалтерії, а також у форматі CSV та Excel. У таких випадках проблема полягає не в обробці відеофайлів, журналів програм або текстових даних у великих обсягах. Проблема полягає в тому, щоб мати чисті, узгоджені та зрозумілі для нефахівців дані.
Тут слід чітко зазначити: часто не потрібні ані «озеро даних», ані традиційне сховище даних.
Натомість потрібно:
Lakehouse намагається поєднати ці два світи. Він обіцяє гнучкість моделі lake та деякі переваги моделі warehouse в одному середовищі. Це цікавий напрямок, особливо для компаній із змішаними робочими навантаженнями у сферах бізнес-аналітики, штучного інтелекту та науки про дані.
Однак для малого та середнього бізнесу питання залишається тим самим: чи справді у вас є проблема, яка вимагає таких масштабних заходів? Якщо вам потрібно краще аналізувати продажі, рентабельність, грошові потоки чи прогнози, то навіть найдосконаліше гібридне рішення може виявитися надто дорогим порівняно з очікуваною вигодою.
Концепція «data lakehouse» була розроблена для подолання жорсткого розмежування між «lake» та «warehouse». Ідея проста: зберегти гнучкість великого та відкритого сховища даних, але додати до нього впорядкованість, продуктивність та аналітичні можливості, що наближаються до характеристик сховища даних. Такі технології, як Databricks та Delta Lake, добре ілюструють цей напрямок.
Теоретично це дуже привабливо. Ви використовуєте одну й ту саму базу даних для бізнес-аналітики, розширеного аналізу та машинного навчання, уникаючи надмірного дублювання інформації між різними системами. Для великих організацій або досвідчених команд, що працюють з даними, це логічне рішення для екосистеми, яка з часом стала дедалі складнішою.
В академічних тестах архітектура data lakehouse оцінюється за такими показниками, як пропускна здатність, затримка та накладні витрати на метадані. Це свідчить про те, що порівняння з data warehouse стосується не лише функціональних аспектів, а й продуктивності, особливо в сценаріях, де навіть незначні відмінності у продуктивності мають істотний вплив, як підкреслюється в цій академічній презентації, присвяченій тестам data lakehouse.
Перекладено на ділову італійську: Lakehouse вирішує проблеми організацій, які вже досягли певного рівня масштабу, складності та спеціалізації.
Якщо вам насправді не потрібні були ані «озеро даних», ані «сховище даних», то навряд чи вам знадобиться система, яка поєднує в собі обидва ці компоненти.
Для більшості малих та середніх підприємств найкориснішим питанням є не «яку архітектуру обрати?», а «як отримати надійні аналітичні дані, не перетворюючи проект з обробки даних на безкінечний будівельний майданчик?».
Це третій підхід, якого бракує в багатьох порівняннях «озера даних» та «сховища даних». Не створюйте нову пропрієтарну інфраструктуру. Натомість додайте рівень аналізу поверх систем, якими ви вже користуєтеся, винісши технічну складність за межі операційної сфери діяльності компанії.

На практиці найраціональніший підхід полягає в наступному:
Я бачив, як чимало малих і середніх підприємств витрачали місяці на створення традиційного сховища даних, а потім майже ним не користувалися. Не тому, що воно було погано побудоване. А тому, що ніхто в компанії не вмів самостійно здійснювати запити до нього. Проблема полягала не в базі даних, а в її доступності.
Цей момент часто недооцінюють. Вишукана архітектура, яка завжди вимагає залучення технічного посередника, знижує практичну цінність даних. Простіше рішення, яке є зрозумілим для керівництва, часто дозволяє швидше приймати кращі рішення.
Саме тому багато компаній отримують більше користі від добре розробленого програмного забезпечення для бізнес-аналітики для малого та середнього бізнесу, ніж від надмірно потужної інфраструктурної системи. Їхня мета полягає не в тому, щоб мати власне сховище даних, а в тому, щоб краще і швидше розуміти свій бізнес.
Правильна інфраструктура — це та, яку ваша команда вміє використовувати, підтримувати та перетворювати на рішення. А не та, що вражає на технічній презентації.
Дискусія щодо того, що краще — «озеро даних» чи «сховище даних», — є корисною, але для малого та середнього бізнесу вона часто починається з неправильного питання. Перш ніж обирати архітектуру, вам слід з’ясувати, чи справді у вас є проблема з масштабом та різноманітністю даних, чи ж це набагато поширеніша проблема: розрізнені дані, ручне формування звітів та обмежений доступ до них.
Дата-склад залишається найкращим рішенням, коли потрібні надійна звітність, узгоджені ключові показники ефективності та передбачувана продуктивність. Дата-озеро доцільне, коли різноманітність джерел вимагає більшої гнучкості та більшої складності. Модель «лейкхаус» — це цікавий крок у розвитку, але вона рідко є правильним першим кроком для компаній, які насамперед прагнуть оперативного контролю та рентабельності інвестицій.
Найрозумніший вибір — це не найсучасніша технологія. Це вибір, який відповідає реальній проблемі, наявним компетенціям та швидкості, з якою ви хочете перетворювати дані на рішення.
Якщо ви хочете перетворити корпоративні дані на звіти, прогнози та оперативні висновки без створення складної інфраструктури, ознайомтеся з ELECTE — платформою для аналізу даних на базі штучного інтелекту, призначеною для малого та середнього бізнесу. Ви можете почати з тих даних, які вже маєте, зменшити обсяг ручної роботи та зробити аналітику доступною для своєї команди завдяки набагато простішому підходу.

.svg)
.svg)
.svg)






