

Фінансові відділи малих та середніх підприємств добре це знають: щоразу, коли ви намагаєтеся імпортувати PDF-файл в Excel, починається боротьба з форматуванням. Класичне копіювання та вставлення майже завжди закінчується катастрофою: розкидані дані, випадково об’єднані комірки та впорядковані таблиці, що перетворюються на нечитабельний хаос. Фрустрація цілком реальна, але ви в цьому не винні. Проблема полягає в самій природі формату PDF, який призначений для друку та обміну, а не для використання як джерело даних для аналізу.
Цей ручний робочий процес, що складається з банківських виписок, рахунків-фактур від постачальників та документів державних органів, є справжньою «чорною дірою» для продуктивності. Окрім того, що це нудно, це майже гарантоване джерело помилок при введенні даних. На щастя, у 2026 році у вашому розпорядженні є набагато розумніші методи для подолання цього виклику. У цьому посібнику ми крок за кроком продемонструємо найефективніші стратегії — від інтегрованих у Excel до рішень на базі штучного інтелекту, які повністю усувають ручну роботу, дозволяючи вам перейти від вилучення даних до їх аналізу за лічені хвилини.
Проблема полягає в одному принциповому розрізненні: формат PDF було створено для того, щоб зберегти зовнішній вигляд документа на будь-якому пристрої, а не для збереження логічної структури даних, що містяться в ньому. Розуміння відмінностей між різними типами PDF-файлів — це перший крок до вибору правильного інструменту та уникнення марної трати часу.
Ця ілюстрація чудово відображає розчарування тих, кому доводиться ламати голову над складним PDF-файлом і захаращеною таблицею.

Саме в цей момент ручний процес стає перешкодою для продуктивності, що свідчить про необхідність більш ефективного способу імпортування PDF-файлу в Excel.
Можливо, ви цього не знали, але найпростіший спосіб імпортувати PDF-файл в Excel вже вбудовано в програму, якою ви користуєтеся щодня. Ця функція називається Power Query — це потужний інструмент для «отримання та перетворення даних», який компанія Microsoft включила до Excel.

Це ідеальне рішення для періодичного імпорту простих і добре структурованих PDF-файлів, таких як прайс-лист або список контактів. Його головна перевага? Це безкоштовний сервіс, який не вимагає додаткового встановлення.
Дані будуть внесені до нового аркуша, вже відформатованого як таблиця Excel, і готові до використання.
Power Query — це чудова річ, але вона має свої обмеження. Найкраще вона працює з простими таблицями, що вміщуються на одній сторінці. У більш складних ситуаціях її продуктивність різко падає:
Якщо ви часто працюєте з аналізом даних, вам може бути цікаво ознайомитися з інтеграцією з Power BI, яка використовує ту саму технологію. Крім того, вміння працювати з іншими форматами має вирішальне значення; наш посібник з роботи з файлами CSV в Excel може надати вам корисні поради.
Якщо у вашій компанії вже є ліцензія на Adobe Acrobat Pro, його функція експорту є одним із найнадійніших рішень. Вона часто випереджає Power Query у збереженні форматування складних таблиць із нестандартним макетом.
Процес дуже простий: відкрийте PDF-файл, перейдіть до меню «Усі інструменти», виберіть «Експортувати PDF», встановіть формат «Електронна таблиця» та збережіть новий файл Excel.
Результат майже завжди виходить чітким і акуратним. Однак є два основні недоліки:
Такі сервіси, як iLovePDF, Smallpdf або відкритий програмний продукт Tabula, надзвичайно зручні: просто перетягніть файл, натисніть кнопку — і завантажте результат. Вони стануть чудовим варіантом для періодичного перетворення даних, що не містять конфіденційної інформації.
Однак за цією зручністю ховається величезний ризик: безпека даних.
Завантаження документа на сторонній сервер фактично означає втрату контролю над ним. Якщо цей PDF-файл містить виписки з рахунків, дані клієнтів, конфіденційні прайс-листи або будь-яку іншу стратегічну інформацію, ви наражаєте свою компанію на потенційні порушення конфіденційності та серйозні ризики щодо дотримання вимог GDPR.
Для малих та середніх підприємств, що працюють у Європі, це не дрібниця. Використовувати онлайн-конвертер для аналізу публічного звіту Istat — це цілком прийнятно. Але робити це з фінансовими даними вашої компанії — це ризикований крок, який слід ретельно зважити.
Якщо вашій команді доводиться обробляти десятки виписок, рахунків-фактур або звітів, які щомісяця надходять в одному й тому ж форматі, ручне вилучення даних — це не просто клопітка робота, а справжнє оперативне вузьке місце.
Для малих та середніх підприємств, які обробляють великі обсяги стандартизованих документів, автоматизація за допомогою скриптів Python — це не розкіш, а цілеспрямована інвестиція в ефективність. Звісно, для цього потрібні технічні знання, але окупність інвестицій є надзвичайно високою завдяки економії часу та усуненню помилок.

Python лідирує в цій галузі завдяки безкоштовним і надзвичайно потужним бібліотекам, таким як pdfplumber і Камелот, розроблені спеціально для розпізнавання та відновлення структури таблиць, що містяться у PDF-файлах.
pdfplumber: Цей надзвичайно універсальний інструмент чудово підходить для вилучення таблиць, тексту та метаданих, аналізуючи розташування кожного окремого символу.Камелот: Спеціалізується на витягуванні даних із таблиць та пропонує сучасні алгоритми для роботи з таблицями як із видимими, так і без видимих розділових ліній.Практичний приклад: уявіть, що наприкінці місяця ви отримуєте 50 рахунків-фактур від постачальника. Замість того, щоб витрачати на це години робочого часу, скрипт на Python може просканувати їх, витягти суми та дати, а також створити файл Excel, готовий до аналізу. Все це займає менше хвилини й повністю виключає ризик людських помилок.
Після вилучення та структурування ці дані можна надсилати на аналітичні платформи. Щоб дізнатися більше про те, як інтегрувати ці дані в більш масштабні потоки, ознайомтеся з принципом роботи API-інтерфейсів ELECTE, які дозволяють автоматизувати надсилання даних на нашу платформу.
Коли традиційні методи виявляються неефективними, на допомогу приходить штучний інтелект. Платформи на базі штучного інтелекту, такі як ELECTE правила гри, особливо коли йдеться про відскановані документи або документи зі складним макетом.
Не будемо говорити про старий OCR, який обмежувався лише «читанням» тексту. Сучасні рішення поєднують OCR із передовими мовними моделями (LLM) для розуміння структури, контексту та взаємозв’язків між даними.
Уявіть собі фінансовий звіт із таблицями, що займають кілька сторінок. Платформа на базі штучного інтелекту здатна:
Це все змінює. Замість того, щоб витягувати необроблені дані, платформа штучного інтелекту «перетравлює» PDF-файл і повертає його у вигляді очищеного набору даних, готового до аналізу. Якщо ви хочете дізнатися більше, ми розповіли про це в нашій статті про найкращі рішення штучного інтелекту для бізнесу.
Справжня цінність штучного інтелекту полягає не у вилученні даних, а у вилученні готової до використання інформації. Ви отримуєте не просто файл Excel, а дані, які ваша команда може одразу використовувати для прийняття стратегічних рішень, не витрачаючи час на їх очищення.
Цікаво знати, що Мілан лідирує серед італійських імпортерів. Але можливість автоматично завантажувати повний звіт про провінції-імпортери дає вашій команді набагато більше можливостей: порівнювати тенденції, оптимізувати запаси та знижувати витрати.
З-поміж такого великого вибору, як вибрати те, що підійде саме вам? Відповідь залежить від чотирьох ключових факторів, які визначають ефективність, безпеку та вартість вашої операції.
Ця схема прийняття рішень допоможе вам наочно побачити логічний шлях до вашого вибору.
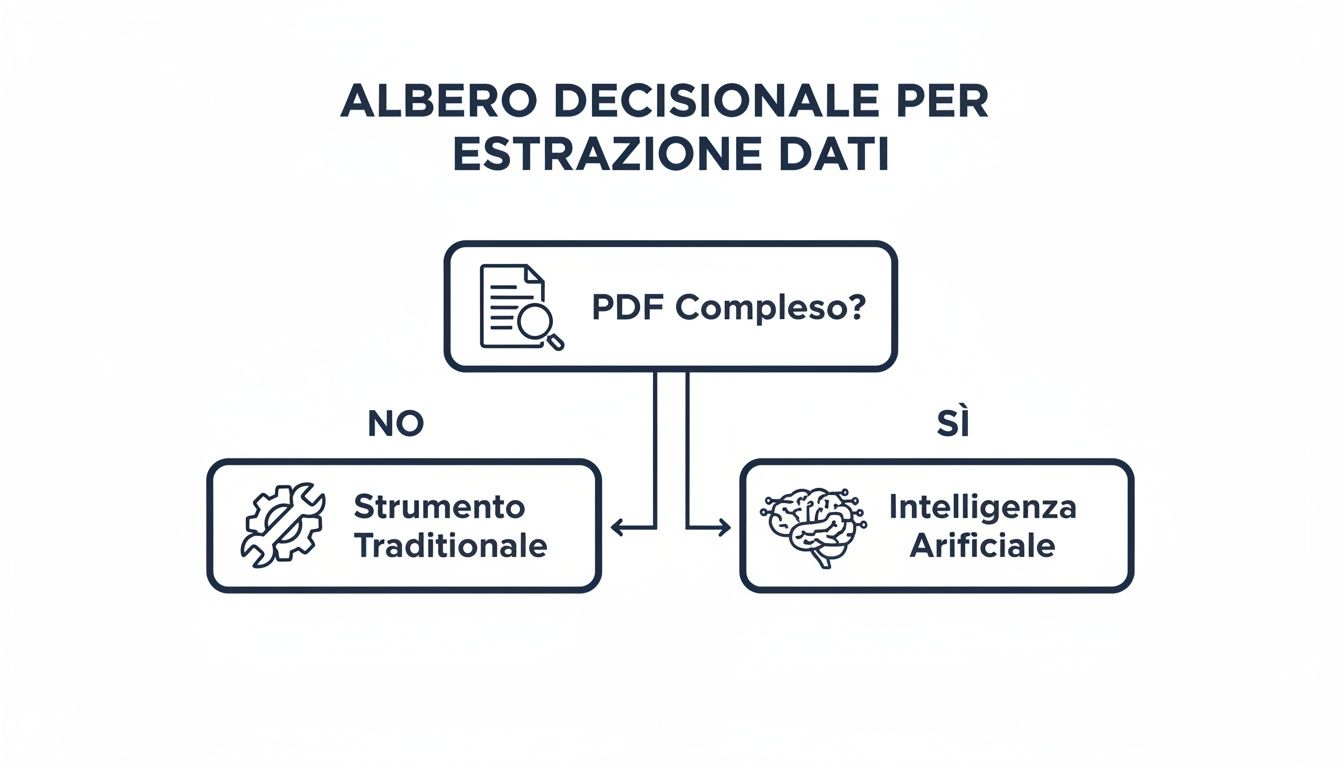
Схема проста: для простих PDF-файлів та епізодичних операцій ідеально підходять традиційні інструменти, такі як Power Query. А для великих обсягів, складних документів та повторюваних робочих процесів платформа на базі штучного інтелекту, така як ELECTE нудне завдання на автоматизований процес, що створює додаткову цінність.
Імпорт PDF-файлу в Excel більше не має бути ручним і виснажливим процесом. Сьогодні у вашому розпорядженні цілий арсенал інструментів — від безкоштовних вбудованих, таких як Power Query, до передових рішень для автоматизації та платформ на базі штучного інтелекту.
Вибір залежить від ваших конкретних потреб: для епізодичних операцій із простими файлами Power Query не має собі рівних. Для обробки постійних обсягів складних і конфіденційних документів автоматизація та штучний інтелект — це вже не розкіш, а стратегічна необхідність. Усунувши ручне вилучення даних, ви не тільки заощаджуєте час і зменшуєте кількість помилок, але й звільняєте свої найцінніші ресурси, щоб зосередитися на тому, що дійсно має значення: аналізі даних для прийняття більш розумних і швидких бізнес-рішень. Ось так ви перетворюєте простий документ на джерело конкурентної переваги.
Готові назавжди попрощатися з функцією «копіювати-вставити»? Дізнайтеся, як ELECTE прискорити прийняття рішень перетворюючи ваші найскладніші PDF-файли на корисну інформацію.

.svg)
.svg)
.svg)






