

Ви отримуєте XML-файл через PEC. Ви відкриваєте його в браузері, бачите безліч тегів і думаєте, що проблема полягає в тому, щоб «прочитати» його. Насправді це лише перша перешкода. Справжня проблема в компанії полягає в іншому: зрозуміти, чи є ці дані правильними, узгодженими та готовими для включення у ваші звіти.
Для багатьох італійських малих та середніх підприємств це питання вже не є суто технічним. З моменту, коли електронне виставлення рахунків стало обов’язковим, формат XML увійшов у повсякденну роботу з адміністрування, управлінського контролю та аналізу. Недостатньо просто переглянути документ. Потрібно вміти розрізняти читабельний файл і надійний файл. Потрібно розуміти, коли достатньо швидкої перевірки, а коли необхідні синтаксичний аналіз, валідація та нормалізація перед завантаженням даних у Excel, систему бізнес-аналітики (BI) або аналітичну платформу.
Якщо ви шукаєте практичний посібник із читання XML-файлів, то правильний шлях такий: починайте з простих методів, з’ясуйте, де виникають проблеми, а потім створіть потік, який перетворює необроблений XML на корисні для бізнесу дані. Саме так можна зменшити кількість помилок і скоротити час між моментами «маю файл» і «маю корисну інформацію».
XML-файл організовує дані в ієрархічну структуру. У ньому є головний елемент, є вкладені розділи, і кожен блок описує інформацію з чітко визначеним значенням. Для тих, хто займається адміністративними процесами, ця деталь є вирішальною у розрізненні даних, які просто можна прочитати, та даних, які дійсно можна використовувати.
Справа не в тому, щоб «відкрити» файл. Справа в тому, щоб з’ясувати, чи може цей файл без помилок інтегруватися в процеси контролю, обліку та аналізу.
Візьмемо, наприклад, електронний рахунок-фактуру. У одному файлі містяться дані про постачальника, дані про клієнта, суми, що підлягають оподаткуванню, ПДВ, позиції товарів, умови оплати, посилання на замовлення, а також часто й винятки, які ускладнюють розуміння документа. У форматі XML ця інформація не розміщується одна під одною, як у звичайному документі. Вона розміщується у чітко визначених місцях, і саме це розташування пояснює, що саме вона означає.
Для менеджера корисним є не розрізнення між тегами та атрибутами в теоретичному сенсі, а між ізольованими даними та надійними даними. Читати «1000,00» поза контекстом мало що дає. А ось якщо прочитати це в потрібному місці файлу, можна зрозуміти, чи це загальна сума документа, оподатковувана база, сума податку чи значення окремого рядка.
Ось тут і з’являється перша оперативна перевага. XML зберігає контекст даних.
Практичне правило: уважно прочитати XML-файл означає перевірити значення, а не лише саме значення.
В Італії це питання набуло актуальності з поширенням електронного виставлення рахунків. У форматі FatturaPA XML став стандартом для податкової документації. Відповідно, його аналіз більше не стосується лише ІТ-відділу. Він зачіпає адміністрацію, управлінський контроль, відділ закупівель та всіх, хто має використовувати ці дані для прийняття рішень.
На практиці я постійно стикаюся з однією й тією ж проблемою. Файл існує, дані є, але час, необхідний для їх перетворення на корисну інформацію, занадто затягується. Співробітник відкриває XML-файл, перевіряє його візуально, копіює значення в Excel, виправляє неоднакові поля, перейменовує постачальників, назви яких написані по-різному, та намагається відтворити категорії витрат, які у файлі не представлені у формі, готовій до аналізу. Витрати тут не лише операційні. Це втрачений час на отримання аналітичних висновків.
З FatturaPA цей ризик стає ще більш очевидним. Два формально правильні файли можуть створювати однакові проблеми під час аналізу, якщо в одному з них використовуються дуже нечіткі описи рядків, якщо посилання на замовлення є неповними або якщо дані про постачальника вводяться з різними варіаціями. У такому випадку проблема полягає не в зчитуванні XML. Проблема полягає в тому, щоб запобігти перетворенню дійсних податкових даних на малонадійні управлінські дані.
Поширеною помилкою є розгляд XML як вкладення, яке потрібно відобразити. У компанії доцільніше розглядати його як структуроване джерело даних, яке слід перевірити, перш ніж використовувати його для формування звітів, інформаційних панелей та моделей витрат. Якщо цей етап організовано неналежним чином, фінансова команда змушена обговорювати цифри, які на перший погляд здаються точними, але насправді базуються на непослідовних класифікаціях.
На початку слід поставити такі питання:
Це дуже конкретні перевірки. Вони допомагають уникнути дублювання постачальників у звітах, неправильного тлумачення ПДВ, неповного заповнення центрів витрат та повільних звірки наприкінці місяця.
Саме тут стає очевидною різниця між технічним аналізом даних та їхньою бізнес-цінністю. Парсер зчитує файл. Добре спроектований процес забезпечує отримання чистих, порівнянних і готових до аналізу даних. Такі платформи, як ELECTE, створюються саме для того, щоб усунути цю різницю, скорочуючи обсяг ручної роботи, яка відокремлює отриманий XML від корисних висновків, необхідних для прийняття кращих рішень.
Для швидкої перевірки окремого файлу не потрібні парсери чи бібліотеки. Потрібно зрозуміти, чи ви проводите візуальну перевірку кількох полів, чи вже маєте справу з даними, які потраплять до бухгалтерії, звітності чи управлінського контролю. Ця різниця має значення, особливо у випадку з FatturePA. Перевірка, проведена сьогодні поспіхом, завтра може перетворитися на помилковий рядок у наборі даних про постачальників.

Браузери, текстові редактори та спеціалізовані програми для перегляду вирішують конкретну проблему: швидке читання вмісту без налаштування технічного процесу. Для окремого файлу цього часто достатньо. Ви можете відкрити XML-файл у Chrome, Edge або Firefox, щоб переглянути його структуру, або скористатися «Блокнотом», WordPad чи TextEdit, якщо хочете безпосередньо перевірити теги. У випадку з електронними рахунками-фактурами спеціальна програма для перегляду робить заголовки, рядки документа, базу оподаткування та ПДВ більш зрозумілими.
Суть полягає в наступному:
| Інструмент | Корисно для | Головна обмеження |
|---|---|---|
| Браузер | Швидкий візуальний огляд конструкції | Не перевіряє узгодженість між полями та розділами |
| Текстовий редактор | Пряма перевірка тегів | Це стає незручним у випадку довгих або вкладених файлів |
| Excel | Попередня перевірка у табличному форматі | Неправильно обробляє ієрархії та повторення |
| Спеціальний переглядач | Більш чітке розуміння рахунків-фактур та податкових документів | Не готує дані для аналізу чи автоматизації |
Якщо вам потрібно перевірити дату документа, номер ПН, загальну суму рахунку-фактури або наявність додатків, ці інструменти підійдуть для цього.
Якщо ж мета полягає в порівнянні постачальників, класифікації витрат або наповненні інформаційної панелі, то саме візуалізація уповільнює роботу та залишає занадто багато місця для ручних помилок. Це класичний розрив між переглядом файлу та отриманням надійних даних у потрібний термін.
Відкриття XML-файлу не означає перевірку правильності даних, які ви будете використовувати у звітах.
Ще один практичний аспект стосується обсягу. Десять рядків можна перевірити навіть вручну. А сотні рахунків-фактур FatturePA — ні. У такому випадку вже доцільно задуматися про повторюваний робочий процес або про інструменти, які зчитують вміст у структурованому вигляді, наприклад, за допомогою API для інтегрованого збору та управління податковими документами.
В Італії найпоширенішою проблемою є не те, щоб відкрити .xml, але зрозуміти, що робити, коли приходить .xml.p7m через PEC. Слід розрізняти прості XML-файли та файли з цифровим підписом. У другому випадку потрібні інструменти, здатні зчитати підпис, витягти вміст і відобразити правильний XML-код, як пояснює Цей посібник присвячений XML та XML P7M у системі PEC.
Тут помилки коштують часу:
Для адміністративного працівника найкорисніша послідовність дій є простою:
Ці методи добре справляються зі своїми завданнями на першому рівні перевірки. Однак вони не вирішують ту проблему, яка справді важить для компанії: перетворення податкових XML-файлів, які часто містять помилки або є недостатньо уніфікованими, на чисті та порівнянні дані, не збільшуючи при цьому час, що проходить від отримання документа до отримання корисної інформації.
Коли файли починають накопичуватися, ручна робота стає нереальною. У такому випадку читання XML-файлів за допомогою коду — це не найкращий варіант. Це перший крок до уникнення повторюваних дій, помилок при копіюванні та несумісних наборів даних.

Надійний підхід до обробки XML завжди базується на одній і тій самій логіці: синтаксичний аналіз, нормалізація, цілеспрямоване вилучення даних. У підручниках з Java та Android правильний алгоритм дій виглядає так: parse(), шляхом нормалізації вала за допомогою doc.getDocumentElement().normalize() а також завдяки відновленню полів за допомогою getElementsByTagName, метод, який є більш стабільним, ніж просте переглядання у текстовому редакторі, як показано цей технічний посібник із зчитування даних XML.
Ця послідовність має більше значення, ніж мова, яку ви обираєте. Якщо ви пропустите нормалізацію, якщо будете шукати вузли надто наївно або якщо припустите, що тег завжди зустрічається лише один раз, ваш скрипт працюватиме з деякими файлами, але дасть збій саме з тими, що мають значення.
Для проєктів, які згодом мають взаємодіяти із зовнішніми системами, може бути корисним створити відтворюваний та задокументований потік вилучення даних. Якщо ви працюєте над інтеграцією додатків, корисною основою стане документація щодо API ELECTE з перевіреним профілем Postman, особливо для того, щоб зрозуміти, як підключити вже очищений набір даних до подальших процесів.
Нижче наведено найпростіші приклади. Мета полягає не в тому, щоб охопити всі випадки, а в тому, щоб продемонструвати основну логіку: відкрити файл, знайти вузол, вивести значення.
import xml.etree.ElementTree as ETtree = ET.parse("fattura.xml")root = tree.getroot()numero = root.find(".//Numero")if numero is not None:print(numero.text)Python часто є найшвидшим вибором для створення прототипів, перетворень та легких конвеєрів. Він чудово підходить, коли потрібно прочитати багато XML-файлів, витягти з них кілька полів і зберегти їх у форматі CSV або JSON.
const xmlString = `<fattura><Numero>123</Numero></fattura>`;const parser = new DOMParser();const xmlDoc = parser.parseFromString(xmlString, "application/xml");const numero = xmlDoc.getElementsByTagName("Numero")[0];console.log(numero.textContent);Цей підхід корисний для швидкого тестування на сторінці або невеликих внутрішніх інструментів. Він підходить для легких інтерфейсів, але менш ефективний для структурованих робочих процесів бек-офісу.
const fs = require("fs");const xml2js = require("xml2js");const xml = fs.readFileSync("fattura.xml", "utf8");xml2js.parseString(xml, (err, result) => {if (err) throw err;console.log(result.fattura.Numero[0]);});Якщо ви працюєте на стороні сервера і хочете створювати автоматизовані процеси, Node.js залишається практичним вибором. Перевага полягає в тому, що можна легко інтегрувати обробку XML-файлів із файловою системою, чергами обробки та внутрішніми сервісами.
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();DocumentBuilder builder = factory.newDocumentBuilder();Document doc = builder.parse("fattura.xml");doc.getDocumentElement().normalize();NodeList lista = doc.getElementsByTagName("Numero");if (lista.getLength() > 0) {System.out.println(lista.item(0).getTextContent());}Java часто використовується в корпоративних системах, системах управління та проміжному програмному забезпеченні. У цьому випадку головне — не просто зчитати дані, а зробити це передбачуваним і зручним для обслуговування способом.
library(XML)doc <- xmlParse("fattura.xml")numero <- xpathSApply(doc, "//Numero", xmlValue)print(numero)Використання R має сенс, коли синтаксичний аналіз є частиною аналітичної роботи. Якщо вашим наступним кроком є статистичний аналіз або підготовка даних, ви можете виконувати все в одному середовищі.
Якщо ваша команда щотижня відкриває одні й ті самі файли та повторює одні й ті самі перевірки, ви вже перебуваєте у сфері автоматизації.
Справжня вигода полягає не в тому, щоб «читати XML за допомогою коду». Вона полягає в тому, щоб позбавити людей механічної роботи та створити процес, який генерує цілісні набори даних.
Серйозні проблеми починаються тоді, коли файлів стає більше одного. З одним файлом FatturaPA майже завжди можна впоратися. Складність виникає, коли доводиться об’єднувати документи за кілька місяців, від різних постачальників, з неоднаково заповненими полями та вбудованими вкладеннями.
В італійських МСП найпоширенішим випадком є не окремий «мегафайл», а партія даних. Щорічний експорт вхідних рахунків-фактур може утворити структуру з понад 380 000 вузлів у 4 200 рахунках-фактурах, включаючи заголовки, рядки з деталями, платіжні дані та вкладення у форматі base64. У таких випадках проблема полягає не в тому, щоб відкрити документ, а в тому, щоб перетворити неоднорідні XML-файли на узгоджений набір даних.
Тут на перший план виходить технічний вибір, що має вплив на бізнес. У середовищі .NET компанія Microsoft зазначає, що XmlDocument завантажує документ у пам’ять і є корисним для читання та редагування, тоді як для великих файлів або операцій, що передбачають лише читання, доцільніше використовувати більш ефективні підходи, такі як потоковий парсер або XPathDocument, щоб уникнути надмірного споживання оперативної пам’яті, як зазначено в документації Microsoft щодо читання XML за допомогою XmlDocument та XPathDocument.
На практиці:
Компроміс простий. Модель у пам’яті дозволяє розробляти швидше. Модель потокової передачі краще працює у виробничому середовищі, коли файлів стає багато або вони стають великими.
Багато команд обмежуються перевіркою XSD. Це корисно, але цього недостатньо. Файл може відповідати схемі, але все одно генерувати некоректні дані на наступних етапах обробки.
Типові приклади з оперативної роботи:
| Тип контролю | Що перевіряється | Навіщо це потрібно |
|---|---|---|
| Структурний | Теги, формат, ієрархія | Уникайте помилок синтаксичного аналізу |
| Семантичний | Логічна узгодженість даних | Уникайте помилкових висновків |
| Введено в експлуатацію | Наявність полів, необхідних для складання звітності | Уникайте непридатних наборів даних |
Найпідступніший випадок — такий: «ImportoTotaleDocumento» формально є правильним, але не збігається з сумою рядків, можливо, через особливості округлення в системі управління постачальника. Або коди ПДВ формально допустимі, але не відповідають характеру операції.
Навіть формально правильний файл може все одно спотворити вашу звітність.
Крім того, у FatturaPA існує ще одна відома пастка. Тег «DatiBeniServizi» містить довільні описи. Одна й та сама вартість може бути представлена по-різному — у вигляді чітких, скорочених або загадкових формулювань. Якщо не запровадити етап нормалізації, будь-який аналіз за категоріями витрат стане ненадійним.
Саме тому в серйозних потоках даних читання файлу — це лише перший рівень. Другий рівень — це завжди набір правил щодо узгодженості та чистоти даних. Саме там забезпечується якість даних, а не в парсері.
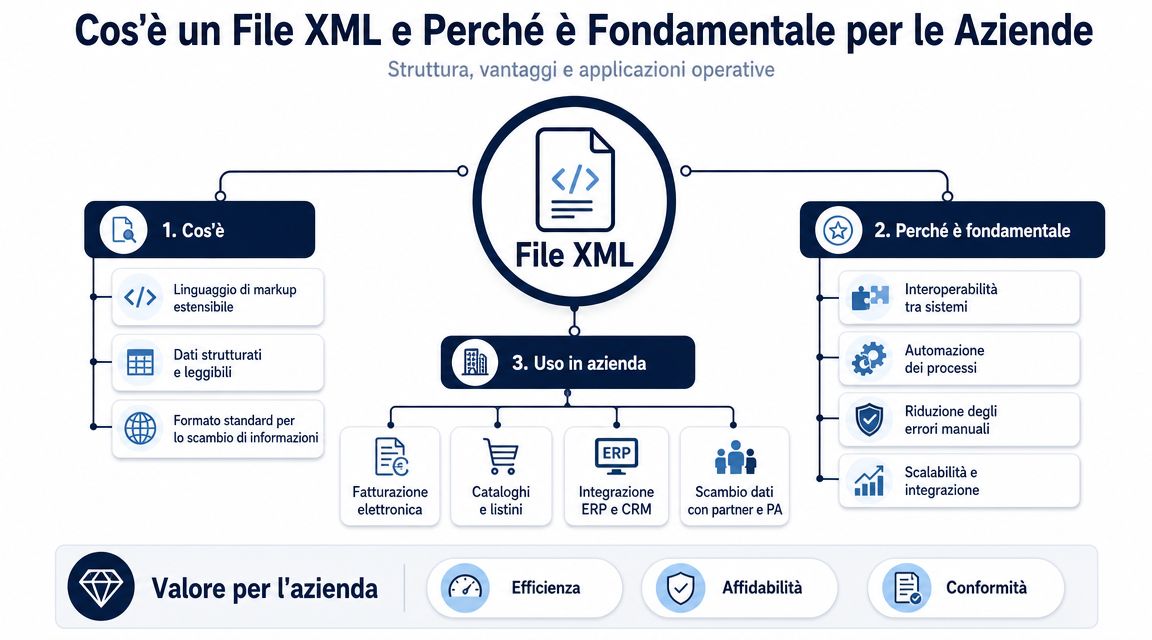
Навіть правильно прочитаний XML-файл ще не є корисним набором даних. Це структурований документ. Щоб проводити аналіз, порівняння, групування та створювати інформаційні панелі, майже завжди доводиться перетворювати його у формат, з яким легше працювати.
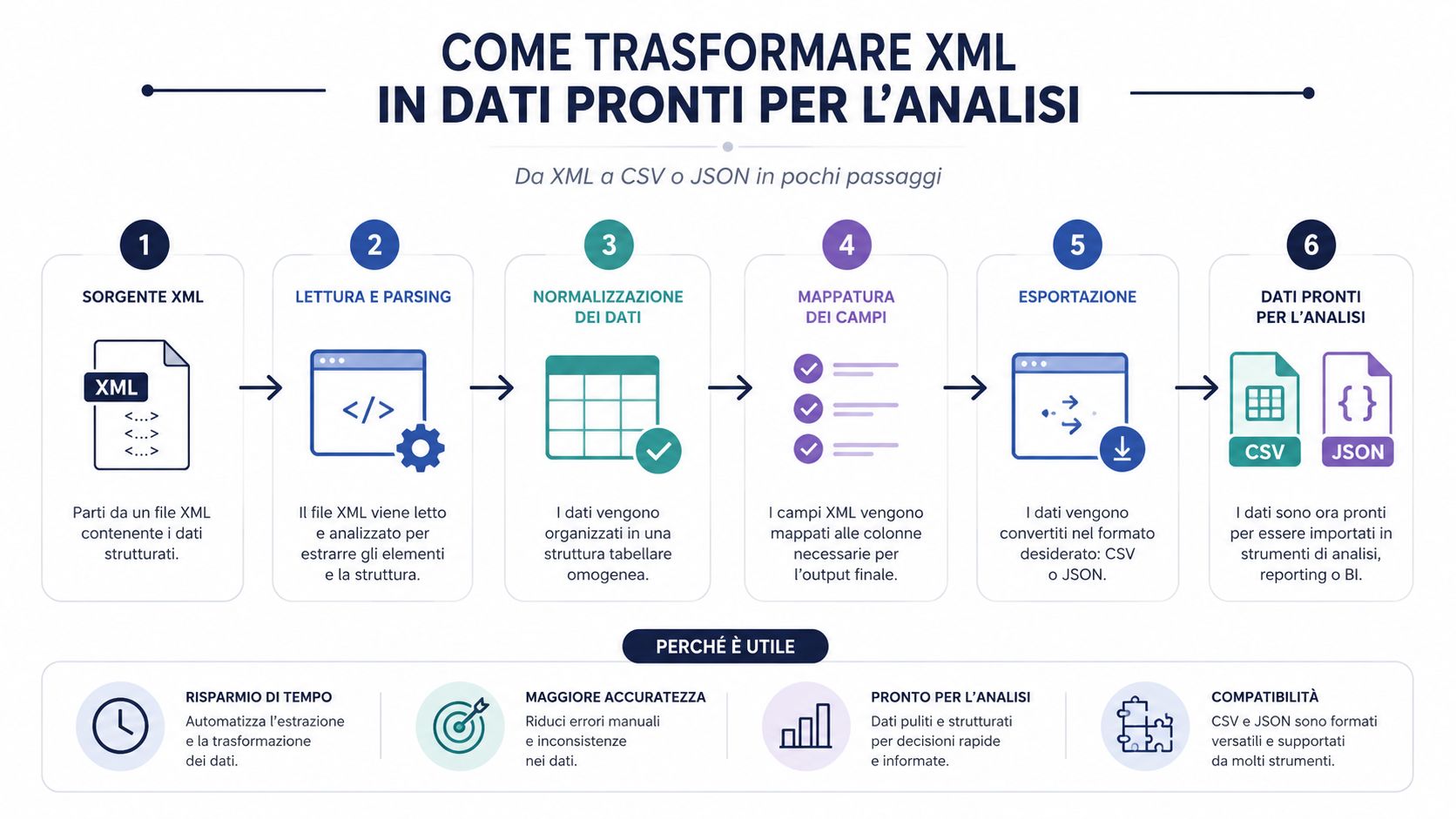
Саме цей момент часто недооцінюють у багатьох процесах. «Вузьким місцем» рідко є сам синтаксичний аналіз. Хороша бібліотека швидко зчитує XML. Час витрачається на інтерпретацію структури, вилучення потрібних полів, очищення, нормалізацію та завантаження даних у аналітичний інструмент.
Саме тому перетворення у формат CSV або JSON — це не просто зручність. Це ключовий етап роботи. Якщо пропустити цей етап і працювати безпосередньо з необробленим файлом, то майже завжди доводиться вдаватися до ручної перевірки, імпровізованих стовпців та логіки, яку важко відтворити.
Корисний посібник для тих, хто часто працює з XML та електронними таблицями, — це інструкція про те, як найбільш впорядковано переносити дані з XML до Excel.
Правильний формат залежить від того, як ви будете використовувати дані надалі.
CSV добре підходить, коли потрібно один рядок на документ або один рядок на деталі рахунку-фактури, а потім використовувати Excel, Power Query або BI.
Приклад на Python:
import xml.etree.ElementTree as ETimport csvtree = ET.parse("fattura.xml")root = tree.getroot()with open("fatture.csv", "w", newline="", encoding="utf-8") as f:writer = csv.writer(f)writer.writerow(["номер", "дата"])номер = root.findtext(".//Numero")data = root.findtext(".//Data")writer.writerow([numero, data])Перевага полягає в простоті. Недолік полягає в тому, що потрібно ретельно продумати, як спростити ієрархію. Якщо рахунок-фактура містить кілька детальних рядків, необхідно чітко визначитися з рівнем деталізації та ключем зв’язку.
JSON краще підходить, коли потрібно зберегти частину ієрархічної структури.
Приклад на JavaScript:
const record = {numero: "123",data: "2024-01-15",righe: [{ descrizione: "Servizio", importo: "100.00" }]};console.log(JSON.stringify(record, null, 2));Використовуйте його, коли вашим наступним кроком є API, «озеро даних» або додаток, який добре працює з вкладеними об’єктами.
Ось практичне правило, яке допоможе:
Файл XML — це контейнер. CSV і JSON — це формати, які роблять вміст справді придатним для обробки.
Якщо ви хочете скоротити час отримання висновків, саме в це варто вкласти зусилля. Не в пошук зручнішого засобу візуалізації, а в розробку стабільної та повторюваної трансформації.
Після того як файл прочитано, перевірено та оброблено, характер роботи змінюється. Ви вже не боретеся з тегами. Ви нарешті аналізуєте витрати, відхилення, постачальників, категорії витрат та операційні тенденції.
У реальній роботі цінність полягає не в часі, необхідному для синтаксичного аналізу. Вона полягає в часі, який проходить від отримання необробленого файлу до отримання інформації, на основі якої можна прийняти рішення. При ручному процесі людина повинна відкрити документ, розібратися в його структурі, виокремити поля, очистити значення, нормалізувати тексти, а потім скласти звіт. Це вразливий процес.
Класичним прикладом у системі FatturaPA є вільний текст у полі «DatiBeniServizi». Одна й та сама послуга може описуватися різними постачальниками по-різному. Якщо імпортувати ці дані без узгодженого зіставлення, аналіз за категоріями витрат призведе до утворення непотрібних агрегатів.
Тому перед тим, як перейти до аналітичної платформи, необхідний етап підготовки даних:
Якщо цей етап виконано правильно, будь-яка аналітична платформа працюватиме ефективніше. Якщо ви хочете глибше ознайомитися з аспектами прийняття рішень та візуалізації на цьому етапі, корисним буде матеріал про те, як створювати історії на основі даних, оскільки він демонструє, як упорядкований набір даних перетворюється на корисну розповідь для осіб, що приймають рішення.
На цьому етапі XML-файл перестає бути технічною проблемою і стає сировиною для отримання аналітичних висновків. Добре підготовлений набір даних може слугувати основою для аналізу витрат, відстеження тенденцій, виявлення відхилень та аналізу винятків.
Щоб вибрати платформу, яка підійде для цього «останнього етапу», вам може допомогти порівняння можливостей сучасного програмного забезпечення для бізнес-аналітики з суто ручними процесами, що базуються на таблицях та зведених таблицях.
Тут правильним критерієм не є питання «чи вміє він відкривати XML?». Це — мінімум. Корисне питання інше:
| Питання | Чому це важливо |
|---|---|
| Дані надходять уже в очищеному вигляді | Уникайте точних висновків на основі неправильних даних |
| Категорії є узгодженими | Ви дійсно порівнюєте постачальників і періоди? |
| Аномалії виявляються відразу | Скоротіть час, що витрачається на ручні перевірки |
| Звіт зрозумілий для фахівців у сфері бізнесу та фінансів | Прискорюйте прийняття рішень |
Різниця між незрілим і зрілим процесом полягає не в здатності читати XML-файли. Вона полягає в здатності перетворювати їх на надійну базу даних, яка не змушує команду щоразу повторювати одну й ту саму роботу.
Якщо вам потрібно читати XML-файли так, щоб це було корисно для бізнесу, майте на увазі цей контрольний список. Він є більш конкретним, ніж будь-яке технічне визначення, і допоможе вам обрати правильний метод, не витрачаючи час даремно.
Не варто завжди використовувати один і той самий підхід. Браузери, редактори та програми перегляду підходять для швидкої перевірки. Парсери та скрипти потрібні, коли файл має використовуватися в повторюваних процесах. Якщо ви плутаєте перегляд даних з їх обробкою, ви ризикуєте створювати звіти на нестійкій основі.
Файли .xml.p7m вимагають виконання певного етапу обробки підпису. Якщо вміст надходить з PEC, ця перевірка не є додатковою. Вона є частиною правильного зчитування документа.
Дотримання схеми не гарантує цілісності набору даних. Логічні невідповідності, такі як невідповідності підсумків або неоднозначні податкові класифікації, найчастіше псують аналіз. Саме семантична перевірка відрізняє «прийнятний» файл від надійних даних.
CSV та JSON — це не просто косметична зміна. Саме завдяки їм XML стає придатним для обробки аналітичними інструментами, електронними таблицями, конвеєрами даних та звітами. Чим раніше ви визначите це перетворення, тим швидше зменшите обсяг ручної роботи та імпровізації.
Ваша мета — не читати XML-файли. Ваша мета — отримати корисну інформацію, не забруднюючи систему неякісними даними. Якщо потік даних не забезпечує цілісного набору даних, проблема лежить не в кінцевій інформаційній панелі. Вона лежить набагато вище за ланцюгом.
На практиці ти можеш скористатися цим міні-переліком перед початком кожного нового проєкту:
Якщо ви хочете перетворити вже підготовлені дані на чіткі та практичні висновки, ELECTE допомагає малим та середнім підприємствам перейти від очищеного набору даних до інтелектуальної звітності, використовуючи підхід, доступний навіть для нетехнічних команд. Це найшвидший спосіб скоротити відстань між оперативними даними та процесом прийняття рішень.

.svg)
.svg)
.svg)
.webp)





