

Ваші дані вже розповідають історію. Проблема в тому, що часто вони говорять занадто тихо.
Щодня мале та середнє підприємство накопичує відгуки клієнтів, замовлення, запити до служби підтримки, фінансові операції, ділові листи та записи в CRM. Усі ці дані містять корисні сигнали. Деякі вказують на те, що клієнт може відмовитися від послуг. Інші попереджають про операційний ризик. А ще інші показують, які продукти незабаром наберуть обертів або втратять популярність. Однак без чіткого методу ці сигнали залишаються лише шумом.
Серед алгоритмів, які допомагають навести лад у цьому хаосі, особливе місце посідають наївні байєсівські класифікатори. Їхня логіка проста для розуміння, вони швидко навчаються і часто виявляються ефективнішими, ніж можна було б припустити, зважаючи на назву «наївні». Вони не підходять для всіх ситуацій, але в багатьох реальних бізнес-завданнях забезпечують рідкісний баланс між швидкістю, інтерпретованістю та корисними результатами.
Якщо ви працюєте у сфері бізнесу, вам не потрібно ставати науковцем, щоб їх зрозуміти. Вам потрібно знати, як вони працюють, чому вони ефективні навіть тоді, коли значно спрощують реальність, і в яких випадках вони можуть допомогти вам приймати кращі рішення. Саме на цьому варто зупинитися.
Багато компаній шукають складні моделі, хоча проблема вимагає, насамперед, надійної та простої у використанні моделі. З тієї ж причини у фінансах, роздрібній торгівлі чи сфері обслуговування клієнтів часто перемагає не найвитонченіший з теоретичної точки зору процес, а найпростіший.
Наївні байєсівські класифікатори ґрунтуються на дуже конкретній ідеї. Якщо ви маєте певні підказки щодо нового випадку, ви можете з високою ймовірністю визначити, до якої категорії він належить. Якщо електронний лист містить певні слова, це може бути спам. Якщо транзакція має певні ознаки, її, можливо, слід перевірити. Якщо у відгуку вживаються певні терміни, це може свідчити про задоволеність або незадоволеність.
Слово «байєсівський» асоціюється зі складними формулами. Насправді суть цього методу інтуїтивно зрозуміла. Ви берете те, що вже знаєте, додаєте нові факти та коригуєте свою думку. Це впорядкований спосіб міркування в умовах невизначеності — саме те, що менеджери роблять щодня, тільки систематизовано за допомогою алгоритму.
Дивно, що цей підхід і досі добре працює навіть у сучасних умовах, де ми маємо величезні обсяги даних і мусимо швидко приймати рішення. Не тому, що він ідеально описує світ, а тому, що він відокремлює корисний сигнал від шуму з дуже низькими обчислювальними витратами.
У бізнес-питаннях правильне запитання звучить не так: «Яка модель є найдосконалішою?», а так: «Яка модель дозволяє приймати надійні рішення у терміни, що відповідають реальним робочим умовам?».
Саме тому наївні байєсівські класифікатори залишаються важливими. Вони допомагають класифікувати, фільтрувати, сегментувати та визначати пріоритети. А також дозволяють врахувати ймовірність у процесі прийняття рішень, не перетворюючи кожен проєкт на технічний майданчик.
Основним принципом є теорема Байєса. У спрощеному вигляді вона звучить так: виходите з початкової ймовірності, а потім коригуєте її, коли з’являється нова інформація.
У мові даних ця формула записується так: P(y|x) ∝ P(y) ⋅ ∏ P(x_i|y). Це означає, що ймовірність належності до певного класу за заданого набору сигналів залежить від двох факторів. Перший — це початкова ймовірність належності до цього класу. Другий — це ступінь відповідності кожного сигналу цьому класу.
Перекладемо це на приклад із бізнесу. Вам потрібно визначити, чи є електронний лист спамом. У вас є загальна ймовірність того, що отриманий лист є спамом. Потім ви звертаєте увагу на такі слова, як «пропозиція», «безкоштовно», «натисніть тут». Кожне з цих слів впливає на остаточне рішення.
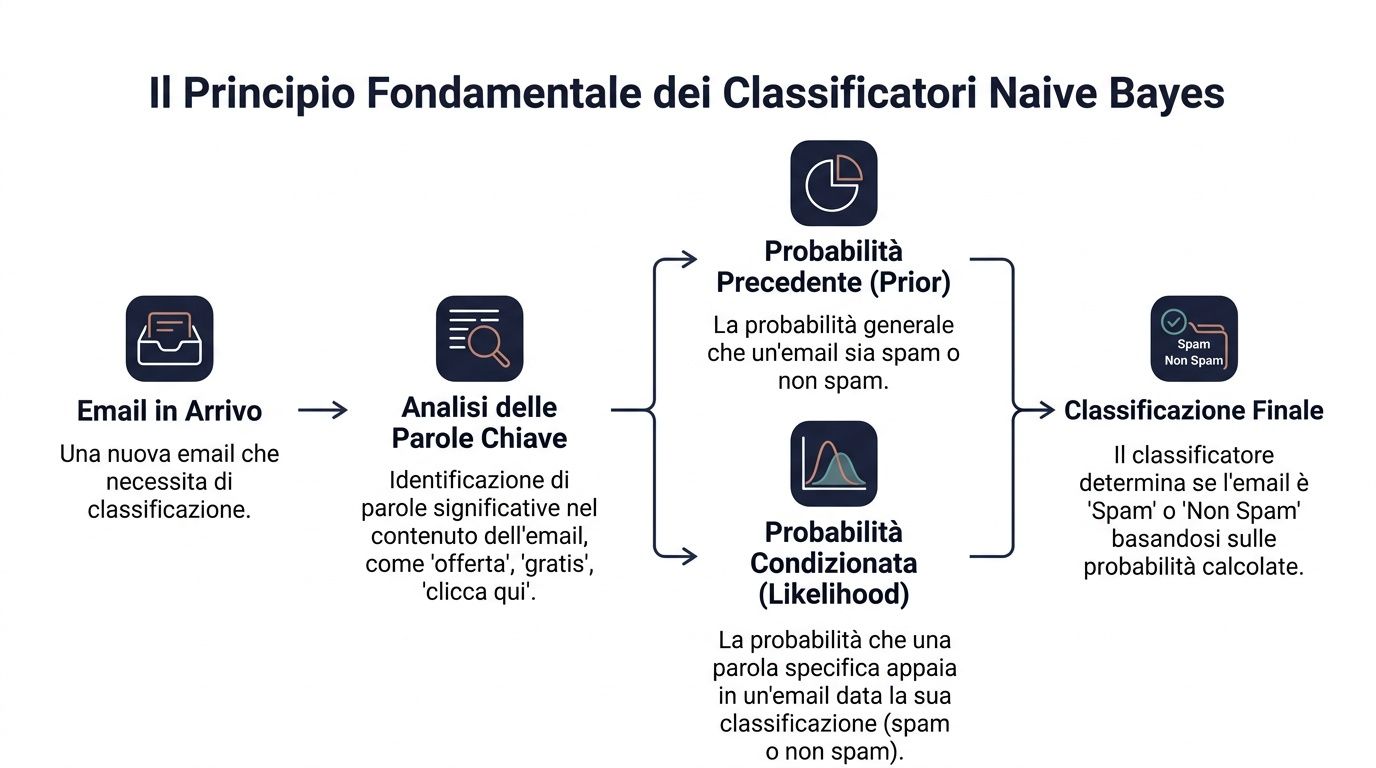
Менеджер робить щось подібне щодня. Він ніколи не приймає рішень у вакуумі. Він виходить із базового контексту та додає до нього нові підказки. Клієнт, який завжди регулярно робив покупки, має певний початковий профіль. Якщо ж він перестає відкривати електронні листи, зменшує суму замовлень і відкриває критичний запит, ваша оцінка змінюється.
Термін «наївний» вказує на конкретне припущення. Модель розглядає ознаки так, ніби вони є незалежними одна від одної, оскільки клас відомий.
На практиці, якщо ви класифікуєте електронний лист, розглядайте кожне слово як окрему підказку. Не намагайтеся моделювати всі складні взаємозв’язки між термінами. Це значне спрощення. Насправді багато слів зустрічаються разом, а багато аспектів ділової поведінки взаємопов’язані.
Проте саме цей підхід робить модель дуже легкою. Їй не потрібно вивчати складну мережу взаємозалежностей. Вона має оцінювати простіші ймовірності та ефективно їх поєднувати.
Практичне правило: алгоритм Naive Bayes не намагається відтворити весь світ. Він прагне приймати корисні рішення, спираючись на мінімум припущень і працюючи з високою швидкістю.
Саме тут часто виникає непорозуміння. Багато хто, прочитавши «наївне припущення», робить висновок про «слабку модель». Це не так. Модель може значно спрощувати і водночас залишатися конкурентоспроможною, якщо це спрощення враховує те, що має значення для прийняття рішення.
У 2004 році теоретичний аналіз продемонстрував вагомі підстави для ефективності класифікаторів Naive Bayes, незважаючи на припущення про незалежність, а також пояснив, чому вони можуть досягати асимптотичної похибки швидше, ніж логістична регресія. У цій же галузі застосування, зокрема у фільтруванні спаму, вони досягають точності понад 99 % і масштабуються на мільйони документів, як зазначено у статті, присвяченій класифікаторам Naive Bayes.
Цей момент є важливим для бізнес-аудиторії. Цінність алгоритму полягає не лише в кінцевому результаті. Вона полягає також у здатності швидко навчатися, адаптуватися до великих наборів даних і залишатися зрозумілим.
Коли у вас є розрізнені тексти, категорії, теги або сигнали, наївні байєсівські класифікатори працюють добре, оскільки:
Однак слід пам’ятати про дві речі.
Саме тому алгоритм Naive Bayes слід розглядати як дуже ефективний інструмент для швидкої класифікації, а не як універсальне чарівне рішення. Проте в багатьох практичних ситуаціях це один із найрозумніших способів розпочати роботу.
Поширеною помилкою є розмова про алгоритм Naive Bayes так, ніби це єдина модель, однакова для будь-якої ситуації. Насправді існують різні варіанти, призначені для різних типів даних.
Правильний вибір залежить від того, у якому вигляді представлені ваші дані. Якщо ви оберете неправильний варіант, модель все одно зможе згенерувати прогноз, але її підхід не буде оптимальним для вашої задачі.
Гaussian Naive Bayes — це найбільш підходящий варіант, коли ознаки є безперервними. Наприклад, середня сума транзакції, вік клієнта, середній проміжок часу між двома покупками, одинична маржа або вартість чека.
У цій моделі передбачається, що всередині кожного класу значення мають гаусівський розподіл. Не варто сприймати це як суто теоретичне обмеження. Достатньо запам’ятати суть: для кожного класу модель оцінює типовий центр і розкид.
Цей підхід корисний, коли потрібно класифікувати такі випадки, як:
У тесті scikit-learn із набором даних, схожим на італійські дані електронної комерції, модель Naive Bayes досягла 95% точності на 1000 зразках, при цьому час навчання був на 15% кращим, ніж у логістичної регресії . Показане порівняння становить 0,01 с проти 0,1 с на стандартному процесорі завдяки навчанню в закритій формі, як показано в розділі Джейка ВандерПласа «In Depth Naive Bayes Classification».
Для компанії головне — не десяткова крапка. Головне в тому, що цей варіант може дати хороші результати без тривалого навчання та без потужної інфраструктури.
Якщо ви працюєте з текстами, квитками, відгуками чи коментарями, модель «Multinomial Naive Bayes» часто є очевидним вибором. У цьому випадку ознаками є підрахунки або частоти. Фактично модель аналізує, скільки разів з’являються слова чи терміни.
Це класичний приклад:
Причина, чому це добре працює, є цілком конкретною. У ділових текстах лексичний запас може бути широким, але кожен документ містить лише невелику частину можливих слів. Дані є розрізненими. Алгоритм Multinomial Naive Bayes добре справляється саме з таким типом структури.
У дослідженні, в якому було проаналізовано 100 000 італійських твітів, позначених за емоційним забарвленням, модель «Multinomial Naive Bayes» продемонструвала показник F1-score на рівні 0,88 та 10-кратне прискорення порівняно з SVM, як зазначено в посібнику GeeksforGeeks щодо класифікаторів Naive Bayes.
Щоб це легко запам’ятати, подумай так: якщо твої дані схожі на документ, у якому підраховано кількість слів, багаточлен майже завжди є першим варіантом, який варто перевірити.
Якщо вашій компанії доводиться обробляти великі обсяги тексту, питання полягає не лише в тому, «наскільки точна модель?». Воно також полягає в тому, «скільки запитів вона здатна класифікувати, не сповільнюючи роботу команди?».
Альгоритм Бернуллі-Наївного Байєса працює з бінарними ознаками. Він не враховує, скільки разів з’являється певний сигнал. Він враховує лише те, чи присутній він, чи відсутній.
Цей варіант є корисним, коли наявність атрибута має більшу вагу, ніж його частота. Деякі приклади з ділової практики:
Ця логіка дуже корисна, коли потрібно перетворити складні явища на прості показники типу «так/ні», за якими легко стежити. Наприклад, в аналізі настроїв важливішим може бути сам факт появи негативного слова, а не те, скільки разів воно повторюється.
Розподіл Бернуллі не є «менш досконалим», ніж мультиноміальний. Він просто краще підходить у випадках, коли дані описують наявність або відсутність. На словах різниця незначна, але в результатах вона є суттєвою.
| Варіант | Ідеальний тип даних | Приклад корпоративного сценарію використання |
|---|---|---|
| Гаусівський метод наївного Байєса | Поточні дані | Класифікувати операції за рівнем ризику з урахуванням сум, частоти та середніх значень |
| Багаточленний метод наївного Байєса | Тексти, підрахунки, частоти | Аналізувати відгуки та звернення клієнтів за настроєм або категорією |
| Бернуллі, метод наївного Байєса | Бінарні дані, наявність/відсутність | Оцінювати сигнали «так/ні» щодо дотримання вимог, підтримки або використання продукту |
Щоб зробити правильний вибір, скористайтеся простим правилом:
Багато команд заходять у глухий кут, бо намагаються знайти «найкращу» модель. Правильний вибір майже завжди полягає у виборі моделі, яка найбільше відповідає типу даних.
Хороша новина полягає в тому, що для практичного застосування алгоритму Naive Bayes не потрібно реалізовувати грандіозний проект. Навіть простий прототип уже дозволяє зрозуміти, як працює модель і які дані їй потрібні.

Створення класифікатора майже завжди відбувається у чотири етапи.
Підготовка даних
Вам потрібно зібрати історичні зразки, які вже мають мітки. Якщо ви класифікуєте відгуки, вам потрібні тексти, які вже позначені як позитивні або негативні. Якщо ви аналізуєте операційний ризик, вам потрібні минулі випадки з відомим результатом.
Навчання моделі «
» Модель аналізує дані та обчислює відповідні ймовірності. У «naive bayesian» класифікаторах цей етап відбувається швидко, оскільки навчання не вимагає особливо ресурсомістких оптимізацій.
Прогноз щодо нових випадків
Введіть нові записи, і модель присвоїть їм клас. Наприклад, «спам», «не спам», «клієнт із ризиком», «стабільний клієнт».
Оцінка
Порівняйте прогнози з реальними даними на окремому тестовому наборі. Тут ви не просто перевіряєте, чи працює модель. Ви дивитеся, як вона помиляється.
Якщо ви хочете глибше ознайомитися із загальною картиною прогнозних підходів, цей огляд алгоритмів машинного навчання допоможе вам зрозуміти, як алгоритм Наївного Байєса вписується в ширше сімейство методів.
Щоб наочно проілюструвати цей процес, ось простий приклад із використанням scikit-learn. Не обов’язково читати його як розробник. Достатньо зрозуміти загальний алгоритм.
# Імпортуємо основні інструментиfrom sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_splitfrom sklearn.naive_bayes import GaussianNBfrom sklearn.metrics import accuracy_score# Завантажуємо приклад набору данихX, y = load_iris(return_X_y=True)# Розділимо дані на частину для навчання та частину для тестування X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# Створюємо модельmodel = GaussianNB()# Навчаємо модель на історичних данихmodel.fit(X_train, y_train)# Робимо прогнози щодо даних, яких раніше не бачилиy_pred = model.predict(X_test)# Вимірюємо точністьprint(accuracy_score(y_test, y_pred))Цей уривок говорить набагато більше, ніж здається на перший погляд.
GaussianNB() виберіть варіант для безперервних даних.fit() це момент, коли модель навчається.predict() застосовує те, чого навчився.accuracy_score() перевірте, скільки класифікацій загалом є правильними.Що стосується текстових даних, алгоритм залишається схожим, але перед застосуванням моделі текст потрібно перетворити на числа. Фактично, ви перетворюєте слова на ознаки, які може використовувати класифікатор.
Після першого ознайомлення з кодом може бути корисно ознайомитися з наочним поясненням цього механізму.
Перша модель не призначена для того, щоб продемонструвати досконалість. Вона призначена для того, щоб відповісти на три практичні запитання.
Тут видно переваги методу Naive Bayes. Ви можете швидко отримати надійну базову модель. На її основі ви зрозумієте, чи є сенс ускладнювати проект, чи просте рішення вже приносить користь.
Модель класифікації не оцінюють лише за тим, що вона «здається ефективною». Її оцінюють за тим, як вона помиляється, і за тим, наскільки ці помилки впливають на бізнес.

Точність — це найбільш інтуїтивний показник. Він показує, скільки прогнозів із загальної кількості виявилися правильними. Це корисно, але сам по собі цей показник може ввести в оману.
Якщо зі ста транзакцій лише кілька є справді підозрілими, модель, яка класифікує майже все як нормальне, може здаватися точною, але виявлятися неефективною саме там, де це дійсно потрібно.
Щоб це зрозуміти, уявіть собі рибальську сітку.
У бізнесі це розрізнення має велике значення.
Хороша модель — це не та, яка загалом рідко помиляється. Це та, яка робить помилки найменш витратним для вашого процесу способом.
Щоб краще зрозуміти, як алгоритм навчається на історичних даних і чому якість навчання впливає на кінцевий результат, ви можете прочитати цю докладну статтю про те, у чому полягає навчання алгоритму.
Метод Naive Bayes є простим, але не пробачає деяких практичних помилок.
Перша помилка: ігнорування проблеми нульової частоти.
Якщо слово чи значення ніколи не зустрічається в навчальних даних для певного класу, ймовірність може впасти до нуля, що може зіпсувати розрахунок. Тому часто використовують згладжування Лапласа, яке додає невелике коригування до підрахунків.
Друга помилка: використання сильно корельованих ознак.
Якщо два стовпці містять майже однакову інформацію, модель може переоцінити сигнал. Вона не «розуміє», що ці дві ознаки майже дублюють одна одну.
Третя помилка: надмірна довіра до необроблених ймовірностей.
Алгоритм Naive Bayes часто забезпечує точне класифікування, але його ймовірності можуть бути занадто категоричними. Для бізнесу це означає, що рейтинг може бути корисним, тоді як точне значення ймовірності слід трактувати з обережністю.
Щоб зменшити ці ризики, варто:
Справжня цінність наївних байєсівських класифікаторів стає очевидною, коли ви перестаєте розглядати їх як математичне завдання і починаєте використовувати їх як інструмент для визначення пріоритетів. У бізнесі правильна класифікація майже завжди означає прийняття кращих рішень.

Уявіть собі фінансову команду, яка аналізує потоки транзакцій, описи операцій та історичні дані. Кожен рядок — це не просто запис. Це потенційне рішення: пропустити, перевірити детальніше, заблокувати або передати аналітику.
За допомогою алгоритму Naive Bayes ви можете об’єднати різні індикатори в єдину класифікацію. Деякі з них є числовими, інші — бінарними, а ще інші — текстовими. Модель допомагає зрозуміти, які випадки найбільше схожі на вже відомі шаблони, що вважаються нормальними або аномальними.
Практична користь полягає у двох аспектах:
Це не замінює людського судження в регульованих ситуаціях. Це допомагає його систематизувати. А в операційних процесах з великим обсягом роботи це має реальне значення.
У маркетингу класифікація часто означає розподіл кожного клієнта за оперативними групами. Лояльні. Ціночутливі. З високим ризиком відтоку. Реагують на акції. Неактивні.
У цьому випадку алгоритм Naive Bayes є корисним, оскільки дозволяє швидко об’єднувати різнорідні сигнали:
Команді CRM не потрібна досконала теорія людської поведінки. Їй потрібна сегментація, достатньо якісна, щоб давати змогу вживати обґрунтованих заходів. Наприклад, змінювати повідомлення, частоту контактів або тип пропозиції.
Коли модель допомагає обрати наступне повідомлення для потрібного клієнта, вона вже створює операційну цінність.
У роздрібній торгівлі та електронній комерції класифікація допомагає виконувати завдання, які на перший погляд здаються різними, але базуються на одній логіці: впорядкувати хаос.
Ви можете класифікувати товари за їхніми показниками продажів. Ви можете переглянути відгуки та запити, щоб зрозуміти, які категорії викликають труднощі. Ви можете виявити закономірності попиту, які допоможуть команді чіткіше планувати акції та запаси.
У таких умовах дані зазвичай є об’ємними, неоднорідними та не завжди досконалими. Саме тому швидка, масштабована та зрозуміла модель має велику цінність. Не тому, що вона найпривабливіша, а тому, що вона інтегрується в робочий процес, не сповільнюючи його.
Якщо ви хочете побачити, як аналітичні підходи, застосовані до бізнесу, втілюються в конкретних проєктах, ви можете ознайомитися з цими прикладами з практики.
Розуміти алгоритм Naive Bayes — це корисно. А от правильно впровадити його в бізнес-середовищі — це вже інша справа.
Проблема майже ніколи не полягає лише в алгоритмі. Справжня робота полягає в розробці моделі. Потрібно об’єднати різні джерела даних, обробити пропущені поля, підготувати тексти, оновити мітки, перевірити якість вихідних даних та представити результати у зрозумілій для керівництва формі.
Для малого та середнього бізнесу цей етап часто є найскладнішим. Не тому, що їм бракує інтересу до штучного інтелекту, а тому, що час команди обмежений, а операційні пріоритети не терплять зволікань.
У цьому випадку доцільно використовувати платформу, яка бере на себе технічні складнощі. Рішення на базі штучного інтелекту дозволяє перетворювати необроблені дані на зрозумілу інформацію, не вимагаючи від бізнесу написання коду, вибору бібліотек або обслуговування ручних конвеєрів.
Така платформа , як ELECTE — платформа для аналізу даних на базі штучного інтелекту, призначена для малих та середніх підприємств, — робить доступними такі методи, як наївні байєсівські класифікатори, не вимагаючи від користувачів спеціальних знань у галузі машинного навчання. Перевага полягає не лише у швидкості. Це зменшення перешкод між даними та прийняттям рішень.
Коли автоматизація працює належним чином, команда перестає мислити у термінах формул. Вона мислить у термінах корисних запитань:
Саме тому все більше компаній шукають інструменти, які допомагають оцінити надійність контенту, створеного штучним інтелектом, та текстових сигналів, що циркулюють у внутрішніх процесах. У цьому контексті може бути корисно ознайомитися з посібником щодо італійського детектора ШІ, особливо якщо ваша команда працює з документами, контентом та лінгвістичною перевіркою.
На практиці різниця полягає в простому: замість того, щоб займатися окремими технічними етапами, ви зосереджуєтеся на результатах бізнесу. І саме в цьому полягає суть: штучний інтелект стає не просто цікавим, а дійсно придатним для впровадження.
Наївні байєсівські класифікатори дають важливий урок. У аналітиці правильно застосована простота може виявитися ефективнішою за неправильно використану складність.
Завдяки інтуїтивно зрозумілій ймовірнісній основі, хорошій масштабованості та цілком конкретним сценаріям застосування цей підхід залишається надійним інструментом для компаній, які прагнуть класифікувати інформацію, розпізнавати приховані сигнали та діяти з більшою впевненістю. Не потрібно бути фахівцем з машинного навчання, щоб зрозуміти їхню цінність. Потрібно лише пов’язати математику з оперативним прийняттям рішень.
Коли цей зв’язок стає зрозумілим, штучний інтелект перестає бути суто технічним питанням і перетворюється на організаційну перевагу. Саме тоді прогнозування починає давати відчутні результати.
Якщо ви хочете перетворити розрізнені дані на чіткі висновки, спробуйте ELECTE. Ця платформа допомагає малим та середнім підприємствам об'єднувати джерела даних, автоматизувати аналіз та отримувати звіти й прогнози, корисні для прийняття швидких та обґрунтованих рішень.

.svg)
.svg)
.svg)






