

中小企业的财务团队对此深有体会:每当尝试将PDF导入Excel时,一场与格式格斗的战役便拉开了序幕。传统的复制粘贴操作几乎总是以灾难告终:数据散乱、单元格随意合并,原本井然有序的表格变得乱七八糟、难以辨认。这种挫败感确实存在,但这并非你的过错。 问题在于PDF格式的本质——它原本是为打印和分享而设计的,而非用于分析的数据源。
这种手动工作流程——涉及银行对账单、供应商发票和政府机构的文件——简直是生产力的黑洞。 它不仅枯燥乏味,更是数据录入错误的几乎必然来源。幸运的是,到了2026年,您将拥有更智能的方法来应对这一挑战。在本指南中,我们将逐步为您展示最有效的策略,从Excel内置功能到完全消除手动操作的AI驱动解决方案,助您在短短几分钟内从数据提取直接过渡到分析阶段。
这个问题源于一个根本性的区别:PDF文件的初衷是确保文档在任何设备上都能保持原有的外观,而非保留其内部数据的逻辑结构。了解不同类型PDF之间的区别,是选择合适工具并避免浪费数小时工作的第一步。
这张图片完美地捕捉到了那些不得不在一份复杂的PDF文件和一张杂乱无章的电子表格之间周旋的人所感受到的挫败感。

这正是手动操作开始阻碍工作效率的时刻,这也说明了我们需要一种更高效的方法来将PDF导入Excel。
也许你并不知道,但将PDF导入Excel最便捷的工具其实已经内置在你每天使用的软件中。它叫做Power Query,是微软在Excel中内置的一项强大的“数据获取和转换”功能。

这是导入简单且结构清晰的PDF文件(如价格表或联系人列表)的理想解决方案。它的最大优势是什么?它是免费的,且无需额外安装。
数据将被导入到一个新的工作表中,该工作表已按Excel表格格式进行排版,可直接使用。
Power Query 虽然很棒,但也有其局限性。它最适合处理单页内的简单表格。一旦遇到更复杂的场景,其性能就会大幅下降:
如果您经常进行数据分析,不妨了解一下与 Power BI 的集成,因为它采用了相同的技术。同样,掌握其他文件格式的处理方法也至关重要;我们关于如何在 Excel 中处理 CSV 文件的指南或许能为您提供一些有用的建议。
如果贵公司已拥有Adobe Acrobat Pro 许可证,其导出功能便是最可靠的解决方案之一。在保留复杂表格及非标准布局的格式方面,它往往比 Power Query 表现更佳。
操作很简单:打开 PDF 文件,进入“所有工具”,选择“导出 PDF”,将格式设置为“电子表格”,然后保存新的 Excel 文件。
结果通常都很整洁有序。不过,它有两个主要缺点:
像iLovePDF、Smallpdf或 开源工具Tabula这样的工具非常方便:只需将文件拖拽进去,点击一下按钮,即可下载转换结果。对于偶尔转换非敏感数据而言,它们是不错的选择。
然而,这种便利性背后隐藏着巨大的风险:数据安全。
将文件上传至第三方服务器,实际上意味着失去了对其的控制权。如果该PDF文件包含银行对账单、客户数据、机密价格表或任何战略信息,您将使公司面临潜在的隐私泄露风险以及违反《通用数据保护条例》(GDPR)的严重合规风险。
对于在欧洲运营的中小企业而言,这绝非小事。使用在线转换器来分析意大利国家统计局(Istat)发布的公开报告是可以接受的。但若将此方法用于处理本公司的财务数据,则是一项风险极高的举措,必须审慎评估。
如果您的团队需要处理每月以相同格式收到的数十份对账单、发票或报告,那么手动提取数据不仅令人头疼,更是运营中的瓶颈。
对于需要处理大量标准化文档的中小企业而言,通过Python脚本实现自动化并非奢侈之举,而是旨在提升效率的精准投资。诚然,这需要一定的技术能力,但在节省时间和减少错误方面,其投资回报率极高。

得益于诸如……等免费且功能强大的库,Python 在这一领域占据主导地位 pdfplumber 和 卡梅洛特,专门用于识别和重建PDF文件中嵌入的表格结构。
pdfplumber: 它功能极其强大,非常适合提取表格、文本和元数据,并能分析每个字符的位置。卡梅洛特: 该工具专用于表格数据提取,提供先进的算法来处理带有或不带可见分隔线的表格。实际场景:假设你在月底收到供应商发来的50张发票。与其耗费数小时占用资源,不如使用一个Python脚本来扫描这些发票,提取总金额和日期,并生成一份可供分析的Excel文件。整个过程不到一分钟,且完全消除了人为出错的风险。
数据经过提取和整理后,即可发送至分析平台。如需深入了解如何将这些数据整合到更广泛的数据流中,请 ELECTEAPI的运作原理,以便自动将数据发送至我们的平台。
当传统方法失效时,人工智能便派上了用场。ELECTE 这样的AI驱动平台ELECTE 塑行业规则,尤其在处理扫描文档或布局复杂的文档方面。
我们不再谈论那种仅能“读取”文本的传统OCR技术。现代解决方案将OCR与先进语言模型(LLM)相结合,从而能够理解数据的结构、上下文以及数据之间的关联。
试想一份财务报告,其中包含跨页的表格。一个基于人工智能的平台能够:
这彻底改变了局面。该AI平台不再只是提取原始数据,而是会“消化”PDF文件,并将其转化为一个经过清理、可直接用于分析的数据集。若想进一步了解,请参阅我们关于“企业最佳人工智能解决方案”的文章。
人工智能的真正价值不在于提取数据,而在于提取可直接使用的信息。您获得的不仅仅是一个简单的Excel文件,而是您的团队可以立即用于制定战略决策的数据,无需浪费时间进行数据清洗。
知道米兰在意大利进口市场中占据主导地位,这本身就是一项有趣的数据。但如果能自动导出关于各进口省份的完整报告,您的团队就能做更多事情:比较趋势、优化库存并降低成本。
面对如此多的选择,该如何挑选最适合自己的呢?答案取决于四个关键因素,这些因素将决定您操作的效率、安全性和成本。
此决策树可帮助您直观地了解决策过程的逻辑路径。
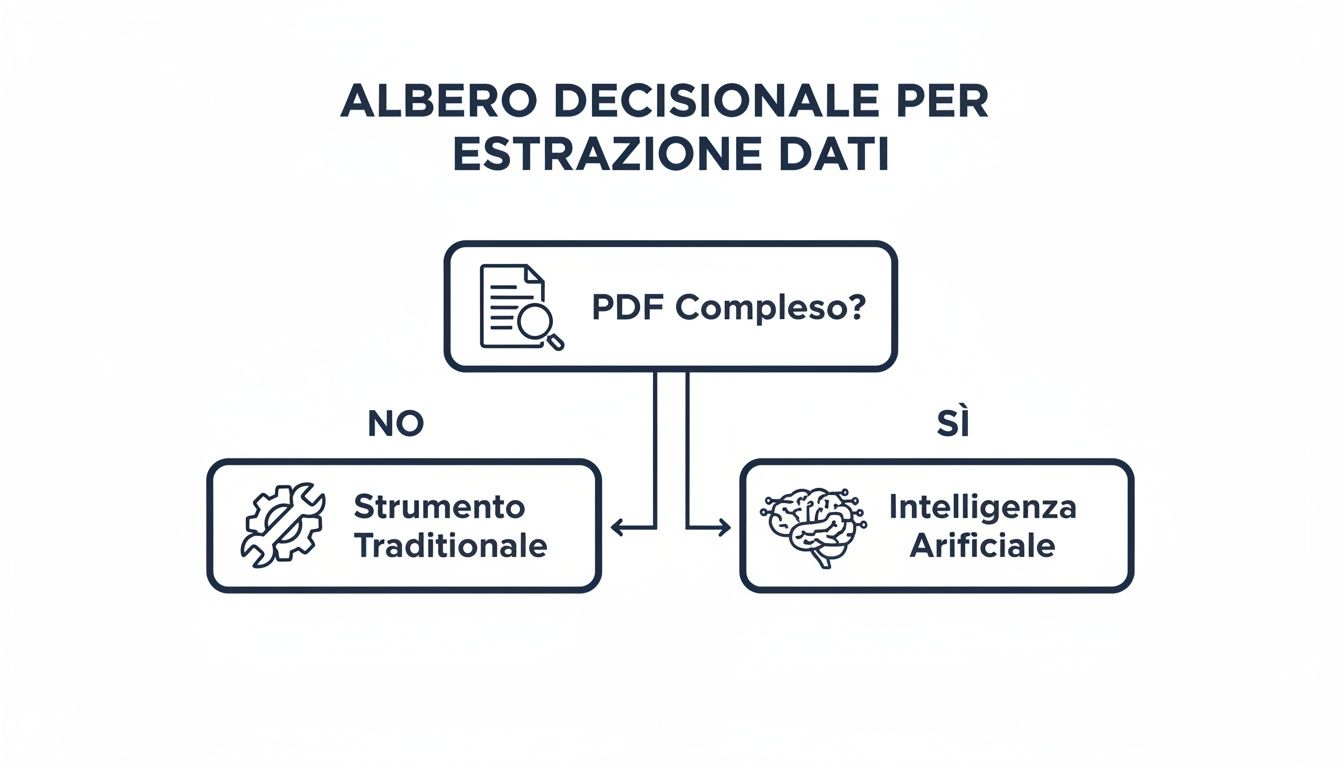
原理很简单:对于简单的PDF文件和偶尔的操作,Power Query等传统工具已绰绰有余。而对于海量数据、复杂文档和重复性ELECTE 人工智能驱动ELECTE 繁琐的任务转化为能创造价值的自动化流程。
将PDF导入Excel不再需要通过繁琐的手动操作。如今,您拥有丰富的工具可供选择,从Power Query这类免费的内置工具,到先进的自动化解决方案和基于人工智能的平台,应有尽有。
选择取决于您的具体需求:对于简单文件的偶尔操作,Power Query 堪称首选。而对于处理大量复杂且敏感的文档,自动化和人工智能已不再是奢侈品,而是战略必需品。 通过消除手动提取,您不仅能节省时间并减少错误,还能释放宝贵的人力资源,使其专注于真正重要的事情:分析数据,从而推动更明智、更快速的商业决策。这就是将一份普通文档转化为竞争优势来源的方式。
准备好永远告别复制粘贴了吗? 了解ELECTE 如何ELECTE 加速决策 将您最复杂的PDF文件转化为可操作的洞察。

.svg)
.svg)
.svg)






