

あなたのデータはすでに物語を語っています。問題は、その声があまりにも小さすぎるということです。
中小企業は毎日、顧客からのフィードバック、注文、サポートチケット、財務取引、営業メール、CRMメモなどを蓄積しています。これらすべてのデータには有用な手がかりが含まれています。顧客が離反しそうであることを示すものもあれば、業務上のリスクを予見するもの、あるいはどの製品が売れ行きを伸ばすか、あるいは鈍化するかを示すものもあります。しかし、明確な手法がなければ、それらの手がかりは単なる雑音に過ぎません。
この混沌とした状況に秩序をもたらすアルゴリズムの中でも、ナイーブ・ベイジアン分類器は特別な位置を占めています。そのロジックは理解しやすく、学習も迅速で、その名称である「ナイーブ(素朴)」が連想させるよりも、多くの場合、はるかに効果的です。あらゆるシナリオに適しているわけではありませんが、多くの実際のビジネス課題において、処理速度、解釈可能性、そして有用な結果という3つの要素の間に、他では得難いバランスを提供してくれます。
ビジネスに携わっているなら、それらを理解するために研究者になる必要はありません。重要なのは、それらが何をしているのか、現実を大幅に単純化してもなぜうまく機能するのか、そしてどのような場合に意思決定の助けとなるのかを知ることです。まさにこの点について、じっくり考えてみる価値があります。
多くの企業は、問題が何よりもまず信頼性が高く使いやすいモデルを求めているにもかかわらず、洗練されたモデルを探しがちです。これは、金融、小売、カスタマーケアの分野において、理論的に洗練されたプロセスではなく、より明快なプロセスがしばしば採用されるのと同じ理由です。
ナイーブ・ベイジアン分類器は、非常に具体的な考え方に立脚しています。新しい事例についていくつかの手がかりがあれば、それがどのカテゴリに属する可能性が高いかを推定できます。例えば、メールに特定の単語が含まれていれば、スパムである可能性があります。取引に特定のパターンが見られれば、確認が必要かもしれません。レビューに特定の表現が使われていれば、満足度や不満を示している可能性があります。
「ベイズ」という言葉は、複雑な数式を連想させます。しかし実際には、この手法の核心は直感的なものです。すでに知っていることを基に、新たな証拠を加え、判断を更新する。これは不確実性の下で論理的に考えるための体系的な方法であり、まさに経営者が日々行っていることそのものです。ただ、アルゴリズムによって体系化されているだけなのです。
驚くべきことは、このアプローチが、膨大なデータと迅速な意思決定が求められる現代の環境においても、依然としてうまく機能しているという点だ。それは、このアプローチが世界を完璧に描写しているからではなく、非常に低い計算コストで有用な信号とノイズを分離できるからである。
ビジネス上の課題において、重要な問いは「最も洗練されたモデルはどれか?」ではありません。「実際の業務のペースに合わせて、信頼性の高い意思決定を可能にしてくれるモデルはどれか?」ということです。
だからこそ、ナイーブ・ベイジアン分類器は依然として重要な役割を果たしています。これらは、データの分類、フィルタリング、セグメンテーション、優先順位付けを支援します。また、あらゆるプロジェクトを技術的な難題に変えることなく、意思決定プロセスに確率論を取り入れることを可能にします。
その基本原理はベイズの定理です。簡単に言えば、次のようなものです。まず初期の確率を設定し、新しい情報が得られたらそれを更新する、というものです。
データ科学の用語では、この式は次のように表されます:P(y|x) ∝ P(y) ⋅ ∏ P(x_i|y)。これは、一連の観測値が与えられた場合のクラスの確率が、2つの要素に依存することを意味します。1つ目は、そのクラスの初期確率です。2つ目は、各観測値がそのクラスとどの程度一致しているかです。
これをビジネスの例に置き換えてみましょう。あるメールがスパムかどうかを判断する必要があります。受信メールがスパムであるという大まかな確率があります。そこで、「オファー」「無料」「ここをクリック」といった単語に注目します。これらの単語は、それぞれ最終的な判断に影響を与えます。
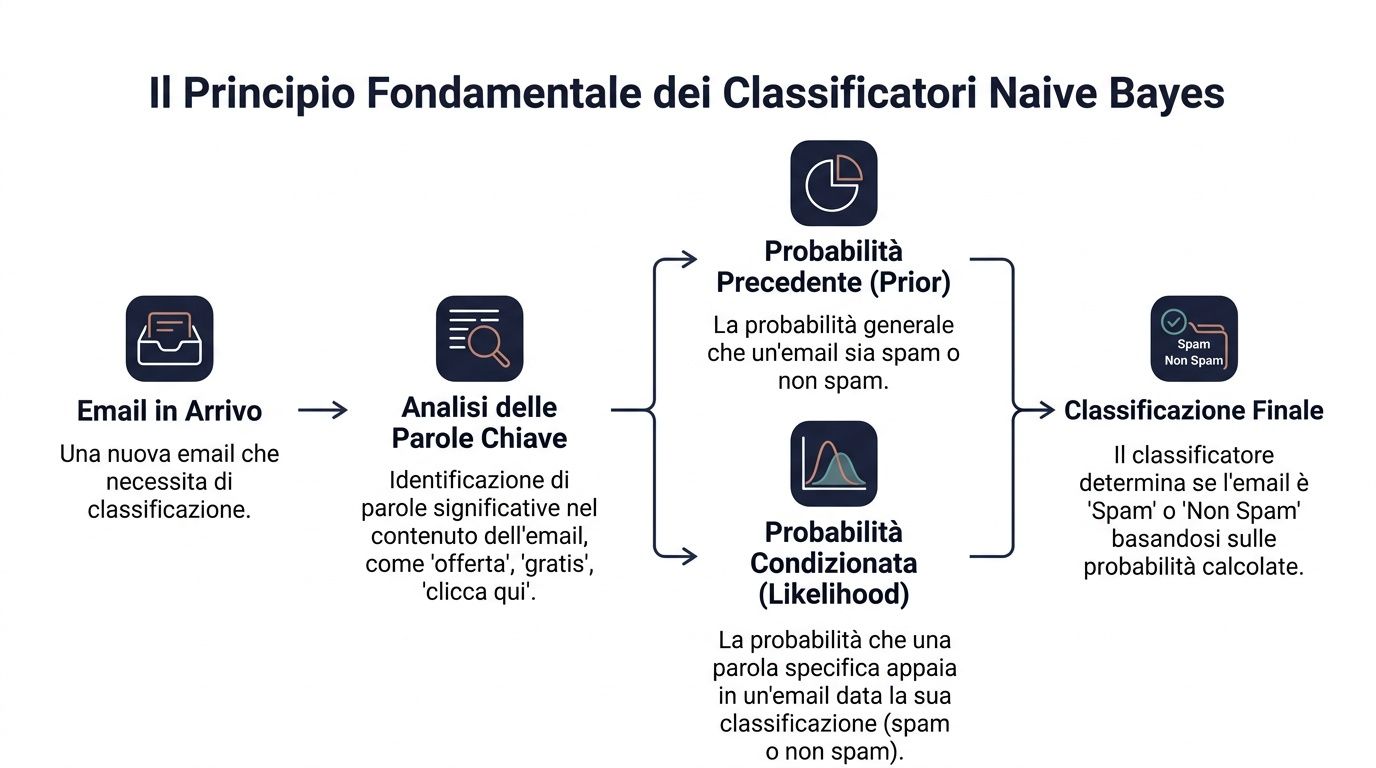
マネージャーは毎日、このようなことを行っています。決して何もないところから決断を下すことはありません。基本的な状況から出発し、そこに手がかりを加えていくのです。これまで定期的に購入していた顧客には、ある種の初期プロファイルがあります。しかし、その顧客がメールを開かなくなったり、注文額が減少したり、重大な問い合わせを寄せたりすれば、あなたの評価も変わってくるでしょう。
「ナイーブ」という用語は、特定の仮定を指します。このモデルは、クラスが既知であるため、特徴量を互いに独立しているかのように扱います。
実際には、メールを分類する際は、各単語を独立した手がかりとして扱うようにしてください。用語間の複雑な関係をすべてモデル化しようとしないでください。これはかなり大雑把な単純化です。実際には、多くの単語が一緒に現れ、企業の行動の多くも相互に関連しています。
しかし、まさにこの選択こそが、このモデルを非常に軽量なものにしている。複雑な依存関係のネットワークを学習する必要はない。より単純な確率を推定し、それらを効率的に組み合わせればよいのだ。
経験則:ナイーブ・ベイズは世界全体を再現しようとはしません。わずかな仮定のもとで、迅速かつ有用な判断を下すことを目指しています。
ここでしばしば誤解が生じます。「単純な仮定」という表現を見て、「弱いモデル」だと結論づける人が多くいます。しかし、そうではありません。モデルは、その単純化が意思決定において重要な要素を捉えている限り、大幅に簡略化されてもなお、十分な説得力を保つことができます。
2004年、ある理論的解析により、独立性の仮定の下でもナイーブベイズ分類器が有効であるという確固たる根拠が示され、また、なぜそれらがロジスティック回帰よりも早く漸近誤差に達することができるのかについても説明された。同様の応用分野であるスパムフィルタリングにおいては、ナイーブベイズ分類器に関する項目で述べられているように、99%を超える精度を達成し、数百万件の文書に対しても拡張性を持つ。
この点は、企業向けの聴衆にとって重要です。アルゴリズムの価値は、最終的なスコアだけにあるわけではありません。迅速に学習し、大規模なデータセットに適応し、かつ解釈可能性を維持できる点にもあります。
テキスト、カテゴリ、タグ、またはシグナルがばらばらに散らばっている場合、ナイーブベイズ分類器は次のような理由からうまく機能します:
ただし、2つの点に留意する必要があります。
そのため、ナイーブベイズは万能の魔法の杖ではなく、高速な分類問題において非常に有効なツールとして捉えるべきです。しかし、多くの実用的な場面において、これは着手するための最も賢明な方法の一つです。
よくある誤解として、ナイーブベイズを、あらゆる状況で同一のモデルであるかのように語ることが挙げられます。実際には、データの種類に応じて設計されたさまざまなバリエーションが存在します。
適切な選択は、手元にあるデータの形式によって異なります。もし適切なバリエーションを選ばなければ、モデルは予測を算出することはできますが、その問題に最適な方法で推論を行っているわけではありません。
ガウス・ナイーブベイズは、特徴量が連続変数である場合に最も適した手法です。例えば、取引の平均金額、顧客の年齢、2回の購入間の平均期間、単位利益、またはレシート金額などが挙げられます。
このモデルでは、各クラス内の値がガウス分布に従うと仮定しています。これを単なる学術的な制約として捉える必要はありません。重要なのは、実用的な観点から、各クラスについて、モデルが中心値と分散を推定するという点です。
このアプローチは、次のようなケースを分類したい場合に役立ちます:
イタリアのEコマースデータに類似したデータセットを用いたscikit-learnのベンチマークにおいて、ナイーブベイズモデルは1000件のサンプルで95%の精度を達成し、学習時間はロジスティック回帰よりも15%短縮されました。 Jake VanderPlas氏の『In Depth Naive Bayes Classification』の章で示されているように、閉形式による学習のおかげで、標準的なCPU上での比較結果は0.01秒対0.1秒となっています。
企業にとって重要なのは、小数点の位置ではありません。重要なのは、このバリエーションなら、長いトレーニング期間や大規模なインフラを必要とせずに、良好な結果が得られるという点です。
テキスト、チケット、レビュー、コメントなどを扱う場合、多項式ナイーブベイズが自然な選択肢となることがよくあります。この場合、特徴量は出現回数や頻度となります。つまり、このモデルは単語や用語が何回出現するかを分析するのです。
これは典型的な次のような状況です:
これがうまく機能する理由は、非常に現実的なものです。ビジネス文書では語彙の幅が広い場合がありますが、どの文書も使用可能な単語のごく一部しか含んでいません。データは散在しています。多項式ナイーブベイズは、まさにこのような構造をうまく処理できるのです。
GeeksforGeeksのナイーブ・ベイズ分類器に関するガイドで報告されているように、感情分析のラベルが付いたイタリア語のツイート10万件を対象とした研究において、多項ナイーブ・ベイズ分類器はF1スコア0.88を達成し、SVMに比べて10倍の処理速度向上を実現した。
覚えやすいように、こう考えてみてください。もしあなたのデータが、数え上げられた単語で埋め尽くされた文書のように見えるなら、多項式モデルがほぼ間違いなく最初に試すべき候補となります。
貴社で大量のテキストを処理する必要がある場合、重要なのは「モデルの精度はどれくらいか?」ということだけではありません。「チームの作業を妨げることなく、どれだけのリクエストを分類できるか?」ということも同様に重要です。
Bernoulli Naive Bayesは二値特徴量を使用します。シグナルが何回出現するかは考慮せず、存在するかしないかのみを判断します。
このバリエーションは、属性の存在そのものが、その出現頻度よりも重要である場合に有用です。企業での具体例をいくつか挙げると:
これは、複雑な現象を、監視しやすい「はい/いいえ」の指標に変換したい場合に非常に役立つ考え方です。例えば、センチメント分析においては、否定的な言葉が何回繰り返されるかよりも、その言葉が登場すること自体がより重要視される場合があります。
ベルヌーイ分布は、多項分布よりも「劣っている」わけではない。単に、データが「ある」か「ない」かを表す場合に適しているだけだ。言葉の上ではわずかな違いだが、結果には大きな差が出る。
| バリエーション | 理想的なデータ型 | 企業向けユースケースの例 |
|---|---|---|
| ガウス・ナイーブベイズ | 連続データ | 金額、頻度、平均値を用いて取引をリスク別に分類する |
| 多項式ナイーブベイズ | テキスト、集計、頻度 | レビューや顧客チケットを感情分析やカテゴリ別に分析する |
| ベルヌーイ・ナイーブベイズ | 二値データ、有無 | コンプライアンス、サポート、または製品利用状況における「はい/いいえ」の回答を評価する |
適切な選択をするには、次の簡単なルールに従ってください:
多くのチームは、絶対的に「最良」のモデルを探そうとするあまり、行き詰まってしまいます。ほとんどの場合、正しい選択とは、そのデータの種類に最も適したモデルを選ぶことです。
幸いなことに、ナイーブベイズを実践に移すのに、大規模なプロジェクトは必要ありません。読みやすいプロトタイプさえあれば、モデルがどのように推論を行うのか、またどのようなデータが必要なのかを理解することができます。

分類器は、ほとんどの場合、4つのステップを経て作成されます。
データの準備
事前にラベル付けされた過去の事例を収集する必要があります。レビューを分類する場合は、すでに「肯定的」または「否定的」とマークされたテキストが必要です。オペレーショナルリスクを分析する場合は、結果が判明している過去の事例が必要です。
モデルの学習モデルはデータを観察し、有用な確率を推定します。ナイーブベイズ分類器では、学習に特に負荷の高い最適化を必要としないため、このプロセスは迅速に行われます。
新規ケースの予測
新しいレコードを入力すると、モデルがクラスを割り当てます。例えば、「スパム」、「スパム以外」、「リスクのある顧客」、「安定した顧客」などです。
の評価:別のテストデータセットを用いて、予測結果と実際の結果を比較します。ここでは、モデルが機能するかどうかだけを見るのではありません。どのように誤差が生じるかを確認します。
予測手法の全体像についてさらに詳しく知りたい場合は、この機械学習アルゴリズムの概要が、ナイーブベイズをより広範な手法群の中に位置づけるのに役立ちます。
このプロセスを具体的に理解するために、scikit-learn を使った簡単な例を挙げておきます。開発者としての視点で読む必要はありません。流れを理解できれば十分です。
# 主要なライブラリを読み込むfrom sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_splitfrom sklearn.naive_bayes import GaussianNBfrom sklearn.metrics import accuracy_score# サンプルデータセットを読み込むX, y = load_iris(return_X_y=True) データをトレーニング用とテスト用に分割するX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# モデルを作成しますmodel = GaussianNB()# 過去のデータでモデルを学習させますmodel.fit(X_train, y_train)# 未見のデータに対して予測を行いますy_pred = model.predict(X_test)# 精度を測定しますprint(accuracy_score(y_test, y_pred))この一節は、一見した以上に多くのことを物語っている。
GaussianNB() 連続データ用のオプションを選択します。fit() モデルが学習する瞬間です。predict() 学んだことを実践する。accuracy_score() 全体として、いくつの分類が正しいかを確認してください。テキストデータの場合、処理の流れはほぼ同じですが、モデルに投入する前にテキストを数値に変換する必要があります。具体的には、単語を分類器が利用できる特徴量に変換します。
コードをざっと目を通した後は、その仕組みを視覚的に確認しておくと役立つでしょう。
最初のモデルは、完璧さを証明するためのものではありません。それは、3つの実務的な疑問に答えるためのものです。
ここがナイーブベイズの強みです。短期間で堅実なベースラインを構築できます。そこから、プロジェクトを複雑化させるべきか、それともシンプルな解決策ですでに価値を生み出しているかを判断できるのです。
分類モデルは、「うまくいっているように見える」という事実だけで評価されるものではありません。そのモデルがどのように誤りを犯すか、そしてそれらの誤りがビジネスにどれほどの影響を与えるかによって評価されるのです。

「精度」は最も直感的な指標です。これは、予測の総数に対して、いくつの予測が正しかったかを示します。有用な指標ですが、これだけでは誤解を招く恐れがあります。
100件の取引のうち、実際に不審なものはごくわずかである場合、ほぼすべてを「正常」と分類するモデルは、精度の面では良好に見えるかもしれませんが、本当に重要な部分では不十分なままとなる可能性があります。
それを理解するには、漁網を想像してみてください。
ビジネスにおいて、この区別は非常に重要です。
優れたモデルとは、単にミスが少ないというものではない。それは、プロセスにとって最もコストのかからない形でミスをするモデルである。
アルゴリズムが過去のデータからどのように学習するのか、またトレーニングの質が最終結果にどのような影響を与えるのかをより深く理解するには、アルゴリズムのトレーニングとは何かについて解説したこちらの記事をご覧ください。
ナイーブ・ベイズは単純ですが、実務上のミスを許容しません。
最初の過ち:ゼロ頻度の問題を無視すること。
あるクラスについて、単語や値がトレーニングデータに一度も出現しない場合、その確率はゼロまで低下し、計算に支障をきたす可能性があります。そのため、カウント値にわずかな補正を加えるラプラス平滑化がよく用いられます。
2つ目の間違い:相関の強い特徴量を使用すること。
2つの列がほぼ同じ情報を表している場合、モデルはシグナルを過大評価してしまうリスクがあります。モデルは、2つの手がかりがほぼ重複していることを「理解」できないのです。
3つ目の間違い:単純な確率を過信すること。
ナイーブベイズは多くの場合、正確な分類を行うが、その確率値は過信しがちである。ビジネスにおいて、これはランキング自体は有用である一方、確率の正確な数値については慎重に解釈すべきであることを意味する。
これらのリスクを軽減するためには、以下の点に留意することが望ましい:
ナイーブ・ベイジアン分類器の真価は、それを単なる数学的な演習として捉えるのをやめ、優先順位の決定ツールとして使い始めた時に初めて明らかになります。企業において、適切な分類を行うことは、ほとんどの場合、より良い意思決定につながるのです。

取引の流れ、業務内容、過去のデータなどを分析する財務チームを想像してみてください。各行は単なる記録ではありません。それは「そのまま通過させるか、詳細を確認するか、停止させるか、アナリストに回すか」という、潜在的な判断の分かれ目なのです。
ナイーブベイズでは、さまざまな指標を組み合わせて単一の分類を行うことができます。指標には数値型、二値型、テキスト型などがあります。このモデルは、どのケースが「正常」や「異常」といった既知のパターンに最も近いかを判断するのに役立ちます。
実用的なメリットは2つあります:
規制された環境において、人間の判断に取って代わるものではありません。それを体系化するものです。そして、大量の業務処理を行うプロセスにおいては、これが大きな違いをもたらします。
マーケティングにおいて、セグメンテーションとは、多くの場合、各顧客を特定のグループに分類することを意味します。ロイヤル顧客。価格に敏感な顧客。離反リスクのある顧客。プロモーションに反応しやすい顧客。休眠顧客。
ここでナイーブベイズが役立つのは、多様なシグナルを素早く統合できるためです:
CRMチームに必要なのは、人間行動に関する完璧な理論ではありません。必要なのは、適切なアクションを起こせるだけの、ある程度精度の高いセグメンテーションです。例えば、メッセージの内容や連絡頻度、オファーの種類を変更することなどです。
あるモデルが、適切な顧客に向けた次のメッセージの選択を支援できる場合、それはすでに業務上の価値を生み出していることになる。
小売業界やEコマースにおいて、分類という作業は、一見異なるように見えても、同じ論理、すなわち「混沌を整理する」という目的を共有する活動を支えています。
商品を販売実績に基づいて分類することができます。レビューや問い合わせ内容を確認することで、どのカテゴリーで顧客の離脱が発生しているかを把握できます。また、需要の傾向を把握することで、チームがより的確にプロモーションや在庫計画を立てられるようになります。
このような環境では、データは量が多く、多種多様で、必ずしも完璧とは限りません。そのため、迅速で拡張性があり、理解しやすいモデルには大きな価値があります。それは、最も華やかなモデルだからではなく、ワークフローにスムーズに組み込まれ、その流れを妨げないからです。
ビジネスに適用されたアナリティクスの手法が、具体的なプロジェクトでどのように形になっているかをご覧になりたい方は、ぜひこれらの事例研究をご覧ください。
ナイーブ・ベイズを理解することは有益です。しかし、それをビジネス環境で適切に実装するのはまた別の話です。
問題は、ほとんどの場合、アルゴリズムだけにあるわけではありません。本当の仕事はモデルの周りにあります。さまざまなデータソースを連携させ、欠落しているフィールドを処理し、テキストを準備し、ラベルを更新し、出力の品質を確認し、意思決定者が理解できる形で結果を読み解く必要があります。
中小企業にとって、この段階はしばしば最大の難関となります。AIへの関心が欠けているからではなく、チームの時間が限られており、業務上の優先事項は待ってくれないからです。
ここでは、技術的な複雑さを解消してくれるプラットフォームを活用するのが理にかなっています。AIを活用したソリューションなら、ビジネス部門にコードの記述やライブラリの選択、手動でのパイプラインの維持管理を求めずとも、生データを分かりやすいインサイトに変換することができます。
ELECTEのような、中小企業向けのAI搭載データ分析プラットフォームを利用すれば、機械学習の専門知識がなくても、ナイーブ・ベイジアン分類器などの手法を活用できます。そのメリットは、単に処理が速いということだけではありません。データと意思決定の間の障壁が低減される点にあります。
自動化がうまく機能しているとき、チームはもはや「公式」という観点で物事を考えなくなります。代わりに、次のような「有用な質問」という観点で考えるようになります:
こうした理由から、AIによって生成されたコンテンツや、社内プロセスで流通するテキストの信頼性を判断するのに役立つツールを求める企業が増えています。こうした状況において、特にチームが文書やコンテンツの取り扱い、言語チェックを行っている場合は、イタリア語対応のAI検出ツールに関するガイドを参照すると役立つでしょう。
要するに、その違いは単純明快です。断片的な技術的なプロセスを管理するのではなく、企業の成果に焦点を当てるのです。そして、こここそが、AIが単なる「興味深い」存在から、真に実用可能なものへと変わるポイントです。
ナイーブ・ベイジアン分類器は、重要な教訓を示しています。分析の世界では、適切に活用された単純さは、不適切に扱われた複雑さを凌駕し得るのです。
直感的な確率論的基盤、優れた拡張性、そして極めて具体的な活用事例を備えたこのアプローチは、情報を分類し、隠れた兆候を読み取り、より確信を持って行動したいと考える企業にとって、依然として信頼できるツールです。その価値を理解するために、機械学習の専門家である必要はありません。重要なのは、数学を経営判断に結びつけることです。
この関連性が明確になれば、AIは単なる技術的な課題ではなく、組織的な強みへと変わります。そこで初めて、予測が真の成果を生み出し始めるのです。
散在するデータを明確なインサイトに変えたいなら、ぜひ ELECTEをお試しください。このプラットフォームは、中小企業がデータソースを連携させ、分析を自動化し、迅速かつ的確な意思決定に役立つレポートや予測を取得できるよう支援します。

.svg)
.svg)
.svg)






