Strategia dei Contenuti per CMS: Dal Caos alla Coerenza
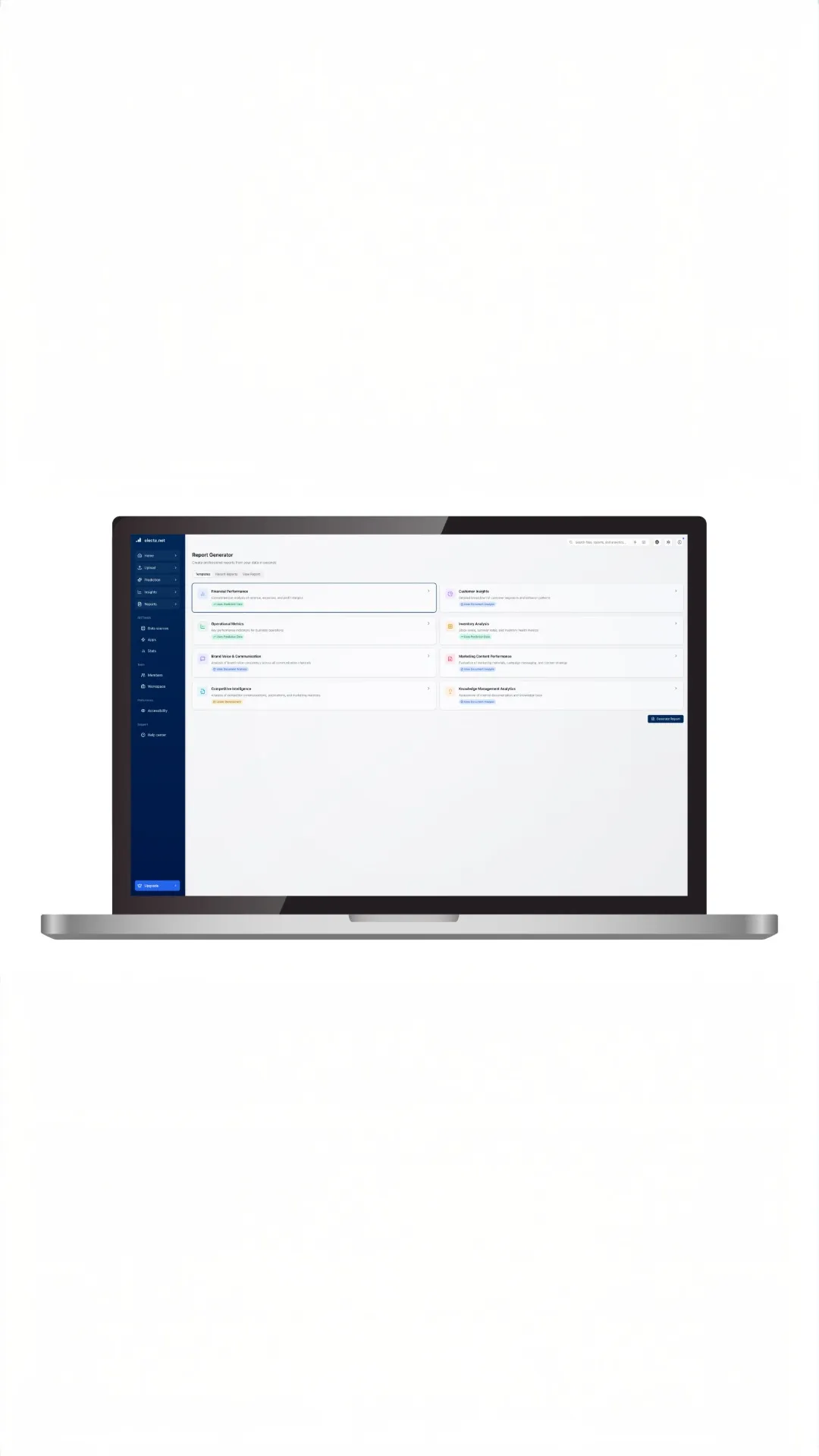
Avere un CMS potente senza strategia dei contenuti è come una Ferrari senza patente: potenziale sprecato che genera caos costoso con contenuti contraddittori, sforzi duplicati e ROI invisibile. Senza strategia si creano incoerenza di brand, duplicazione di lavoro, opportunità SEO perse ed esperienza utente frammentata. Una strategia efficace parte da obiettivi chiari e misurabili collegati a risultati business specifici: generazione lead qualificati, thought leadership, riduzione costi supporto, traffico organico, retention clienti. Inizia con obiettivi chiari, comprendi il pubblico realmente, pianifica realisticamente, stabilisci standard di qualità e misura rigorosamente.



















.webp)
.webp)
.webp)

.webp)
.webp)
.webp)

.webp)
.webp)



.webp)