

你透過 PEC 收到一個 XML 檔案。你在瀏覽器中開啟它,看到滿屏的標籤,便以為問題在於「如何讀取」它。事實上,這只是第一個障礙。企業面臨的真正問題在於:如何判斷這些資料是否正確、一致,且已準備好納入你的報表中。
對許多義大利中小企業而言,這個議題已不再僅是狹義上的技術問題。自從電子發票成為強制規定以來,XML 已融入行政管理、管理監控與分析的日常工作中。 僅僅檢視文件是不夠的。您必須懂得區分「可讀取的檔案」與「可信賴的檔案」。您還需了解何時只需快速檢查,何時則需在將資料上傳至 Excel、商業智慧(BI)或分析平台之前,先進行解析、驗證與標準化處理。
如果你正在尋找一份關於如何讀取 XML 檔案的實用指南,這正是正確的途徑:從簡單的方法開始,了解哪些環節會出錯,然後建立一個流程,將原始 XML 轉化為對業務有用的資料。這樣一來,不僅能減少錯誤,還能縮短從「取得檔案」到「獲得可用的洞察」之間所需的時間。
XML 檔案會將資料以階層式結構進行組織。其中包含一個主元素,以及若干嵌套的區段,每個區塊皆描述一項具有明確意義的資訊。對於負責行政流程的人員而言,這項細節正是區分「可讀資料」與「真正可用的資料」的關鍵所在。
重點不在於「開啟」該檔案。重點在於釐清該檔案能否無誤地納入控制、會計及分析流程中。
以電子發票為例。在同一個檔案中,同時包含供應商資料、客戶資料、應稅金額、增值稅、商品明細、付款條件、訂單編號,以及經常會讓閱讀變得複雜的例外情況。在 XML 中,這些資訊並非像一般文件那樣逐行排列,而是被放置在精確的位置,而該位置即說明了這些資訊所代表的內容。
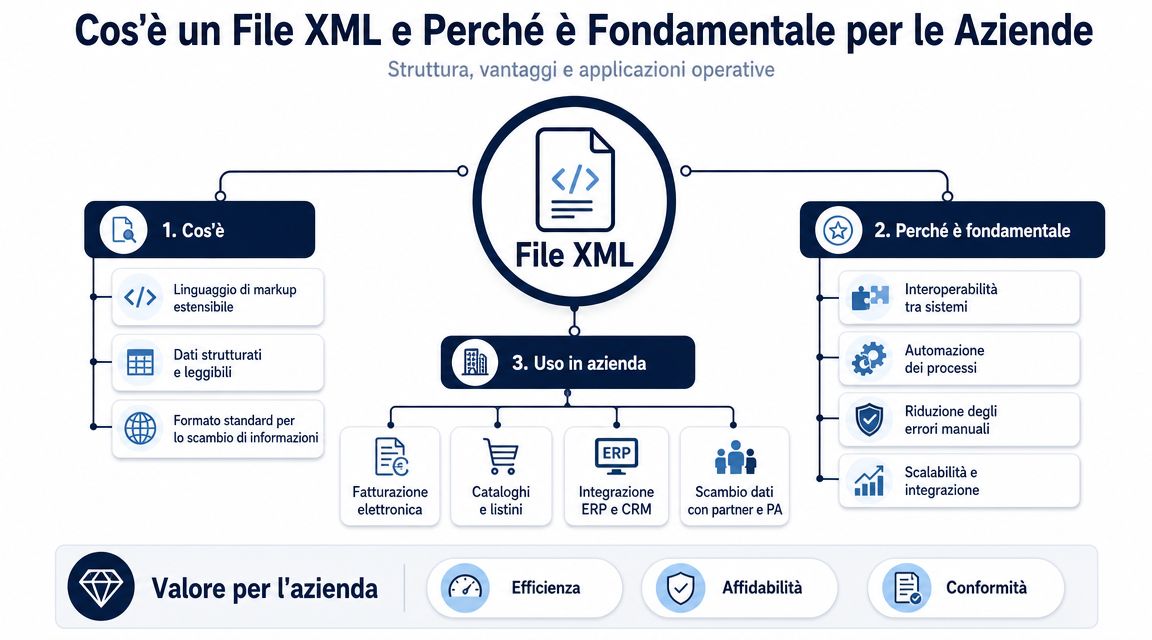
對管理者而言,有用的區別並非在於理論層面的「標籤」與「屬性」之間,而在於「孤立的數據」與「可靠的數據」之間。若脫離上下文僅看到「1000,00」,幾乎毫無意義;但若在檔案的正確位置解讀此數值,便能判斷它究竟是文件總額、應稅額、稅額,還是單一行項的數值。
這正是第一個運作上的優勢所在。XML 能保留資料的上下文。
實務準則:仔細閱讀 XML 檔案,意味著要驗證數值的含義,而不僅僅是數值本身。
在義大利,隨著電子發票的普及,這個議題已成為現實。在 FatturaPA 格式中,XML 已成為稅務文件的標準格式。因此,其解讀不再僅是資訊科技部門的責任,更涉及行政管理、管理控制、採購部門,以及所有需要利用這些資料來做出決策的人員。
在實際操作中,我總是看到同樣的問題。檔案確實存在,資料也確實在,但將其轉化為有用資訊所需的時間卻過於漫長。有人會開啟 XML 檔案,進行目視檢查,將數值複製到 Excel 中,修正格式不統一的欄位,將寫法各異的供應商名稱重新命名,並試圖重建那些檔案中未以可供分析形式呈現的支出類別。這不僅是營運成本的問題。 這更是「從數據到洞見」所耗費的寶貴時間。
使用 FatturaPA 時,此風險更為明顯。即使兩份檔案在形式上完全正確,若其中一份的明細描述極為混亂、訂單編號不完整,或是供應商資料以不同變體輸入,仍可能引發相同的分析問題。此時,問題已不在於讀取 XML,而在於如何避免有效的稅務資料轉變為不可靠的營運資料。
一個常見的錯誤,是將 XML 視為需檢視的附件。在企業中,若能將其視為結構化的資料來源——在將其用於生成報表、儀表板及支出模型之前先進行核對——效果會更好。若此階段處理不當,財務團隊便會陷入討論那些看似精確、實則建基於分類標準不一致的數字的困境。
一開始,該問的正確問題是這些:
這些都是非常具體的核對工作。其目的在於避免報告中出現重複的供應商、增值稅計算錯誤、成本中心資料填報不完整,以及月底對帳作業延遲。
這正是技術解析與商業價值之間差距的體現。解析器會讀取檔案;一個設計完善的流程能產出乾淨、可比對且可直接進行分析的數據。像 ELECTE 這樣的平台正是為了彌合這項差距而誕生,藉此減少人工處理的步驟,使接收到的 XML 能直接轉化為有助於做出更佳決策的洞見。
若要對單一檔案進行快速檢查,無需使用解析器或函式庫。關鍵在於釐清:您是僅對少數欄位進行目視檢查,還是已經在處理那些最終會用於會計、報表或管理控制的資料。這其中的差異至關重要,特別是在處理 FatturePA 時。今天草率進行的檢查,明天可能會在供應商資料集中變成一筆錯誤的記錄。

瀏覽器、文字編輯器及專用檢視器能解決一個具體問題:無需設定技術流程即可快速閱讀內容。對於單一檔案而言,這通常已足夠。 您可以透過 Chrome、Edge 或 Firefox 開啟 XML 檔案來檢視其結構,或者使用「記事本」、「WordPad」或「TextEdit」直接檢視標籤。就電子發票而言,專用的檢視器能讓票面資訊、明細項目、應稅金額及增值稅等內容更易於閱讀。
重點在於:
| 工具 | 適用於 | 主要限制 |
|---|---|---|
| 瀏覽器 | 對結構進行快速目視檢查 | 未檢查欄位與區段之間的一致性 |
| 文字編輯器 | 直接檢查標籤 | 在處理長檔案或嵌套檔案時會變得不便 |
| Excel | 以表格形式呈現的初步檢查 | 在處理層級結構和重複內容時表現不佳 |
| 專用檢視器 | 更清晰地閱讀發票與稅務文件 | 不會將資料預先處理以供分析或自動化使用 |
若您需要核對文件日期、增值稅號、發票總額或附件是否存在,這些工具都很適合。
反之,若目標是比較供應商、分類支出或為儀表板提供資料,僅靠視覺化呈現不僅會拖慢工作進度,更會留下過多的人為錯誤空間。這正是「查看檔案」與「及時獲得可靠數據」之間典型的落差。
開啟 XML 檔案並不等同於驗證您將在報表中使用的資料。
另一個實務考量在於數量。十張發票即使手動核對也尚可,但若涉及數百張 FatturePA 發票,則難以應付。在這種情況下,便應考慮建立可重複執行的流程,或採用能以結構化方式讀取內容的工具,例如透過API 以整合方式擷取並管理稅務文件。
在義大利,經常出現的問題並非開設一家 .xml,但要明白當一個……來臨時該怎麼做 .xml.p7m 透過 PEC 傳送。必須區分簡單的 XML 檔案與經數位簽章的檔案。後者需要能夠讀取簽章、擷取內容並顯示正確 XML 內容的工具,正如以下所述: 這份指南專門介紹 PEC 中的 XML 和 XML P7M.
在此處,錯誤會耗費時間:
對於一名行政人員來說,最實用的步驟很簡單:
這些方法在第一層級的檢查中表現良好。但它們並未解決企業面臨的真正難題:如何將往往不規範或缺乏統一性的稅務 XML 文件,轉化為乾淨且可比對的數據,同時不延長從收到文件到獲得有用資訊所需的時間。
當檔案開始堆積時,手動處理便不再可行。到了那個時候,透過程式碼讀取 XML 檔案已非明智之舉。這是避免重複性工作、複製錯誤及資料集不一致的第一步。

一種紮實的 XML 解析方法總是遵循相同的邏輯:解析、正規化、針對性提取。在 Java 和 Android 的教學中,正確的流程是從 parse(), 透過對樹進行正規化,使用 doc.getDocumentElement().normalize() 接著是透過以下方式恢復球場: getElementsByTagName,這是一種比在純文字編輯器中檢視更穩定的方法,如以下所示 這份關於讀取 XML 資料的技術教學指南.
這一步驟比你選擇的程式語言更為重要。如果你跳過正規化步驟、以過於簡單的方式搜尋節點,或是假設某個標籤永遠只會出現一次,你的腳本雖然能在某些檔案上運作,卻恰恰會在那些關鍵檔案上失敗。
對於日後需與外部系統進行互動的專案,建立一套可重複執行且有文件記錄的資料擷取流程將有所助益。若您從事應用程式整合工作,ELECTE 的 API 文件(附經驗證的 Postman 配置檔)將是實用的參考基礎,特別是為了了解如何將已清理好的資料集與後續流程進行串接。
以下提供一些最簡單的範例。目的並非涵蓋所有情況,而是向您展示基本的邏輯:開啟檔案、尋找節點、輸出一個值。
import xml.etree.ElementTree as ETtree = ET.parse("fattura.xml")root = tree.getroot()numero = root.find(".//Numero")if numero is not None:print(numero.text)在進行原型開發、資料轉換及輕量級處理流程時,Python 通常是最快速的选择。當您需要讀取大量 XML 檔案、擷取少數欄位,並將其儲存為 CSV 或 JSON 格式時,Python 表現尤為出色。
const xmlString = `<fattura><Numero>123</Numero></fattura>`;const parser = new DOMParser();const xmlDoc = parser.parseFromString(xmlString, "application/xml");const numero = xmlDoc.getElementsByTagName("Numero")[0];console.log(numero.textContent);這種方法適用於頁面上的快速測試或小型內部工具。對於輕量級介面來說很合適,但對於結構化的後台工作流程則較不適用。
const fs = require("fs");const xml2js = require("xml2js");const xml = fs.readFileSync("fattura.xml", "utf8");xml2js.parseString(xml, (err, result) => {if (err) throw err;console.log(result.fattura.Numero[0]);});若您從事伺服器端開發並希望建立自動化流程,Node.js 仍是實用的選擇。其優勢在於能輕鬆將 XML 讀取功能與檔案系統、處理佇列及內部服務整合。
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();DocumentBuilder builder = factory.newDocumentBuilder();Document doc = builder.parse("fattura.xml");doc.getDocumentElement().normalize();NodeList lista = doc.getElementsByTagName("Numero");if (lista.getLength() > 0) {System.out.println(lista.item(0).getTextContent());}Java 經常應用於企業、管理系統及中介軟體等領域。在此,關鍵不僅在於讀取資料,更在於以可預測且易於維護的方式進行讀取。
library(XML)doc <- xmlParse("fattura.xml")numero <- xpathSApply(doc, "//Numero", xmlValue)print(numero)當語法分析是分析工作的一部分時,使用 R 便有其意義。若您接下來的步驟是進行統計分析或資料預處理,便可將所有流程都維持在同一個環境中。
如果你的團隊每週都開啟相同的檔案並重複執行相同的檢查,那你已經踏入了自動化領域。
真正的價值不在於「透過程式碼讀取 XML」,而在於讓人們擺脫機械性工作,並建立一套能產生一致資料集的工作流程。
當檔案不再是單一檔案時,嚴重的問題便會開始浮現。單張 FatturaPA 幾乎總是能夠輕鬆處理。困難之處在於,當您必須整合數個月的文件、來自不同供應商的資料、填寫方式不一致的欄位以及嵌入的附件時,便會遇到挑戰。
在義大利的中小企業中,最常見的情況並非單一的「巨型檔案」,而是批次處理。 每年匯出的應付發票,可能產生一個包含超過 380,000 個節點的結構,涵蓋4,200 張發票,其中包含標題、明細行、付款資料以及 base64 編碼的附件。在這種情況下,問題不在於開啟文件,而在於如何將異質的 XML 轉換為一致的資料集。
這涉及一項會影響業務運作的技術抉擇。在 .NET 環境中,微軟指出XmlDocument會將文件載入記憶體中,適合用於讀取和修改;而對於大型檔案或唯讀操作,則建議採用更高效的解決方案(例如串流解析器或XPathDocument),以避免過度消耗 RAM,詳情請參閱微軟關於使用 XmlDocument 和 XPathDocument 讀取 XML 的文件。
實際上:
權衡很簡單。記憶體內模型能讓開發速度更快;而當檔案數量變多或體積變大時,串流模型在生產環境中的表現更為穩定。
許多團隊僅止步於 XSD 驗證。這固然有用,但還不夠。一個檔案即使符合模式,在後續處理過程中仍可能產生不正確的資料。
來自實際運作的典型範例:
| 檢查類型 | 檢查什麼 | 為什麼需要它 |
|---|---|---|
| 結構性 | 標籤、格式、層級結構 | 避免語法分析錯誤 |
| 語義學 | 資料的邏輯一致性 | 避免錯誤的分析 |
| 運作中 | 報告所需欄位的存在 | 避免使用無法使用的資料集 |
最狡猾的情況是這樣的:雖然「文件總金額」在形式上有效,但與各行金額的總和不符,這可能是由於供應商管理系統的四捨五入邏輯所致。又或者,雖然增值稅代碼在形式上符合規定,但與交易性質不符。
即使是一個形式上正確的檔案,仍可能影響您的報表品質。
此外,FatturaPA 中還存在另一項已知的陷阱。DatiBeniServizi標籤包含自由描述文字。同一筆成本可能以多種不同形式呈現,文字內容可能清晰、簡短或晦澀難懂。若未進行標準化處理,任何按支出類別進行的分析都將變得不可靠。
正因如此,在嚴謹的資料流處理中,檔案讀取僅是第一層。第二層始終是一套關於一致性與資料潔淨度的規則。資料品質的保障就在於此,而非取決於解析器。
即使能順利讀取的 XML 檔案,也還稱不上是有用的資料集。它只是一份結構化的文件。若要進行分析、比較、分組及建立儀表板,幾乎總是必須將其轉換為更易於處理的格式。
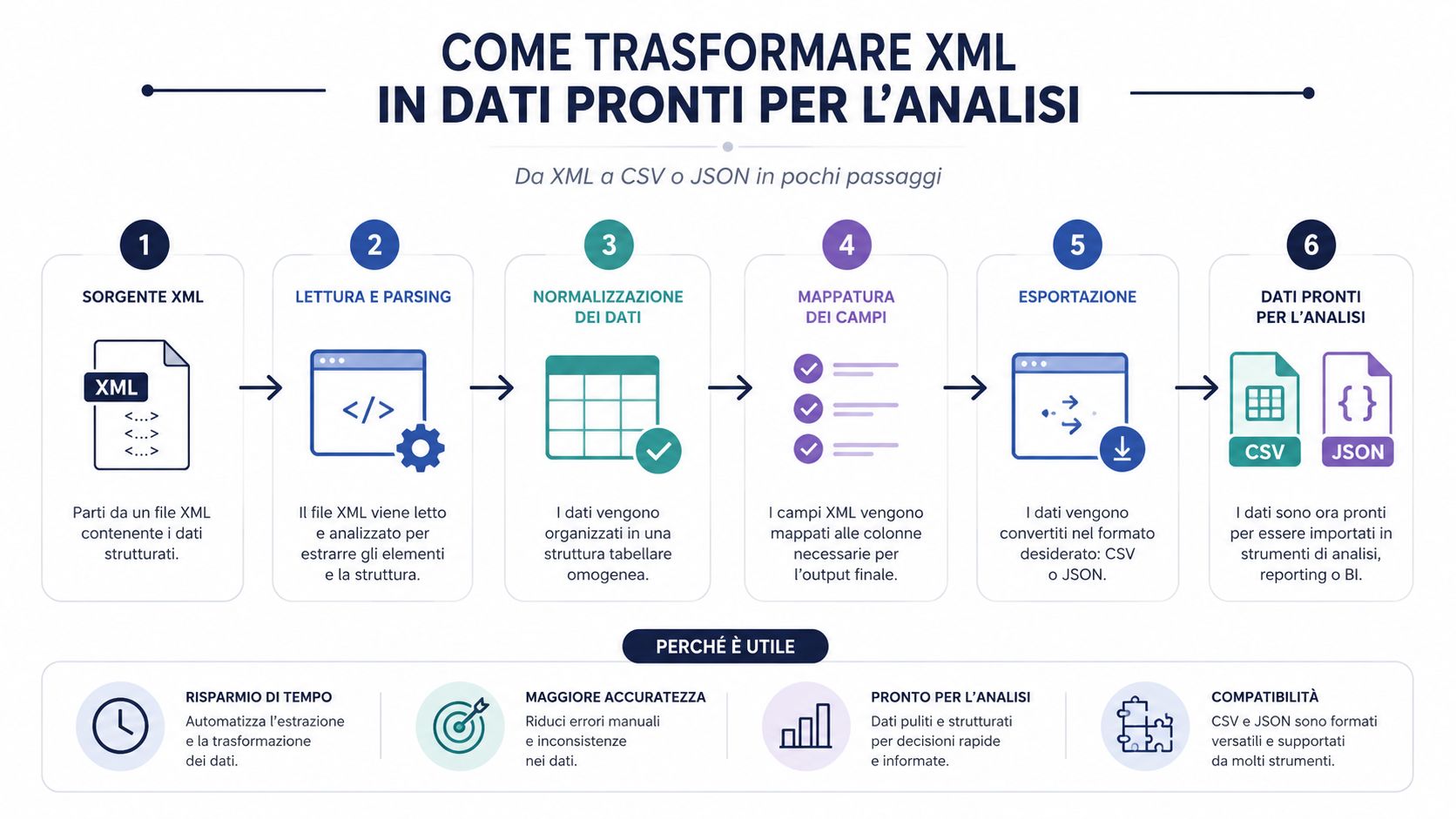
這是許多流程常被低估的一點。瓶頸很少出在純粹的語法分析上。一個像樣的函式庫能夠快速讀取 XML。時間主要耗費在解析結構、擷取有用欄位、資料清理、標準化,以及將資料上傳至分析工具等步驟上。
正因如此,將資料轉換為CSV或JSON並非僅是為了方便。這是一項關鍵的操作步驟。若跳過此步驟而直接處理原始檔案,幾乎總是會導致必須進行手動檢查、臨時增設欄位,以及產生難以複製的邏輯。
對於經常在 XML 和試算表之間切換工作的人來說,這份關於如何更條理分明地將 XML 轉換為 Excel 的指南,將是一份實用的參考資料。
選擇合適的格式,取決於您之後將如何使用這些資料。
當您希望每份文件對應一行,或每筆發票明細對應一行,並接著使用 Excel、Power Query 或 BI 時,CSV 便能發揮其優勢。
Python 範例:
import xml.etree.ElementTree as ETimport csvtree = ET.parse("fattura.xml")root = tree.getroot()with open("fatture.csv", "w", newline="", encoding="utf-8") as f:writer = csv.writer(f)writer.writerow(["編號", "日期"])編號 = root.findtext(".//Numero")data = root.findtext(".//Data")writer.writerow([numero, data])其優點在於簡單。其限制在於,你必須仔細決定如何簡化層級結構。如果一張發票有多行明細,就需要針對細粒度與關聯鍵做出明確的選擇。
當您希望保留部分層級結構時,JSON 會是更合適的選擇。
JavaScript 範例:
const record = {numero: "123",data: "2024-01-15",righe: [{ descrizione: "Servizio", importo: "100.00" }]};console.log(JSON.stringify(record, null, 2));當您的下一步是 API、資料湖,或是能良好處理嵌套物件的應用程式時,請使用此功能。
以下是一條實用的準則:
XML 檔案是容器。CSV 和 JSON 則是讓內容真正能夠被處理的格式。
若想縮短「洞察時間」,這正是值得投入心力的地方。重點不在於尋找更方便的視覺化工具,而在於定義一套穩定且可重複的轉換流程。
一旦檔案被讀取、驗證並轉換完成,工作性質便會產生變化。你不再需要與標籤搏鬥,而是終於能著眼於成本、異常狀況、供應商、支出類別及營運趨勢。
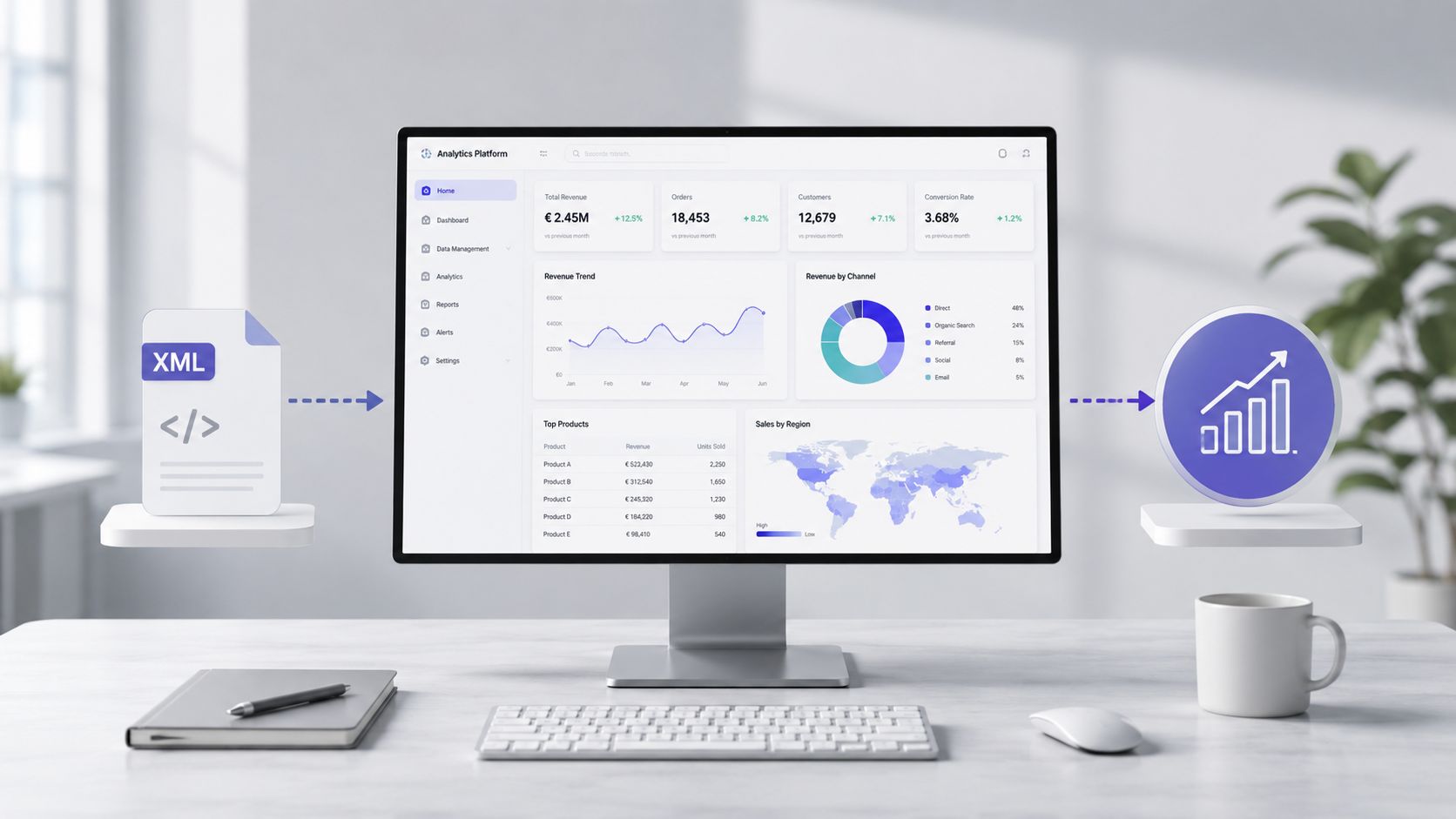
在實際工作中,價值並不在於解析所需的時間,而在於從原始檔案到能夠據此做出決策的資訊之間所耗費的時間。若採用手動流程,人員必須先開啟文件、理解其結構、提取欄位、清理數值、規範化文字,然後才能建立報告。這是一個容易出錯的過程。
在 FatturaPA 中,一個經典的例子就是「DatiBeniServizi」中的自由輸入欄位。同一項服務可能由不同供應商以多種不同方式描述。若在缺乏一致映射的情況下匯入這些資料,按成本類別進行分析時便會產生無用的彙總結果。
因此,在建置分析平台之前,需要先建立一個資料預處理層,因為:
只要這一步驟執行得當,任何分析平台的運作效果都會更佳。若您想深入了解此步驟在決策與視覺呈現方面的應用,關於「如何運用數據講述故事」的資源將有所助益,因為它展示了如何將經過清理的資料集轉化為對決策者有用的敘事。
至此,XML 檔案已不再僅是技術問題,而是成為獲取洞見的原料。一套精心準備的資料集,可作為支出分析、趨勢監測、偏差檢視及異常狀況解析的依據。
若要選擇適合這「最後一哩路」的平臺,您可以比較現代商業分析軟體所提供的功能,與純粹基於試算表和樞紐分析表的手動工作流程,以此作為參考依據。
這裡的正確標準並非「會讀取 XML 嗎?」。那只是基本要求。真正有意義的問題是另一個:
| 問題 | 為什麼這很重要 |
|---|---|
| 資料輸入時已經過清理 | 避免基於錯誤數據得出精確的洞察 |
| 這些類別是相互一致的 | 您是否真的會比較供應商和期間? |
| 異常情況會立即顯現 | 減少因手動檢查而浪費的時間 |
| 該報告適合企業與財務部門閱讀 | 加速決策過程 |
不成熟流程與成熟流程之間的差異,不在於能否讀取 XML 檔案,而在於能否將其轉化為可靠的数据庫,使團隊無需每次都重複進行相同的工作。
若您需要以符合商業需求的方式讀取 XML 檔案,請牢記這份檢查清單。它比任何技術定義都更切實可行,能協助您迅速選擇正確的方法,避免浪費時間。
不要總是採用同一种方法。瀏覽器、編輯器和檢視器適合用於快速檢查。當檔案需要驅動重複處理流程時,則需使用解析器和腳本。若將資料檢視與資料處理混為一談,可能會導致建立在脆弱基礎上的報表。
檔案 .xml.p7m 這需要進行特定的簽名管理步驟。若內容來自 PEC,此項檢查並非附帶程序,而是正確讀取文件的一部分。
即使遵循了標準格式,也無法保證資料集的品質。邏輯上的不一致——例如總和不對齊或稅務分類模糊不清——往往是最常破壞分析結果的因素。語義檢查正是區分「尚可」檔案與可靠資料的關鍵。
CSV 和 JSON 並非僅是表面上的調整。它們是讓 XML 能被分析工具、試算表、處理流程及報表所運用的關鍵。越早定義這項轉換,就能越早減少手動作業和臨時應變。
你的目標並非讀取 XML 檔案,而是從中獲取有用的洞見,同時避免讓系統因骯髒資料而受到污染。如果資料流無法產生一致的資料集,問題並不在於最終的儀表板,而是出在更上游的環節。
實際上,你可以在每個新專案開始前使用這份簡短的檢查清單:
若您希望將已準備好的數據轉化為清晰且可付諸行動的洞見,ELECTE能協助中小企業從「乾淨的數據集」邁向「智慧型報表」,其採用的一套方法,即使是非技術團隊也能輕鬆上手。這是縮短營運數據與決策之間距離的最快途徑。

.svg)
.svg)
.svg)
.webp)





