

您的數據其實早已在訴說一個故事。問題在於,它們的聲音往往太過微弱。
每一天,中小企業都會累積客戶回饋、訂單、客服單、財務交易、商業電子郵件以及 CRM 備註。這些資料中蘊含著有用的訊號。有些訊號顯示客戶即將流失;有些預示著營運風險;還有一些則顯示哪些產品的銷售勢頭即將加速或放緩。然而,若缺乏明確的方法,這些訊號終將淪為雜訊。
在眾多有助於為這片混亂帶來秩序的演算法中,天真貝葉斯分類器佔據著特殊的位置。其運作邏輯簡單易懂,訓練速度快,且往往比「天真」這個名稱所暗示的更為有效。雖然它們並非適用於所有情境,但在許多實際的企業問題中,它們能提供速度、可解釋性與實用成果之間難得的平衡。
如果你從事商業領域的工作,無需成為研究人員才能理解它們。你需要了解它們如何運作、為何即使在大幅簡化現實的情況下仍能有效運作,以及在哪些情況下它們能幫助你做出更明智的決策。這正是值得我們深入探討之處。
許多企業在面對問題時,往往尋求複雜的模型,卻忽略了問題首先需要的是可靠且易於使用的模型。這正是為何在金融、零售或客戶服務領域,通常最清晰明確的流程會勝出,而非理論上最精妙的流程。
朴素貝葉斯分類器基於一個非常具體的概念。若你掌握了關於某個新案例的若干線索,便能以相當高的機率推斷它屬於哪一類別。若一封電子郵件包含特定詞彙,它可能是垃圾郵件;若一筆交易呈現特定模式,可能需要進行審查;若一篇評論使用了特定詞彙,則可能表示滿意或不滿。
「貝葉斯」一詞常讓人聯想到複雜的公式。事實上,這種方法的核心是直觀的:先基於已知資訊,再加入新證據,進而更新判斷。這是一種在不確定性下進行有條理推理的方式,正是管理者每天都在做的事,只是透過演算法使其系統化罷了。
令人驚訝的是,這種方法即使在當今數據龐大、決策迅速的現代環境中,依然運作良好。這並非因為它能完美地描述世界,而是因為它能以極低的運算成本,將有用的訊號從雜訊中分離出來。
在商業問題中,正確的問題並非「哪種模型最精確?」,而是「哪種模型能在符合實際工作進度的時間內,為我提供可靠的決策?」
正因如此,朴素貝葉斯分類器依然至關重要。它們能協助您進行分類、篩選、區隔與優先排序,並讓您將機率概念融入決策流程,同時無需將每個專案變成技術工程。
其基本原理是貝葉斯定理。簡單來說,就是:先從一個初始機率出發,然後在獲得新資訊時更新這個機率。
在數據領域中,該公式可表述為:P(y|x) ∝ P(y) ⋅ ∏ P(x_i|y)。這意味著在給定一組信號的情況下,某個類別出現的機率取決於兩個因素。第一是該類別的初始機率;第二則是每個信號與該類別的契合程度。
以商業案例來說明。你必須判斷一封電子郵件是否為垃圾郵件。你對收到的郵件是否為垃圾郵件有一個大致的判斷機率。接著,你會觀察一些詞彙,例如「優惠」、「免費」、「點擊此處」。這些詞彙中的每一個都會影響最終的判斷。
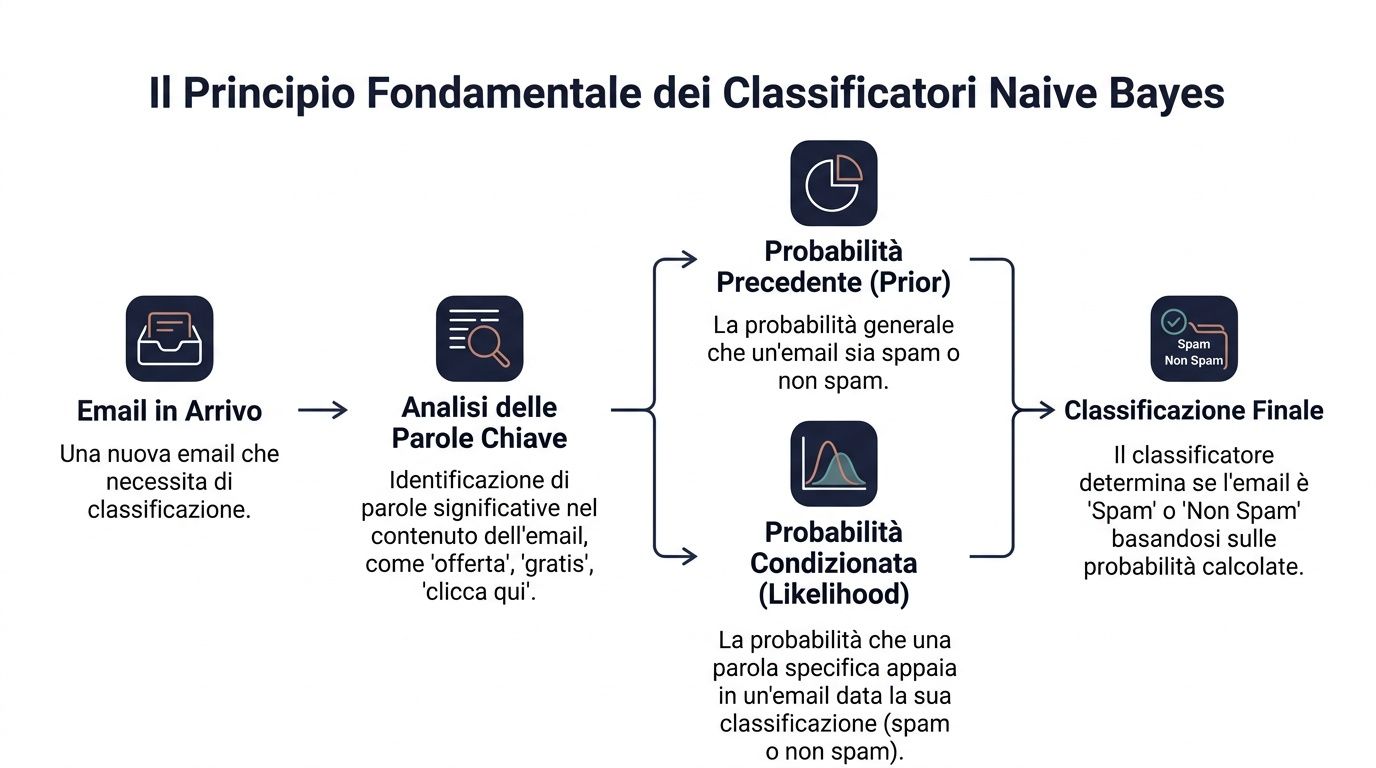
管理者每天都會做類似的事情。他們從不憑空做決定。他們會從基本背景出發,並逐步補充線索。一位一直定期下單的客戶,起初會有某種特徵輪廓。如果他後來不再開啟電子郵件、降低訂單金額,或是提交了一張關鍵的服務單,你的評估就會隨之改變。
「naive」一詞指的是一種明確的假設。由於類別已知,該模型將特徵視為彼此獨立。
實際上,當你對一封電子郵件進行分類時,請將每個單字視為一個獨立的線索。不要試圖建模詞彙間的所有複雜關聯。這是一種極大的簡化。在現實中,許多單字會共同出現,且許多企業行為之間也存在關聯性。
然而,正是這個選擇讓該模型變得非常輕量。它無需學習錯綜複雜的依賴關係網絡,只需估算更簡單的機率,並將其高效地組合起來。
實用準則:朴素貝葉斯模型並不會試圖重構整個世界。它旨在憑藉少量假設,以極快的速度做出有用的決策。
誤解往往由此而生。許多人讀到「天真的假設」,便斷定這是「弱模型」。事實並非如此。如果簡化能抓住決策任務中關鍵的要素,那麼模型即使經過大幅簡化,仍能保持其競爭力。
2004年,一項理論分析揭示了「天真貝葉斯分類器」之所以有效,儘管其基於獨立性假設,仍具備充分的理論依據;該分析同時解釋了為何其能比邏輯迴歸更快速地達到漸近誤差。在相同的應用領域中,如垃圾郵件過濾,其準確度可超過99%,並能處理數百萬份文件,詳情請參閱「天真貝葉斯分類器」的專文介紹。
這一點對企業受眾而言至關重要。演算法的價值不僅在於最終分數,更在於其能否快速訓練、適應大規模資料集,並保持可解釋性。
當您面對分散的文本、類別、標籤或信號時,朴素貝葉斯分類器之所以能有效運作,是因為:
不過有兩點需要留意。
正因如此,朴素貝葉斯應被視為處理快速分類問題時的一種極其有效的工具,而非萬能的魔法棒。然而,在許多實際應用情境中,它仍是起步時最明智的選擇之一。
一個常見的錯誤是將「朴素貝葉斯」視為在任何情況下都完全相同的單一模型。事實上,它存在多種變體,分別針對不同的資料類型而設計。
正確的選擇取決於您手頭數據的格式。如果選錯變體,模型雖然仍能產生預測結果,但其推論方式未必最適合您的問題。
當特徵為連續型時,高斯式朴素貝葉斯(Gaussian Naive Bayes)是最合適的變體。例如:交易平均金額、客戶年齡、兩次購買之間的平均間隔時間、單位利潤或收據金額。
在此,該模型假設每個區間內的數值均遵循高斯分佈。你無需將此視為一種學術上的限制。只需記住這個實務概念即可:對於每個區間,模型會估算一個典型中心值和一個標準差。
當您想對以下類型的案例進行分類時,此方法會很有幫助:
在一項使用類似義大利電子商務數據集的 scikit-learn 基準測試中,一個朴素貝葉斯模型在 1000 個樣本下達到了 95% 的準確度,且訓練時間比邏輯迴歸快了15%。 如 Jake VanderPlas 在《深入探討朴素貝葉斯分類》一章中所述,得益於閉式訓練,在標準 CPU 上,兩者的訓練時間分別為0.01 秒與 0.1 秒。
對企業而言,重點不在於小數點。重點在於,這種變體無需耗費大量時間進行訓練,也無需繁重的基礎設施,便能產生良好的效果。
若您處理的是文本、工單、評論或留言,多項式朴素貝葉斯(Multinomial Naive Bayes)通常是理所當然的選擇。在此情境下,特徵值即為計數或頻率。實際上,該模型會觀察單詞或術語出現的次數。
這正是典型的:
它之所以能有效運作,原因非常具體。在企業文件中,詞彙量雖大,但每份文件僅包含可能詞彙中的一小部分。資料呈現分散的狀態。多項式朴素貝葉斯(Multinomial Naive Bayes)正擅長處理這類結構。
根據 GeeksforGeeks 關於「天真貝葉斯分類器」的指南所述,在一項針對10 萬則標註了情緒標籤的義大利推文所進行的研究中,多項式天真貝葉斯分類器(Multinomial Naive Bayes)達到了0.88 的 F1 分數,且相較於支援向量機(SVM),其運算速度提升了 10 倍。
為了方便記憶,不妨這樣想:如果你的資料就像一份充滿計數詞彙的文件,那麼多項式模型幾乎總是首選的測試方法。
如果貴公司需要處理大量文本,問題不僅在於「模型的準確度有多高?」,更在於「它能在不拖慢團隊進度的情況下,處理多少請求?」
伯努利朴素貝葉斯模型處理的是二元特徵。它不計算某個特徵出現的次數,而是僅考量該特徵是否存在。
當某個屬性的存在比其出現頻率更重要時,此變體便派上用場。以下是一些企業實例:
當您希望將複雜的現象轉化為易於監測的「是/否」指標時,這種邏輯非常實用。例如在情緒分析中,負面詞彙的出現本身可能比其重複次數更為重要。
伯努利分布並非比多項式分布「較不成熟」。當資料描述的是「有」或「無」時,它只是更為合適。兩者之間的差異在理論上雖微,但在結果上卻有顯著差異。
| 變體 | 理想資料類型 | 企業用例範例 |
|---|---|---|
| 高斯式朴素貝葉斯 | 連續資料 | 根據金額、頻率及平均值,按風險對交易進行分類 |
| 多項式朴素貝葉斯 | 文本、統計數據、頻率 | 根據情緒或類別分析客戶評論與服務單 |
| 伯努利-朴素貝葉斯 | 二進位資料、有/無 | 評估合規性、支援或產品使用方面的「是/否」訊號 |
要做出明智的選擇,請遵循一個簡單的原則:
許多團隊之所以陷入僵局,是因為他們總在尋找絕對「最佳」的模型。幾乎在所有情況下,正確的選擇都是最符合該類資料特性的模型。
好消息是,將朴素貝葉斯模型付諸實踐並不需要進行龐大的專案。即使只是個可讀性高的原型,也能讓人理解模型的運作邏輯以及它需要哪些資料。

分類器的建立通常都需經過四個步驟。
資料準備
您需要收集已標註的歷史範例。若您正在進行評論分類,則需要已標記為正面或負面的文本;若您正在分析營運風險,則需要結果已知的過往案例。
模型的訓練該模型會分析資料並估算有用的機率。在朴素貝葉斯分類器中,此步驟相當迅速,因為訓練過程不需要進行特別繁重的優化。
新案例預測
輸入新記錄,模型將為其分配類別。例如「垃圾郵件」、「非垃圾郵件」、「高風險客戶」、「穩定客戶」。
評估:在獨立的測試集上,將預測結果與實際結果進行比對。這不僅是檢視模型是否有效,更是觀察其出錯的方式。
若您想進一步了解預測方法的整體概況,這篇關於機器學習演算法的概覽,有助於將「朴素貝葉斯」置於更廣泛的方法體系中加以理解。
為了讓這個過程更具體,這裡提供一個使用 scikit-learn 的簡易範例。無需以開發者的角度來閱讀它,只要理解流程即可。
# 導入主要工具from sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_splitfrom sklearn.naive_bayes import GaussianNBfrom sklearn.metrics import accuracy_score# 載入範例資料集X, y = load_iris(return_X_y=True)# 將資料分割為訓練集與測試集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 建立模型model = GaussianNB()# 根據歷史資料訓練模型model.fit(X_train, y_train)# 對未見過的資料進行預測y_pred = model.predict(X_test)# 測量準確度print(accuracy_score(y_test, y_pred))這段文字所傳達的意義,遠比表面上看起來的更為深遠。
GaussianNB() 請選擇連續型資料的選項。fit() 這就是模型學習的時刻。predict() 將所學付諸實踐。accuracy_score() 請檢查整體上共有多少項分類是正確的。對於文字資料,處理流程大致相同,但在套用模型之前,必須先將文字轉換為數字。實際上,就是將文字轉換為分類器可用的特徵。
在初步瀏覽程式碼後,查看該機制的視覺化說明可能會有所幫助。
第一個模型並非用來證明完美,而是用來回答三個實務問題。
這正是朴素貝葉斯演算法的優勢所在。你可以迅速建立一個穩固的基準。以此為基礎,你便能判斷是否值得讓專案變得更複雜,抑或一個簡單的解決方案已經創造出價值。
一個分類模型的優劣,不能僅憑「看似有效」來評判。應根據其出錯的方式,以及這些錯誤對業務造成的影響程度來評判。

準確度是最直觀的指標。它顯示總預測中正確的數量。雖然有其用處,但若僅憑此指標,可能會產生誤導。
如果在一百筆交易中,真正可疑的僅有寥寥數筆,那麼一個將幾乎所有交易都歸類為正常的模型,雖然在準確度方面看似表現良好,但在真正需要的地方卻可能表現不佳。
要理解這一點,不妨想像一張漁網。
在商界,這種區別至關重要。
一個好的模型並非指整體上出錯較少的模型,而是指其出錯對您的流程造成的損失最小的模型。
若想更深入了解演算法如何從歷史資料中學習,以及為何訓練品質會影響最終結果,您可以閱讀這篇關於演算法訓練原理的深度解析。
朴素貝葉斯模型雖然簡單,但對某些實務上的錯誤卻毫不寬容。
第一個錯誤:忽略零頻率問題。
如果某個詞彙或數值在某個類別的訓練資料中從未出現,其機率可能會降至零,從而影響計算結果。因此,通常會使用拉普拉斯平滑法,在計數結果中加入微小的修正值。
第二個錯誤:使用高度相關的特徵。
如果兩欄所呈現的資訊幾乎相同,模型可能會高估該訊號。模型無法「理解」這兩項特徵幾乎是重複的。
第三個錯誤:過度依賴原始機率。
雖然朴素貝葉斯(Naive Bayes)通常能進行良好的分類,但其機率值可能過於絕對。對企業而言,這意味著排名結果雖具參考價值,但對機率的具體數值則應謹慎解讀。
為降低這些風險,建議:
當你不再將朴素貝葉斯分類器視為一項數學練習,而是開始將其用作決策優先順序的驅動工具時,其真正的價值便會顯現。在企業中,精準的分類幾乎總是意味著更明智的決策。

試想一個財務團隊,他們分析交易流、操作說明及歷史數據。每一行不僅僅是一筆記錄,更是一項潛在的決策:放行、深入調查、阻止,或是轉交給分析師。
透過朴素貝葉斯(Naive Bayes),您可以將不同類型的指標整合到單一分類中。有些是數值的,有些是二進位的,有些則是文字型的。該模型有助於辨別哪些案例最接近已觀察到的模式,例如正常或異常的情況。
其實際效益有兩方面:
在受規範的環境中,它並未取代人類的判斷,而是對其進行系統化整理。而在高處理量的運作流程中,這確實能帶來實質性的差異。
在行銷領域中,分類通常意味著將每位客戶歸入特定的目標群組。例如:忠實客戶、價格敏感型客戶、流失風險客戶、促銷反應型客戶,以及休眠客戶。
在此,朴素貝葉斯模型之所以有用,是因為它能夠快速整合各種不同的訊號:
一支 CRM 團隊不需要一套完美的人類行為理論。它需要的是一套足夠精準的客群區隔,以便採取合理的行動。例如調整訊息內容、聯繫頻率或優惠類型。
當一個模型能協助為合適的客戶選擇下一個訊息時,它便已創造出營運價值。
在零售與電子商務領域,分類機制支援著看似不同卻遵循相同邏輯的活動:將混亂化為秩序。
您可以根據產品的銷售表現進行分類。您可以閱讀評論和客服單,以了解哪些類別存在銷售阻礙。您可以識別需求模式,協助團隊更清晰地規劃促銷活動和庫存。
在此類環境中,資料往往數量龐大、類型繁多,且未必完美無缺。正因如此,一個快速、可擴展且易於理解的模型便顯得極具價值。這並非因為它最為耀眼,而是因為它能無縫融入工作流程,且不會造成任何延遲。
若想了解分析方法如何應用於商業實務並在具體專案中落實,不妨參考這些案例研究。
理解朴素貝葉斯模型是有幫助的。但在企業環境中妥善地將其實作,則是另一回事。
問題幾乎從來不只是演算法本身。真正的挑戰在於模型的建構。你必須整合各種資料來源、處理缺失欄位、預處理文本、更新標籤、檢查輸出品質,並將結果以決策者能理解的方式呈現。
對中小企業而言,這一步驟往往是關鍵所在。這並非因為對人工智慧缺乏興趣,而是因為團隊的時間有限,而營運上的優先事項不容拖延。
在此情境下,採用能化解技術複雜性的平台是明智之舉。透過人工智慧驅動的解決方案,可將原始數據轉化為易於理解的洞察,無需企業自行編寫程式碼、挑選函式庫或手動維護資料處理流程。
像ELECTE 這樣的平台——一個專為中小企業設計的人工智慧驅動數據分析平台——讓使用者無需具備機器學習的專業知識,也能輕鬆運用諸如「天真貝葉斯分類器」等方法。其優勢不僅在於速度,更在於能減少數據與決策之間的摩擦。
當自動化運作良好時,團隊就不再以公式化思維來思考,而是轉向提出有用的問題:
這也是越來越多企業尋求工具,以協助判斷 AI 生成的內容可靠性,以及內部流程中流傳的文字訊號是否可信的原因。在此背景下,參考一份關於義大利語 AI 偵測工具的指南或許有所助益,特別是當您的團隊主要處理文件、內容及語言校對工作時。
實際上,其中的差異很簡單。與其處理零散的技術環節,不如將焦點放在企業成果上。而這正是人工智慧真正具備實用價值之處,而不僅僅是令人感興趣。
朴素貝葉斯分類器向我們傳達了一個重要教訓:在分析領域中,妥善運用的簡單方法,往往能勝過處理不當的複雜方法。
憑藉直觀的機率基礎、良好的可擴展性以及極具實務價值的應用案例,這種方法仍是企業進行資訊分類、解讀隱藏訊號並更自信地採取行動的可靠工具。無需成為機器學習專家,也能理解其價值。關鍵在於將數學與營運決策相結合。
當這層關聯性變得清晰時,人工智慧便不再僅是技術議題,而是轉變為組織優勢。正是在這個時刻,預測才開始產生實質影響。
若想將零散的數據轉化為清晰的洞察,不妨試試 ELECTE。該平台協助中小企業整合數據來源、自動化分析流程,並生成實用的報告與預測,助您做出更迅速且明智的決策。

.svg)
.svg)
.svg)






